Download

1 / 24
240 likes | 572 Views
Experience Rating with Separate Frequency & Severity Distributions. Alice Underwood Seminar on Reinsurance June 7-8, 2004. XOL Experience Rating. Bring historical losses and exposures to an ultimate, “as-if” basis, considering Loss Trend Loss Development (IBNYR and IBNER)

E N D
Experience Rating with Separate Frequency & Severity Distributions Alice Underwood Seminar on Reinsurance June 7-8, 2004
XOL Experience Rating • Bring historical losses and exposures to an ultimate, “as-if” basis, considering • Loss Trend • Loss Development (IBNYR and IBNER) • Exposure Trend (e.g. Premium Onlevel) • Create a loss model based on these • Project results for the XOL layer • Behavior of losses in the layer • Effect of treaty features
Let’s Assume Perfect Data • Historical exposure information • E.g. premiums, payroll, bed count • Method for bringing to current levels • Credible historical claim detail • Individual losses xs appropriate threshold, each claim at consecutive evaluation dates • Accident dates (assume L.O. treaty) • Separate claim components (Pd, O/S, ALAE)
One Plan of Attack 1. Bring historical exposures to future AY level 2. Trend each loss to common future accident date 3. Apply policy limits, layer attachment & retention 4. Aggregate the trended layer losses by accident year 5. Create development triangle of trended AY layer loss 6. Select LDFs and ultimate AY trended loss 7. Calculate as-if AY burning cost ratios to exposure 8. Fit a distribution to the historical burning cost ratios; apply this to the projected exposure base Voila! An aggregate loss model for the layer. (assuming sufficient credibility, no need for cat load, etc)
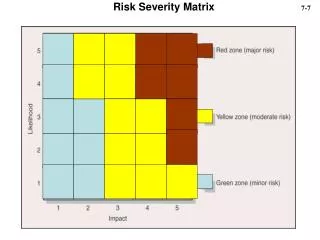
Aggregate Loss Distribution Function Illustration 1: Aggregate losses to 1 xs 1 layer 5
Applying Treaty Features? • What would be the effect of, say, a limited number of reinstatements? • Could go back and construct as-if treaty losses on this basis…but… • Results will be less credible • Fitted model a less accurate reflection of exact treaty structure • A hassle to re-do this every time the underwriter wants to try a different structure Loss-sensitive treaty features…a strong reason “WHY” to model frequency & severity separately
Typical Frequency & Severity Models • Poisson • Negative Binomial • Convolute to get aggregate distribution • Numerically (e.g. Panjer, Heckman-Meyers) • Simulation (e.g. Monte Carlo) • Single Parameter Pareto • Lognormal
Aggregate Loss Distribution Function Illustration 1: Aggregate losses to 1 xs 1 layer 8
Aggregate Loss Distribution Function Illustration 1a: Layer 1 xs 1, with only one reinstatement 9
Aggregate Loss Distribution Function Illustration 2: Layer 2 xs 2, with unlimited reinstatements 10
Aggregate Loss Distribution Function Illustration 2a: Layer 2 xs 2, with only one reinstatement 11
OK, but HOW do you get these separate distributions? (1) • Could apply “method of moments” with single parameter distributions: • Expected frequency to the layer (via experience analysis of claim counts) • Poisson parameter • Expected severity to layer = E(loss)/E(freq) • Pareto parameter • A viable method, but… • Ignores higher moments (e.g. Poisson / Pareto may not be the best model) • Deductibles/SIRs and policy limits should be applied to ultimate individual claim values
OK, but HOW do you get these separate distributions? (2) Could try fitting distributions (via least squares, maximum likelihood, “eyeball method”, etc) directly to the actual trended claim data: • Historical frequency of trended losses • Historical severity of trended losses Again do-able, but… Ignores development! (Which may be OK for short tail lines)
OK, but HOW do you get these separate distributions? (3) • Separately reflect two kinds of development • Development on reported claims (IBNER) • Claims that have not yet been reported or have not yet exceeded the reporting threshold (IBNYR) • Will describe a method based on René Schnieper’s paper “Separating True IBNR and IBNER Claims” (ASTIN Bulletin Vol. 21, No. 1) • Provides an alternative / cross-check to aggregate methods for longer-tailed lines
IBNER Method: Data & Notation • Individual (layer) claims with development • For n accident and development years • Claim data can be paid or incurred • Claim data must be trended to future levels • Denote triangle of aggregated losses by Xi,j • Exposure Ei for each accident year
IBNER Method: Definitions • Ni,j : Sum of losses of accident year i which have first nonzero value in development year j • IBNYR or"newly entering losses" 0 for j=1 • Di,j= Xi,j-1-Xi,j+Ni,j for j>2 • - IBNER or"downward development on known losses" • Note Xi,j - Xi,j-1 = Ni,j - Di,j for j>2 • Set of observed variables up to calendar year k : Hk= {Ni,j,Di,j | i+j < k+1}
IBNER Method: Assumptions • General assumption: random variables pertaining to different accident years are stochastically independent • Assumptions for the N triangle (new losses) • (N1) E[Ni,j | Hi+j-2] = Ei lj dev yr j=1,…,n • (N2) Var [Ni,j] = Ei 2j dev yr j=1,…,n • Estimators (biasfree, assuming Ei 0) Recall Ei denotes exposure for accident year i
IBNER Method: Assumptions (cont’d) • Assumptions for the D triangle (downward development) • (D1) E[Di,j | Hi+j-2] = Xi,j-1 di dev yr j=1,…,n • (D2) Var[Di,j | Hn] = Xi,j-1 2j dev yr j=1,…,n • Estimators (biasfree, assuming Xi,j-1 0) Recall Xij denotes triangle of aggregate losses The factors j are called the IBNER factors.
IBNER Method: Projection • Under these assumptions, the future losses can be estimated recursively : • The estimators for the ultimate of accident year i (without tail) are then • Comment: this method can also be applied to the frequency triangle
Single Loss Development • If we assume that a similar development pattern applies to each claim, the formula implies that we can develop the single open claims to ultimate using the factors (1-j) • A severity distribution can then be fitted to these developed single claims
SLD: Remarks • The assumptions are fairly strong • Comparable development of all claims • Might differ by claim size, cause of loss... • Linear dependence • But linearity assumptions of CL rarely verified either • Method best applied to very stable triangles • Still need to include a tail factor • Even “perfect” real world data likely to be biased • Large losses in excess of some threshold • For green AYs, fewer claims initially exceed threshold • Those claims might tend to be more severe • Effect of policy limits
Application of SLD • Fundamental assumption: all claims have a similar development • Unreasonably strong assumption? • Partial remedy: divide the losses into classes • One approach: group losses by size • Sort claims by size at last report and divide into groups • Must confront credibility issues: population of size groups
Finally… • Severity distribution can be fitted to collection of trended ULTIMATE single claims • Frequency distribution based on claim count development • Use simulation to generate projected treaty results