Download

1 / 48
480 likes | 499 Views
This PhD proposal aims to study errors in web-based applications and improve the state of web testing techniques through targeted guidelines for high severity faults and automation in regression testing.

E N D
An Exploration of Errors in Web-based Applications in the Contextof Web-based Application Testing PhD Proposal Kinga Dobolyi May 2009
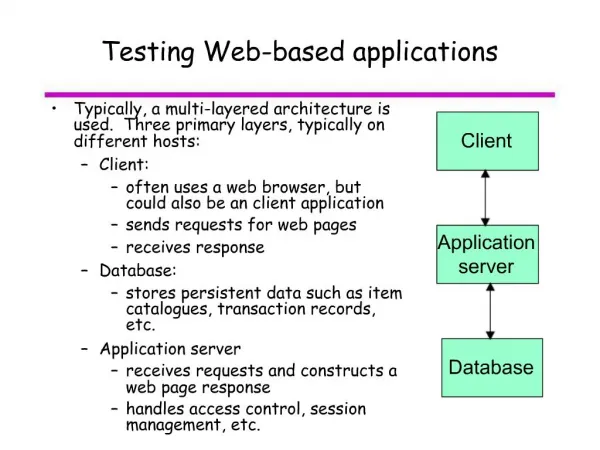
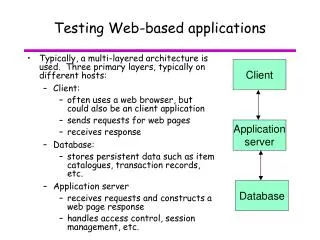
What is going on • Problem: faults in web-based applications cause losses of revenue, and they are hard to test • Approach: study errors in web-based applications in the context of web testing • Solution: improve the state of the art in web testing techniques through guidelines targeted at high severity faults and automation and precision in regression testing
Outline • Introduction and motivation • Thesis statement • Background • Goals and approaches • Preliminary work • Expected contributions
Motivation • Testing of web-based applications in particular deserves further examination due to economic considerations: • Monetary throughput: Backbone of e-commerce and communications businesses • Customers: low customer loyalty • Development: Companies are choosing not to test due to resource constraints
Motivation: e-commerce • Internet usage: 73% of people in the US in 2008 • Browsers are dominant application • $204 billion in Internet retail sales annually • Global online B2B transactions total several $trillions annually • One hour of downtime at Amazon.com cost $1.5 million dollars • 70% of major online sites exhibit user-visible failures
Motivation: customers • Customer loyalty is notoriously low • Determined by the usability of the application [Offutt 2002] • Freedom and options
Motivation: customers • Lesson learned: web-based applications need to be well-designed and well tested • Are they?
Motivation: development • Technology challenges: • Heterogeneous, opaque components • Dynamic page content generation • Persistent state operated upon by concurrent, global users around the clock
Motivation: development • Web-based applications are often not tested • Enormous pressure to change • Short delivery times, high developer turnover rates, and quickly evolving user needs • No formal process model
Motivation: summary • Problem: faults in web-based applications cause losses of revenue, and they are hard to test • Approach: study errors in web-based applications in the context of web application testing • Solution: improve the state of the art in web testing techniques through guidelines targeted at high severity faults and automation and precision in regression testing
Thesis statement • Hypothesis: web-based applications have special properties that can be exploited to build tools and models that improve the current state of web application testing and development: • Tend to fail in predictable and similar ways • Human centric definition of acceptability
Thesis statement • Problem: faults in web-based applications cause losses of revenue, and they are hard to test • Approach: study errors in web-based applications in the context of web testing • Solution: improve the state of the art in web testing techniques through guidelines targeted at high severity faults and automation and precision in regression testing
Background: testing techniques • Non-functional (static) validation • Server load testing • Link testing • HTML/spelling validation • Modeling approaches • Capture-replay • User session-based testing
Background: oracles • Oracles (oracle-comparator) 1 <<P>The same table could be indented. 2 <<TABLEborder="1"> 3 --- 4 ><p>The same table could be indented.</p> 5 ><tableborder="1"summary=""> • False positives from diff-like tools • Want precise comparators
Background: automation • Automation • Test case generation: VeriWeb, PHP • Test case replay • URL + post-data • Failure detection
Background: metrics • How do we measure success? • Code coverage • Fault seeding • Human • Automatic • Cost • How do we know these are indicative of the real world?
Background: fault definition • Defining an error: • “the inability to obtain and deliver information, such as documents or computational results, requested by web users.” [Ma & Tian 2003] • Fault taxonomies • Figure from [Marchetto et al 2007]
Background: challenges • Functional validation remains a challenge • Regression testing should be more precise and automatic • We do not know if test suite efficacy metrics are indicative of the real world • We should examine the severity of uncovered faults
Goals and approaches • Problem: faults in web-based applications cause losses of revenue, and they are hard to test • Approach: study errors in web-based applications in the context of web testing • Solution: improve the state of the art in web testing techniques through guidelines targeted at high severity faults and automation and precision in regression testing
Goals and approaches • I propose to: • Model errors in web-based applications • Identify them more accurately • Automate the oracle-comparator process • Make web testing more cost-effective • Devise a model of fault severity that will guide test case design, selection, and prioritization • Validate or refute the current underlying assumption that all faults are equally severe in fault-based testing
Goals and approaches: Goals • Reduce the cost of regression testing web-based applications • Use special structure of web-based application output to precisely identify errors • Automate web-based application regression testing • Unrelated web-based applications tend to fail in similar ways • Understand customer-perceived severities of web application errors.
