Download

1 / 12
120 likes | 132 Views
Time Series Bitmap Experiments. This file contains full color, large scale versions of the experiments shown in the paper, and additional experiments which were omitted because of space constraints Note that in every case, all the data is freely available.

E N D
Time Series Bitmap Experiments • This file contains full color, large scale versions of the experiments shown in the paper, and additional experiments which were omitted because of space constraints • Note that in every case, all the data is freely available
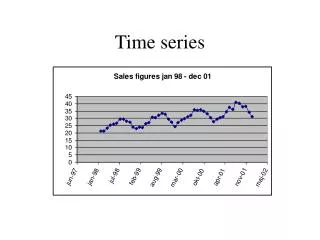
Dataset 1: Heterogeneous Data, Part 1 The clustering achieved on 15 pairs of samples from 15 diverse datasets. The red lines in the dendrogram draw attention to objectively incorrect subtrees Parameters Level 3 N = 100 n = 10 24 23 25 26 20 19 16 15 14 13 12 11 10 9 Data Key 8 1 MotorCurrent: 2 MotorCurrent: 3 Video Surveillance: Ann, gun 4 Video Surveillance: Ann, no gun 5 Video Surveillance: Eamonn, gun 6 Video Surveillance: Eamonn, no gun 7 Power Demand: Jan-March (Italian) 8 Power Demand: April-June (Italian) 9 Great Lakes (Erie) 10 Great Lakes (Ontario) 11 Buoy Sensor: North Salinity 12 Buoy Sensor East Salinity 13 Koski ECG: slow 1 14 Koski ECG: slow 2 15 Koski ECG: fast 1 16 Koski ECG: fast 2 17 Exchange Rate: Swiss Franc 18 Exchange Rate: German Mark 19 Furnace: heating input 20 Furnace: cooling input 21 Reel 2: angular speed 22 Reel 2: tension 23 Balloon1 24 Balloon2 (lagged) 25 Evaporator: feed flow 26 Evaporator: vapor flow 27 Shuttle Inertia Sensor X 28 Shuttle Inertia Sensor X 29 Shuttle Inertia Sensor Z 30 Shuttle Inertia Sensor Z 7 22 21 6 5 4 3 30 29 28 27 18 17 2 1 Data is in ASCII file “time_series_bitmap_1”
Dataset 1: Heterogeneous Data, Part 2 If we do the clustering with only level 2 information, the clustering is very slightly worse, but still quite robust considering that we are only using 1.6% of the information available in the time series Parameters Level 2 N = 100 n = 10 24 23 25 20 26 19 16 15 14 13 8 7 27 28 Data Key 18 1 MotorCurrent: 2 MotorCurrent: 3 Video Surveillance: Ann, gun 4 Video Surveillance: Ann, no gun 5 Video Surveillance: Eamonn, gun 6 Video Surveillance: Eamonn, no gun 7 Power Demand: Jan-March (Italian) 8 Power Demand: April-June (Italian) 9 Great Lakes (Erie) 10 Great Lakes (Ontario) 11 Buoy Sensor: North Salinity 12 Buoy Sensor East Salinity 13 Koski ECG: slow 1 14 Koski ECG: slow 2 15 Koski ECG: fast 1 16 Koski ECG: fast 2 17 Exchange Rate: Swiss Franc 18 Exchange Rate: German Mark 19 Furnace: heating input 20 Furnace: cooling input 21 Reel 2: angular speed 22 Reel 2: tension 23 Balloon1 24 Balloon2 (lagged) 25 Evaporator: feed flow 26 Evaporator: vapor flow 27 Shuttle Inertia Sensor X 28 Shuttle Inertia Sensor X 29 Shuttle Inertia Sensor Z 30 Shuttle Inertia Sensor Z 17 12 11 10 9 4 3 6 5 22 21 30 29 2 1
