Download
1 / 48
480 likes | 641 Views
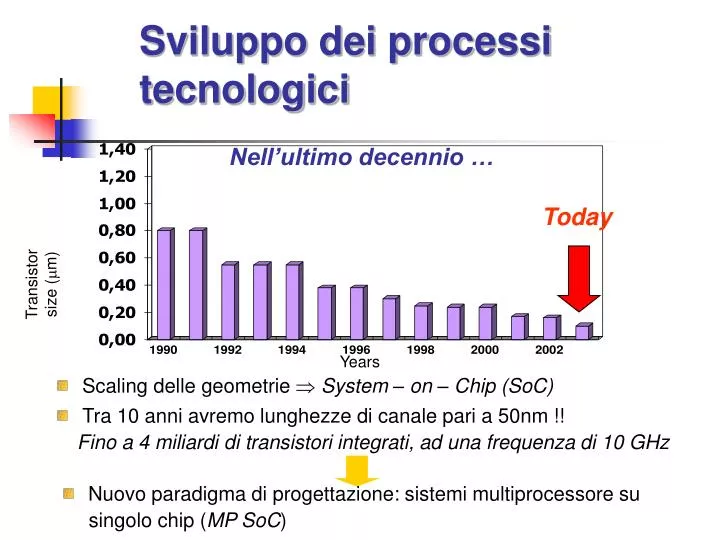
Today. Sviluppo dei processi tecnologici. Nell’ultimo decennio …. Transistor size ( m). Years. Scaling delle geometrie System – on – Chip (SoC). Tra 10 anni avremo lunghezze di canale pari a 50nm !! Fino a 4 miliardi di transistori integrati, ad una frequenza di 10 GHz.

E N D
Today Sviluppo dei processi tecnologici Nell’ultimo decennio … Transistor size (m) Years • Scaling delle geometrie System – on – Chip (SoC) • Tra 10 anni avremo lunghezze di canale pari a 50nm !! • Fino a 4 miliardi di transistori integrati, ad una frequenza di 10 GHz • Nuovo paradigma di progettazione: sistemi multiprocessore su • singolo chip (MP SoC)
System-on-Chip System-on-Chip: MPEG decoder Co-Proc CPU Memory1 Bridge Video Enc. Interface Arbiter1 Architettura di comunicazione Application specific logic Memory2 Arbiter2 • Elevate densità di integrazione rese disponibili dalla tecnologia • Evoluzione delle architetture (da shared bus a network on chip) • Interc. responsabili del 40-50% del consumo del chip • Wires globali: grandi capacità di carico da commutare • Contributo dei ripetitori con lo scalare della tecnologia
ReconfigurableProcessor/Logic Wireless embedded systems 10-80 MOPS/mW ASIPs DSPs 2 V DSP: 3 MOPS/mW Embedded Processors 0.4 MIPS/mW The Energy-Flexibility Tradeoff 1000 Dedicated HW 100 Energy Efficiency MOPS/mW (or MIPS/mW) 10 1 0.1 Flexibility (Coverage)
Wireless Handset Functionality MICROCONTROLLER CONTROLLER RF MODEM PHYSICAL LAYER PROCESSING BASEBAND CONVERTER ASIC A/D SPEECH ENCODE SPEECH DECODE DAC DSP Voice Voice ANALOG IC
TI’s TMS320vc5471 Wireless Handset C540 ARM7
SCALING TREND • Keeping the pace with Gene’s Law: DPS Chip’s energy efficiency (MIPS/Watt) doubles every 18 Month • Low Cost • High flexibility • Reduce idle power in idle state • Gene’s Law Tech&Circ: Voltage islands, Arch: MPSoC • Low Cost Integrate, but only when cost effective • Push towards A & D integration • High flexibility Software radios, reconfigurable architectures • Reduce static power in idle state Variable Vdd, VT
NOC NOC MPSoC IO IO IO COPR COPR SOCBUS MEM MEM CPU MEM MEM Vdd1 Vdd3 Vdd2 • From single-master CPU to MPSoC • From bus-based interconnect to NoC • Emphasize reuse, flexibility A distributed system on a single chip!
