Download

1 / 31
310 likes | 493 Views
6. Workload characterization techniques. move! B4 hiko. Workload の特徴付け. 実際のユーザ環境の workload を知る 実際のユーザ環境は継続的でない →継続的に使える Workload モデルを作る. モデル化に必要なこと. いくつかの統計的な手法を知ってないと・・・ 確率論 (probability theory) 統計学 (statistics) など →ともかく詳しくは PartⅢ を見てね. 6.1 専門用語 (1). User

E N D
6. Workload characterization techniques move! B4 hiko
Workloadの特徴付け • 実際のユーザ環境のworkloadを知る • 実際のユーザ環境は継続的でない →継続的に使えるWorkloadモデルを作る
モデル化に必要なこと • いくつかの統計的な手法を知ってないと・・・ • 確率論(probability theory) • 統計学(statistics)など →ともかく詳しくはPartⅢを見てね
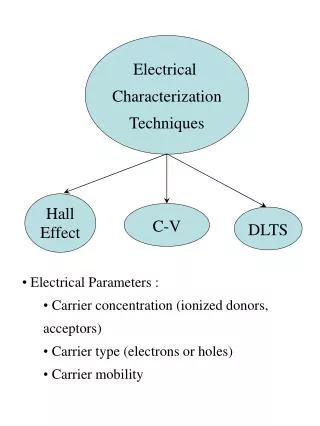
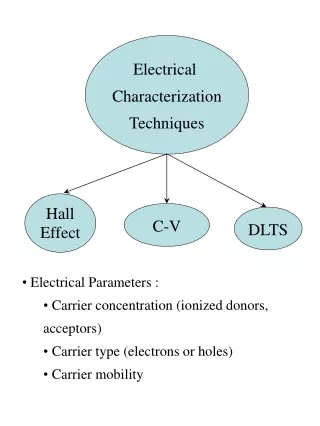
6.1 専門用語(1) • User • SUT(SystemUnderTest)でサービス要求する • 人間である場合・ない場合両方ある ex)SUTがprocessorだった場合、userはプログラムやバッチジョブ
6.1 専門用語(2) • Workload component / Workload unit • Userの代わりに用いられる • 日本語に直訳すると • Workload = 作業負荷・仕事量 • Component = 成分・要素・部品・構成材 ・・・ださい →Workloadの特徴付けとは一般的なuserやWorkload componentsを特徴づけること
Workload componentsの例 • Applications • 多様なアプリケーションの振る舞いをモデル化する場合、それぞれのアプリケーション • Ex) mail, text editor, program development • Sites(場所) • 組織のいくつかの場所ごとのworkloadを識別する場合 • User Sessions • ログインからログアウトまでmonitoringされていて
専門用語(3) • Workload parameters / Workload features • ワークロードのモデル化や特徴付けに使われる • 計測量やサービス要求、資源需要など • 具体例) • Transaction types • Instructions • packet sizes • Source destinations of a packet • Page reference pattern
パラメータの選択 • システムに依存したパラメータよりワークロードに依存したパラメータを使う • トランザクションにとって応答時間はworkload parameterとして適切でない • トランザクションが処理されるシステムにとても依存するので • パフォーマンスに大きな影響を与えるかどうか • 与えないなら使わない
7つのテクニック • 1 平均(averaging) • 2 分散(specifying dispersin) • 3 Single-parameter histograms • 4 Multiparameter histograms • 5 主要コンポーネント分析 • 6 マルコフモデル • 7 クラスタリング(分類)
6.2 平均 • 複数のパラメータの値を要約して一つの数字で表したもの • P73の真ん中あたりの式 • x1,x2, … xnはパラメータの値
6.3 ばらつきの特定 • ばらつきを「分散」によって特定する • データにばらつきがある場合、平均では不十分 • s^2 = 1 / (n-1) Σ(Xi - ¬X)^2 • Σはi=1 ~ n • s = 標準偏差 • 標準偏差の比率を Coefficient Of Variation(C.O.V)と呼ぶ
6.4 single-parameter histogram • 連続した値のパラメータに関して、バケツに入る値の数をカウントしたもの • バケツ:全体をある一定の小さな範囲に分割したもの • 他のパラメータとの関係を考慮しないのは問題 • 次のmulti-parameter histogramを使う
6.5 multi-parameter histograms • 2つ以上のパラメータのグラフ • 異なるworkload parameter間に重要な相関関係がある場合 • 図6.2を参照 • Singleよりも詳しい • 詳しすぎる(?)ので、今ではめったに使われない