24 24 23 23 25 25 26 26 20 20 19 19 16 16 15 15 14 14 13 13 12 8 11 7 10 6 9 5 8 22 7 21 22 12 21 11 6 10 5 9 4 4 3 3 30 28 29 27 28 29 27 30 18 18 17 17 2 2 1 1 Dataset 1: Heterogeneous Data, Part 3 Changing the parameters by up to 50% either way has little effect on the quality of the clustering. Here are some random examples 24 23 25 26 20 19 8 7 16 15 14 13 6 Data Key 5 4 1 MotorCurrent: 2 MotorCurrent: 3 Video Surveillance: Ann, gun 4 Video Surveillance: Ann, no gun 5 Video Surveillance: Eamonn, gun 6 Video Surveillance: Eamonn, no gun 7 Power Demand: Jan-March (Italian) 8 Power Demand: April-June (Italian) 9 Great Lakes (Erie) 10 Great Lakes (Ontario) 11 Buoy Sensor: North Salinity 12 Buoy Sensor East Salinity 13 Koski ECG: slow 1 14 Koski ECG: slow 2 15 Koski ECG: fast 1 16 Koski ECG: fast 2 17 Exchange Rate: Swiss Franc 18 Exchange Rate: German Mark 19 Furnace: heating input 20 Furnace: cooling input 21 Reel 2: angular speed 22 Reel 2: tension 23 Balloon1 24 Balloon2 (lagged) 25 Evaporator: feed flow 26 Evaporator: vapor flow 27 Shuttle Inertia Sensor X 28 Shuttle Inertia Sensor X 29 Shuttle Inertia Sensor Z 30 Shuttle Inertia Sensor Z 3 22 21 12 11 10 9 30 29 28 27 18 Parameters Level 3 N = 64 n = 8 Parameters Level 3 N = 77 n = 11 Parameters Level 3 N = 54 n = 9 17 2 1
25 30 20 29 26 27 24 24 23 23 19 26 14 25 15 20 16 12 13 8 11 19 12 9 10 11 9 7 8 16 7 15 4 14 3 13 30 21 29 10 22 4 21 3 6 22 5 6 27 5 18 2 17 28 2 18 28 17 1 1 Dataset 1: Heterogeneous Data, Part 4 We compared our approach to a Markov model based approach and a ARIMA based approach. For both competitors we spent one hour of human time trying to find the best parameters Segmental Markov model [1] Mixtures of ARMA models [2] 24 23 25 26 20 19 16 15 14 13 12 11 10 Data Key 9 8 1 MotorCurrent: 2 MotorCurrent: 3 Video Surveillance: Ann, gun 4 Video Surveillance: Ann, no gun 5 Video Surveillance: Eamonn, gun 6 Video Surveillance: Eamonn, no gun 7 Power Demand: Jan-March (Italian) 8 Power Demand: April-June (Italian) 9 Great Lakes (Erie) 10 Great Lakes (Ontario) 11 Buoy Sensor: North Salinity 12 Buoy Sensor East Salinity 13 Koski ECG: slow 1 14 Koski ECG: slow 2 15 Koski ECG: fast 1 16 Koski ECG: fast 2 17 Exchange Rate: Swiss Franc 18 Exchange Rate: German Mark 19 Furnace: heating input 20 Furnace: cooling input 21 Reel 2: angular speed 22 Reel 2: tension 23 Balloon1 24 Balloon2 (lagged) 25 Evaporator: feed flow 26 Evaporator: vapor flow 27 Shuttle Inertia Sensor X 28 Shuttle Inertia Sensor X 29 Shuttle Inertia Sensor Z 30 Shuttle Inertia Sensor Z 7 22 21 6 5 4 3 30 29 28 27 Parameters Level 3 N = 100 n = 10 18 17 2 1
Dataset 2: Homogenous Data, Part 1 Here we cluster 5 randomly chosen subsections from 4 different ECG datasets 20 19 17 18 16 8 7 10 9 6 15 14 Data Key 12 Cluster 1 (datasets 1 ~ 5): BIDMC Congestive Heart Failure Database (chfdb): record chf02 Start times at 0, 82, 150, 200, 250, respectively Cluster 2 (datasets 6 ~ 10): BIDMC Congestive Heart Failure Database (chfdb): record chf15 Start times at 0, 82, 150, 200, 250, respectively Cluster 3 (datasets 11 ~ 15): Long Term ST Database (ltstdb): record 20021 Start times at 0, 50, 100, 150, 200, respectively Cluster 4 (datasets 16 ~ 20): MIT-BIH Noise Stress Test Database (nstdb): record 118e6 Start times at 0, 50, 100, 150, 200, respectively 13 11 5 4 3 Parameters Level 3 N = 50 n = 10 2 1
Dataset 2: Homogenous Data, Part 2 The bitmap approach is defined (and very robust) when the time series are of different lengths 8 7 10 9 6 17 19 18 20 16 15 14 12 13 11 4 3 2 5 1
