Download

1 / 17
170 likes | 305 Views
Application of Support Vector Machine to detect an association between a disease or trait and multiple SNP variations. Author: Gene Kim,MyungHo Kim Advisor: Dr.Hsu Graduate: Ching-Wen Hong. Outline. 1.Motivation 2.Objective 3. What’s SNP(single nucleotide polymorphism)

E N D
Application of Support Vector Machine to detect an association between a disease or trait and multiple SNP variations Author: Gene Kim,MyungHo Kim Advisor: Dr.Hsu Graduate: Ching-Wen Hong
Outline • 1.Motivation • 2.Objective • 3. What’s SNP(single nucleotide polymorphism) • 4. How to find SNP variations • 5. A review of Support Vector Machine • 6. A representation of multiple SNP variations as a vector • 7.The marks • 8. Inseparable Case • 9.Test results with clinical data • 10. Personal opinion
Motivation • 研究每個人的「單一核甘酸多型性」(SNP)的差異,可以幫助了解致病基因,甚至預測藥物對個人是否具有療效,進一步設計量身訂做藥物,對新藥的開發有極大的影響。SNP的研究是後基因時代生技產業發展的主要趨勢。
Objective • We can present a method of detecting whether there is an association between multiple SNP variations and a trait or disease. • The method exploits the Support Vector Machine(SVM) which has been attracting lots of attentions recently.
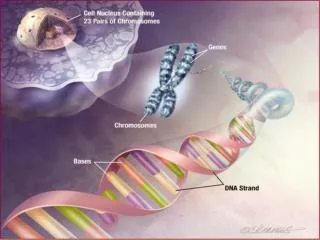
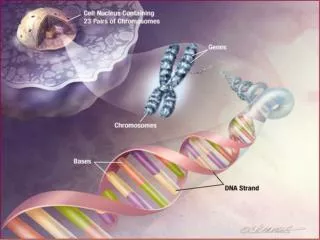
What’s SNP • 何謂SNP(單一核甘酸多型性) • 雖然同種生物其染色體差異極小,但平均1000個鹼基對(base pair)就有一個發生突變,這些變異稱為SNP,是造成每個人對藥物的敏感性不同、血型不同、身高 等等的原因。此外,SNP也和癌症、心血管疾病、自體免疫等等疾病有關。目前國內賽亞基因和台大醫院合作,正從事C型肝炎SNP研究,試圖找出病患的SNP,以預測藥物是否對病人有效。
What’s SNP • A genetic marker is M1,M2,…in the DNA • The different variants of DNA that different people have at the marker are alleles , denoted by 1,2,3..,The number of alleles per marker is small :typically less than ten(for called microsatellite marker)or exactly two (for called SNPs).
How to find SNP variations • The problem of determining whether a set of SNP variation cause a specific disease or trait could be formulated as follows. For a given disease or trait, • 1.For each set of SNP variations, find its representation as a vector in a Euclidean space. (haplotype data,clinical data,….we will discuss this in the page9) • 2. Get a systematic way of distinguishing SNP genotype of normal people from ones of people with the disease or trait. • We will use the Support Vector Machine (SVM) to separate SNP vectors into two groups (normal,sick) .
A review of Support Vector Machine • What is a SVM ? • a family of learning algorithm for classification of objects into two classes . • Input : a training set {(x1,y1),…,(xl ,yl)} of object xi E Ŕ(n-dim vector space) and their known classes yi E {-1,+1}. • Output : a classifier f :Ŕ→ {-1,+1}.which predicts the class f(x) for any (new) object x E Ŕ
A review of Support Vector Machine • (1).Linear SVM for separable training sets: • a training set S= {(x1,y1),…,(xl ,yl)} , xiE Ŕ, yi E {-1,+1}.
A review of Support Vector Machine • The optimal hyperplane is defined by the pair (w,b). • Solve the linear program problem • Min ½║w║² • st. yi(xi·w+b)-1≥0 ,i=1,…,l • This is a class quadratic(convex) program
A review of Support Vector Machine • (2).Linear SVM for non-separable training sets • Solve the linear program problem • Min ½║w║²+C(∑εi) , c is a extreme large value • S.t. yi(xi·w+b)-1+εi≥0 , εi≥0, 0≤αi≤c ,i =1,…,l
A representation of multiple SNP variations as a vector • Scheme • Given each disease or trait, and a collection of SNP data which depending on genotype in a consistent way. ( haplotype, clinical data ):7 step • 1.Assume that there is no environmental factor. • 2.SNP locations are assumed to be know for the disease or trait. • 3.Assume there is a reference SNP data.(good health records) • 4.By giving scores based on difference from the reference data ,assign a vector to each SNP data.
A representation of multiple SNP variations as a vector • The dimension of vector is the number of SNPs to the related disease or trait. • 5.A training set is chosen for the disease or trait, in other words,SNP genotype data of normal and sick population. • 6.By using Step 4,compute the SNP vectors of the training data set﹛(xi,yi)﹜, xi is a SNP data, yi=1(sick)or -1(normal), • 7.Use the SVM to get a hyperplane dividing into two groups (sick, normal)
The remarks • 1. The reference data can be built by collecting SNP genotypes from the healthy normal population. • 2.The hyperplane obatined can be considered as acriterion, and,given a new data set,it can be used for testing whether the person of the data is susceptible to the disease or trait. • 3.Representation of an object as a vector might be critical for making use the SVM.How to make domain knowledge contained in vector representations is one of the major issues. • 4.The idea of difference scoring could be applied to other data sets(visual data such as X-ray or MRI image,…),in particular,to haplotype data and to find out a linkage among SNP to the disease or trait. • 5.Once a group of SNP patterns are identified, it can compute contribution score of each of those SNP to the disease or trait.
Inseparable Case • For the inseparable case ,the iterated use of SVM enables us to divide a collection of labelled of vectors into several clustering groups. • 1.Set a threshold value. Say ,80%. • 2.Use SVM to separate a collection of labelled of vectors into two groups A,B. • 3.Check if the groups contain more than 80% of either 1 or -1 labeled vectors.Suppose A is not such one. Then use SVM to A again to two subgroups. • 4.Repeat this procedure until each subgroup has a majority of more than 80%. • 5. For each subgroup, figure out a range.
Test results with clinical data • The clinical data is a cardio-patient records data set : Height,age,sex,weight,etnic background,medical history,birth place,blood pressure(systolic and diastolic),Liqid measurements etc are numericalized and +1:a patient with heart attack,stroke or heart failure,otherwise -1 • We used Thorsten Joachims’ implementation of SVM.
Personal opinion • Application of SVM is effective ,But it is difficult to solve nonlinear problem. • How to make domain knowledge contained in vector representations is one of the major issues.