Berkeley’s Maia (1999) Reconfigurable Baseband Processor for Wireless • 0.25um tech: 4.5mm x 6mm • 1.2 Million transistors • 40 MHz at 1V • 1 mW VCELP voice coder • Hardware • 1 ARM-8 • 8 SRAMs & 8 AGPs • 2 MACs • 2 ALUs • 2 In-Ports and 2 Out-Ports • 14x8 FPGA • Interconnect: Hierarchical mesh
Sensor network design space ReconfigurableProcessor/Logic 10-80 MOPS/mW ASIPs DSPs 2 V DSP: 3 MOPS/mW Embedded Processors 0.4 MIPS/mW Sensor Networks 1000 Dedicated HW 100 Energy Efficiency MOPS/mW (or MIPS/mW) 10 1 0.1 Flexibility (Coverage)
Mirror Solar Cell Accelerometer Solar Cell Charge Pump Photodiode Controller ADC Temperature Sensor Receiver 0.25µm CMOS – double poly, 5 metals [Warneke01] Sensor Networks • Autonomous sensor node in 1mm3 • Multiple sensors: temperature, light, vibration, .. • Thousands of butterflies LOW COST! • Wireless interconnection • Full system integration (including power supply) • Microwatt power consumption
BUS CONDIVISO • Prestazioni medie; • Bassa occupazione d’area; • Semplicità dell’interfaccia IP. SLAVE SLAVE SLAVE SHARED BUS MASTER MASTER MASTER • NETWORK • Elevate prestazioni; • Alta occupazione d’area; • Scalabilità. Network on Chip Architetture di comunicazione Shared bus: stato dell’arte Network => reti future
Shared bus • Tradizionalmente basata su bus condiviso (shared bus) • arbitro: serializzazione degli accessi • Opzioni avanzate: • Split transactions • pipelining • bridging e bus segmentation • lock del bus • preemption • algoritmi di arbitraggio
Shared bus • Difficilmente scalabile: • aumenta latenza dovuta alla contention sul bus • ruolo chiave della politica di arbitraggio • modalità di comunicazione multicast • incremento della capacità di carico • incremento delle frequenze di clock Consumo di potenza e collo di bottiglia per le prestazioni Necessità di un architettura di comunicazione più evoluta: • Micro-reti di interconnessioni
Network-on-chip • Supporto contemporaneo • di transazioni multiple • Riconfigurabilità • Segmenti al posto di linee • globali • Scalabilità • Comunicazione a pacchetti • Disponibilità di diversi • gradi di libertà per il progettista: • - topologia • - routing • - ampiezze dei bus • - numero di porte • - controllo di flusso Network-on-Chip di tipo Butterfly
Concetti base SWITCH: elementi di commutazione ed instradamento del pacchetto connessi da link point-to-point (arbitraggio distribuito) PACCHETTO: TAIL PAYLOAD HEADER al fine di mantenere una bassa latenza nonostante l’elevato numero di hop: WORMHOLE ROUTING Packet tail SWITCH A SWITCH B SWITCH C Packet header • Ai fini della latenza, è importante che l’header arrivi il prima possibile • Se viene richiesto un link “busy”, tutta la macro-pipeline si blocca
Confronto Laddove NoC conviene…….. • Ogni unità funzionale aggiuntiva aggiunge capacità parassit • + Si utilizzano solo wires point-to-point one-way • Problemi di bus timing in bus sub-micrometrici • + Possibilità di wires pipelined poiché il protocollo è GALS • Il delay dell’arbitro cresce col no. di master. Arbitro instance-specific • + Decisioni di routing distribuite. Switches reinstanziabili • Banda è limitata e condivisa da tutte le unità • + La banda scala con la dimensione della rete
Confronto e laddove shared bus conviene…….. • + La latenza di accesso al bus è nulla dopo la concessione del bus • problemi di congestione di rete possono causare un certo delay • + Costo in termini di silicio di un bus è pressochè nullo • Notevole costo in area per una rete on-chip • + Le interfacce bus – IP sono molto semplici • Le interfacce bus-IP possono essere molto complesse (wrappers) • + Criteri di progetto semplici e ben compresi • - Necessità di un nuovo paradigma progettuale