Dataset 3: MIT ECG Arrhythmia Data Part 1 Segmental Markov model [1] 51 54 In Ge and Smyth 2000, this dataset was explored with segmental hidden Markov models. After they careful adjusted the parameters they reported 98% classification accuracy. Using time series bitmap with virtually any parameter settings, we get perfect classifications and clustering. We can get perfect classifications using one nearest neighbor classification, or we can project the data into 2 dimensional space (see next slide) and get perfect accuracy using a simple linear classifier, a decision tree or SVD. (Dataset donated by Padhraic Smyth and Seyoung Kim) 47 47 54 49 33 48 55 46 43 51 38 42 45 45 42 35 40 53 32 37 56 33 49 43 50 31 48 41 52 39 46 34 53 30 44 56 35 52 37 44 31 36 39 40 30 50 41 38 34 32 23 55 18 29 11 4 21 21 13 16 6 11 36 10 29 6 22 20 8 23 5 22 24 18 17 17 27 19 14 5 26 7 20 26 9 3 16 2 4 27 25 13 12 15 10 12 Parameters Level 1 N = 60 n = 12 3 8 15 28 19 14 7 24 28 9 2 25 1 1
Dataset 3: MIT ECG Arrhythmia Data Part 2 39 21 30 41 34 56 4 31 52 11 17 20 29 44 16 18 55 35 6 1 23 45 32 22 5 25 50 38 28 27 19 14 13 36 42 10 24 53 43 40 15 9 8 12 26 2 3 46 49 7 48 37 33 0.55 51 0.5 0.45 54 Parameters Level 1 N = 60 n = 12 0.4 47 0.35
Dataset 4: MotorCurrent Part 1 Euclidean Distance 28 29 The Bitmap approach is completely phase independent, which may be useful for certain datasets. Consider the Motorcurrent dataset (Donated by Richard J. Povinelli). Here the problem is to distinguish between normal motor operations and “broken connectors”. If we attempt to cluster this dataset with Euclidean distance or DTW, the fact that the sample are out of phase confuses the algorithm (far left), however the bitmap approach can easily produce objectively correct clusterings. In this problem the time series bitmaps are very very similar between classes, and humans will find it hard to distinguish them. Nevertheless, there is enough information to achieve correct clusterings 33 28 38 35 23 33 13 31 8 39 18 26 3 37 30 24 35 22 40 30 25 40 15 27 10 38 20 25 5 36 32 23 27 32 37 34 22 21 7 9 12 19 17 17 2 4 34 2 29 20 39 13 24 15 9 6 14 12 19 10 4 8 26 11 31 7 36 5 21 18 11 16 6 3 16 14 1 1
20 More information about the Kalpakis_ECG demonstration 0 100 200 300 400 500 ventricular depolarization “plateau” stage repolarization initial rapid repolarization recovery phase 0 100 200 300 400 500 27 26 A clustering of a subset of the Kalpakis_ECG dataset. Note that while ECGs have incredible variability, the 5 non-ECGs clearly stand out in the bitmap representation. 24 15 31 33 This drawing shows the correlation of muscle depolarization and ECG tracings at corresponding times. Phase 0 denotes ventricular depolarization. This is seen on the ECG as the beginning of the QRS complex. Phase 1 denotes the initial rapid repolarization due to closing of fast sodium channels. This is seen as the large drop in mV on the ECG. Phase 2 represents the plateau stage during which inflow and outflow currents are balanced. The ECG returns to baseline.Phase 3 is repolarization. Potassium channels open and calcium closes. The ECG shows the repolarizing T wave.Phase 4 is the recover phase. Both the muscle tracing and ECG return to baseline levels 16 34 36 38 32 21 30 10 7 18 6 42 40 17 25 12 8 3 14 11 39 13 35 5 4 2 48 46 47 45 44 28 29 41 19 37 23 22 43 9 1
Fusion of ventricular and normal beat MITdb/210 Dataset Anomaly Score 0:19 0:21 0:23 0:25 0:27 Anomaly detection http://www.physionet.org/cgi-bin/chart?database=mitdb&record=210&annotator=atr&tstart=21&width=small