Download

1 / 11
110 likes | 529 Views
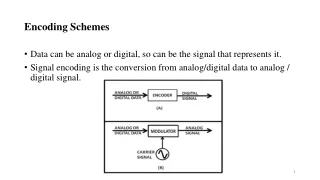
Encoding Schemes. Encoding methods : a method of encoding at binary level to ensure identification and the use of a mixture of different character sets compatibility consideration and usually should be compatible with ASCII save space and multiple codesets to be used on the same system

E N D
Encoding Schemes • Encoding methods: a method of encoding at binary level to ensure identification and the use of a mixture of different character sets • compatibility consideration and usually should be compatible with ASCII • save space and multiple codesets to be used on the same system • Clear whether the codeset is for internal code/exchange code /processing code • High-bit on scheme The most significant bit of the first byte of the character is set to 1 to indicate the beginning of a Chinese character • Examples: GB, Big5
GuoBiao (國標) :GB Series • PRC standard (also used in Singapore) G0: GB2312-80, 6,763 Han char. G1: GB12345-90, traditional counterpart GBK: Extension to G0 to support Unicode characters • GB2312-80 is the most commonly used codeset Represents simplified characters (i.e. has representation ambiguities with some internal codes of traditional characters e.g. Big5) • Code table: has 94 rows x 94 column, Total 8,836 code-points (code space) • Code range shown in code table: 0x21\21-0x7E\7E • In high-bit on scheme in most systems(8 byte encoding), the code range is 0xA1\A1 - 0xFE\FE
Character subsets(rows): • 1: Special symbols (math, etc. e.g. , 【】 ) • 2: Paragraph numbers (e.g. 15.(16). ) • 3: ASCII full characters(全角 ) characters -> ASCII equivalent characters (e.g. A..Z) • 4: Hiragana, 5: Katakana • 6: Greek (48), 7: Cyrillic( Russian) • 8: Pinyin (Romanized Pinyin vows and Zhuyin symbols) • 9:Graphic for box and table drawing • 16-55: Level 1 (0xb0-0xd7) 3,755 Hanzi characters (ordered by pinyin) • 56- 87: Level 2 (0xd8-0xf7) 3,008 Hanzi characters (ordered by radical, stroke number) • 88- 94:Not defined areas: • For future extension(103 characters were later defined in rows 88-89, and 161 graphic symbols from row 90 and on ) • User defined area • Full-width characters vs. half-width characters • Why are there some undefined codepoints(not like in ASCII which is completed full)?
Big5 (大五) • De facto standard in Taiwan and HK (commonly for PC) • High-bit on scheme • Row-cell: • Defined Range: First Byte (0xA1-FE) and Second Byte (0x40-7E,A1-FE), two blocks • Standard code space: 94 * (94+63)= 14,758 code points • Character Subsets • punctuation symbols (A140-A24e) • units (A24F-A261) • graphic symbols for box and tables (A262-A2AE) • numerals (A2AF-A2CE) • Latin letters (A2CF- A343) • Greek letters (A344-A373) • Zhuyin (A374-A3BF)
Hanzi • Plane 1 (A440-C67E): Frequently used (5,401) • Plane 2 (C940-F9D5): Less frequently used (7,652) • Contains some simplified writing characters and variants台(臺)灣 • Contains some dialect-specific characters • Hiragana (C6A1-C6F7) and Katakana (C6F8-C7B0) • Cyrillic letters (C7B1-C7E8) • Numbers (C7E9-C7FC) • Extension to Big5(called Etan Big5): 8140-A0FE • additional 32*157=5,024 code points • Total of 14,758 + 5,024 = 19,782 • User Defined areas: • FA40-FEFE(UDA 1)(5 rows) • 8E40 - A0FE(UDA 2)(19 rows) • 8140 - 8DFE(UDA 3)(13 rows) • Vendor defined areas (VDA): VDA1: C6A1 – C8FE,VDA2: F9D6 – F9FE
HKSCS(香港增補字符集) UDA3 (2,041 codepoints) 8140 – 8DFE • Extension to Etan Big5 using UDAs • Big5 UDAs and VDAs UDA2 (2,983 codepoints) 8E40 – A0FE VDA 1 (408codepoints) C6A1 – C8FE VDA 2 (41 codepoints) F9D6 – F9FE UDA1 (785 codepoints) FA40 – FEFE
Principles: • Compatible with GCCS • Distinct areas for han characters and symbols • Subdivision of UDAs • Extension in the future • Avoid un-necessary use of certain areas UDA 3 8140 – 8DFE (2,041 codepoints) 8140 – 84FE (628 code-points) Reserved for private use only 8540 – 8DFE (1 413 code-points) Reserved for HKSCS-E 757 chars.assigned already
Other Chinese codesets: • CNS 11643-92 (government standard, Taiwan, used in Chinese Solaris,) • Character sets for libraries • CCCII for Taiwan and • ANSI Z39.64-1989 for Library of Congress • Character standards from other countries: • JIS series for Japanese • KS series for Korean, etc.
More on encoding schemes: • ISO-2022 series: uses designated key sequences or switch characters Example: 1B(ESC) 24($) 29( )) 41(A) for GB2312, 1B 24 29 47 for CNS Plane 1 and 1B 24 2A 48 for CNS Plane 2, etc. • EUC( Extended Unix Code) • SS0:ASCII, • SS1:high-bit on, • SS2:0x8E • SS3: 08F • Charset designation and registry • European Computer Manufacturers Association (ECMA) • Registry and the Internet Assigned Numbers Authority (IANA) Registry
Problems with Different Chinese Codesets • Codeset incompatibility: one codepoint in one codeset is used in another codeset for a different character. • Problem with data exchange: Wrong interpretation of data from non-conforming platforms. • Codeset announcement and switching mechanisms are needed when multiple codesets need to co-exist on the same platform • Even the same codeset for different writing styles (simplified and traditional) cannot be presented in the same system • Problems when using codeset conversion • 1-N mapping, example: 后(gb) vs 后後(big5) • 1-0 mapping: some characters in B5 are not in GB, then map to Undefined-Char Symbol  => Round trip conversion problem • Different software must be developed for different codesets