Master #1 Master #2 Master #N SLOT DURATION Master #4 Master #1 Master #4 Master #3 Master #1 Master #2 POLITICHE DI ARBITRAGGIO • TDMA • Round robin Master #2->N Round robin • SLOT reservation Master #1 SLOT RESERVATION • Altre politiche: • Priorità fissa statica • Priorità fissa dinamica • TDMA splittabile • latency-based
User task Rtems_message_send RTEMS GET_PACKET build the message MPCI Layer write to interrupt slave PROC #X SHARED BUS INTERRUPT SLAVE #Y PROC #Y COMUNICAZIONE TRA I PROCESSORI SHARED MEMORY
Proc.1 Proc.2 Proc.3 PUNTO DI SINCRONIZZAZIONE FLUSSO D’ESECUZIONE • Task mutuamente dipendenti; SHARED BUS • 2. Task indipendenti; Private Mem.1 Private Mem.2 Private Mem.3 3. Task in pipeline; SCAMBIO DI DATI COMUNICAZIONE TRA PROCESSI ANALISI DELLE PRESTAZIONI Tre differenti benchmark che rappresentano tre diversi tipi traffico sul bus:
TASK MUTUAMENTE DIPENDENTI RTEMS bootstrap con 5 processori • Prestazione misurata: Tempo d’esecuzione • Slot reservation ha le prestazioni migliori per via del carico non bilanciato. • TDMA alloca la banda in modo non efficiente.
TASK IN PIPELINE • Prestazione misurata: NUMERO DI MATRICI ELABORATE AL SECONDO • Slot reservation converge asintoticamente al round robin • Le prestazioni del TDMA sono quasi invarianti all’aumentare della slot • Basse prestazioni del TDMA
Producer Consumer Bus access Bus access Bus access Bus access Crea una coda nella sua mem. Scrive un messaggio nella coda Richiede un messaggio Bus access Bus access Interrompe il producer Legge la richiesta nella mem. condivisa Bus access Scrive il msg. nella shared Interrompe il consumer Legge il msg. dalla shared Bus access Questo meccanismo di hand-shake non è efficientemente supportato dal TDMA TASK IN PIPELINE Implementazione del meccanismo di comunicazione ad alto livello:
AMBA bus Il bus viene segmentato per ridurre la capacità di carico attraverso un bridge Interfaccia sistema- periferiche AHB System Bus: bus ad alta velocità ed alta banda che supporta una pluralità di masters per massimizzare la prestazione del sistema APB: Bus con protocollo semplificato per periferiche general-purpose
AMBA bus Obiettivi: • Facilitare il “right-first-time-development” di sistemi embedded • multimaster • Architettura technology-independent con elevati gradi di • riusabilità • Minimizzare infrastruttura di comunicazione • Incoraggiare il progetto di sistemi modulari
AMBA AHB APB AHB • Slave-only bus • Unpipelined bus • Low power interface • Used for: • Register-mapped slaves • Narrow-bus peripherals • High Performance • Multiple Bus Masters • Pipelined Operation • Burst Transfers • Split Transactions • Used for: • Processors, on-chip memory • I.face to off-chip memory
SPLIT E RETRY • Entrambi usati quando lo slave non riesce a terminare • immediatamente il trasferimento in corso • Bus riarbitrabile • RETRY: • solo masters a priorità più alta possono accedere al bus • SPLIT: • qualunque master può accedere al bus • arbitro deve sapere quando lo slave è pronto a terminare Dal punto di vista del MASTER, non cambia nulla: esso continua a richiedere il bus per ultimare il trasferimento
SPLIT TRANSACTIONS Master comincia un trasferimento normale Slave può completare Subito? NO SI Può avvenire il bus master handover Memorizza hmaster Risposta split su 2 cicli slave Quando lo slave è pronto, notifica il suo master tramite HSPLIT all’arbitro Alla riconcessione, Il master riprova Il trasferimtno Ripristino delle priorità precedenti
Granting bus access ARBITER
WRITE TRANSFER Setup cycle Enable cycle • Per il basso consumo, dopo la fine dell’Enable cycle indirizzi • e segnali di controllo non cambiano
READ TRANSFER Campionamento dati
Interfacciamento AHB-APB Ciclo di lettura