Goals and approaches: Goals • Formally ground the current state of industrial practice • Validate or refute fault injection as a standard for measuring web application test suite quality • Understand how to avoid high-severity faults during web application design and development • Reduce the cost of regression testing web applications by exposing high-severity faults • Test case design, selection, and prioritization (test suite reduction)
Goals and approaches: Step 1 – oracle-comparator • Construct a precise oracle-comparator that uses the tree-structured nature of XML/HTML output and other features • Model errors on a per-project basis • Semantic distance metric to reduce false positives
Goals and approaches: Step 2 – automated oracle-comparator • Exploit the similar way in which web applications fail to avoid the need for human annotations in training a precise oracle-comparator • Train a precise oracle-comparator on data from other, unrelated web applications • Use fault injection to improve the results when necessary
Goals and approaches: Step 3 – human study • Conduct a human study of real-world fault severity to identify a model of fault severity • Severities different than self-reported in bug repositories • Screenshots of current-next idiom • Also survey developers
Goals and approaches: Step 4 – fault seeding validation • Compare the severities of real-world faults to seeded faults using human data (validate fault seeding) • The severities of seeded errors have uniform distributions? • The severity distribution of seeded errors matches the distribution of real-world errors, according to the results of the survey from Step 3?
Goals and approaches: Step 5 – software engineering guidelines • Identify underlying technologies and methodologies that correlate with high-severity faults • As an alternative to testing • Tie high severity errors to underlying code, components, programming languages, and software engineering practices
Goals and approaches: Step 6 – testing techniques • Identify testing techniques to maximize return on investment by targeting high-severity faults • Introduce a new metric for the (web application) test suite reduction research community
Preliminary Work: Step 1 • Step 1: Construct a precise oracle-comparator using tree structured XML/HTML output and other features • Multiple versions of 10 open-source benchmarks • 7154 pairs of oracle- testcase output, 919 of which labeled as “possibly an error”
Preliminary Work: Step 1 • Evaluation: F-measure (precision and recall) using our model
Preliminary Work: Step 1 • Longitudinal study to measure effort saved • Calculate cost of looking : cost of missing • Low ratio means we are saving effort
Preliminary Work: Step 2 • Step 2: Exploit similarities in web application failures to avoid human annotations when training a precise oracle-comparator • Same setup as Step 1 • Use existing, annotated pairs of test-oracle output from unrelated applications to train a comparator for the application at test
Preliminary Work: Step 2 • Evaluation: measure precision and recall
Preliminary Work: Step 2 • Use fault seeding to introduce project-specific faults into the training data set
Preliminary Work: Step 3 • Step 3: Model real-world fault severity based on a human study. • Collect 400 real-world faults • Evaluation: have subjects use the model to classify faults
Preliminary Work: Step 4 • Step 4: Compare the severities of real-world faults to seeded faults using human data. • Test same human subjects with 200 + 200 manually-injected and automatically-injected faults • Conduct a survey of developers for fault severity
Preliminary Work: Step 5 • Step 5: Identify technologies and methodologies that correlate with high-severity faults • Do high severities correlate with: • Programming Language • Level in three-tier architecture • COTS component • User error (usability issue) • Type of error (business logic, resource allocation, syntax error, etc) • Fault taxonomies (existing) • Surface features of visible output: white screens, stack traces, misspellings, formatting errors • Evaluation: developer survey (time permitting)
Preliminary Work: Step 6 • Step 6: Identify testing techniques to target high-severity faults • Targets testing • Assign a testcase a severity rating a priori • Evaluation: compare the severity of faults exposed with our technique versus other test suite reduction approaches
Expected Contributions • Problem: faults in web-based applications cause losses of revenue, and they are hard to test • Approach: study errors in web-based applications in the context of web testing • Solution: improve the state of the art in web testing techniques through guidelines targeted at high severity faults and automation and precision in regression testing
Expected Contributions • Reduce the cost of regression testing by constructing a precise oracle-comparator • Develop a model of customer-perceived severities of web application faults • Validate or refute fault injection as a standard for measuring web application test suite quality • Propose new software engineering guidelines for web application development and testing
Original Contributions • Fault Severity Model • Severity has not been studied in this domain, and customers are an integral part of these applications • Providing a new metric to the research community • Validate/refute fault seeding • Precise-oracle comparators • First to use different versions of benchmarks • Can be completely automated • XML and HTML
Expected Impact • Fault Severity Model • Can be applied to testing techniques in this field to make them financially feasible for developers • Change the way in which test suite efficacy is measured • Potentially impact web site design as usability issues may become more evident • Precise oracle-comparator • Automation makes it much more feasible for adoption than existing techniques • Potentially allow companies to conduct regression testing if they were not testing beforehand
Timeline • Steps 1 and 2: precise comparators • Completed, 2 papers under submission • Steps 3 and 4: human study • Data collection completed, analysis under way for submission of 1 paper • Expected completion by September • Step 5: software engineering guidelines • Expected completion by October • Expected 0.5 paper • Step 6: testing according to fault model • Expected completion by February • Expected 1 paper