6.6 主要コンポーネントの分析 • 重み付けされたパラメータ値の総計による分類 • P76の式 • 主要ファクタ(Principal factor)を作り出す • ( = Principal component ) • P77の真ん中(y1, y2, … yn)
6.7 マルコフモデル • 前のリクエストとその次のリクエストの間に依存関係があると仮定するとき • サービスリクエストの数だけタイプがあるだけでなく、順番もあるとき • Transition probability matrix • P81-82参照
6.8 クラスタリング • 近似したコンポーネントをそれぞれ少数のクラス(タ)に分類する • 計測されるworkloadは多くのコンポーネントからなる(のでやってらんね)
クラスタリングの手順 • サンプルを取る • ワークロードパラメータを選択する • 必要なら、パラメータを変換する • 外れ値を取り除く • 全ての観察結果を計量する • 距離指標を選択する • クラスタリングする • 結果を読み取る • パラメータやクラスタの数を変えて3~7のステップを繰り返す • それぞれのクラスタから代表的なコンポーネントを選ぶ
6.8.1 サンプリング • 小さなサブセットを抽出する • 一般的には、測定するコンポーネントが多すぎてクラスタリング分析できないので • 一つの手法としてランダム選択もある • 問題もあるけど
6.8.2 パラメータ選択 • 選択には2つの基準がある • パフォーマンスにおける影響 • システムの性能に影響を与えないパラメータは省略 • パラメータの変化 • 一つずつパラメータを減らしていって変化を見る • 変化が少なければ不必要
6.8.3 変換 • あるパラメータの分布がとても偏っている場合、パラメータを変換して置き換える • 必要なければやらない • 変換法や適切な条件についてはSec15.4
6.8.4 外れ値の除去 • 最大値や最小値に重大な影響をもたらす • 上記の値は正規化に必要な値 • 次で説明 • 含めるか否かでクラスタリングの結果が変わる • 例) • 1日数回行われるバックアッププログラムではディスクI/Oの回数が非常に多くなるので外れ値に含めた方がいい • 逆に1ヶ月に数回なら含めない方がいい
6.8.5 データのスケーリング • パラメータ間での相対値や範囲を同じにする • クラスタリングの最終結果は、パラメータ間における相対値や範囲に左右される • 4つのスケーリングテクニックがある • Normalize to Zero Mean and Unit Variance(正規化) • Weights(重み付け) • Range Normalization(範囲正規化) • Percentile Normalization(パーセンタイル正規化)
6.8.6 距離指標 • 2つのコンポーネント間の近似性を表す指標 • 3つのテクニック • ユークリッド距離 • もっとも一般的に使われる • 重み付けユークリッド距離 • パラメータがスケールしないとき • パラメータの重要度が極端に違うとき • カイ二乗距離 • Is generally used In distribution fitting?
6.8.7 クラスタリング技術 • クラスタリングの基本的なねらいはコンポーネントをグループに分配すること • 似たコンポーネントは同じグループへ • グループ内分散(intragroup variance)の値は小さく • 違うコンポーネントは違うグループへ • グループ間分散(intergroup variance)の値は大きく →どちらか達成すればいい • 全分散 = グループ内分散 + グループ間分散 • 全分散は常に一定
6.8.7 クラスタリング技術(2) • クラスタリング技術は2つのクラスに分かれる • 非階層的 • 自由なK個のクラスタから始めグループ内分散が最小であればクラスタのメンバを移動する • 階層的 • 集積的 • N個のクラスタからはじめ希望の個数になるまでマージし続ける • 分割的 • 一つのクラスタからはじめ希望の個数になるまで分割し続ける
6.8.8 最小全域木法 • 集積的で階層的なクラスタリング • いわゆるデンドログラム • 例のあれ
手順 • N個のクラスタから始める • i番目のクラスタの重心を見つける(I = 1,2…k) 。重心はパラメータの値と全てのポイントの平均と等しい。 • クラスタ間の座標距離を計算する。(i, j)番目の要素6.8.6で記述したとおり。 • 座標距離が、最も小さく0でない要素を見つける。 • 全てのコンポーネントが一つのクラスタに属すまで、2から4のステップを繰り返す
Example6.3 • 5つのコンポーネント • Program A~E • 2つのパラメータ • CPU Time • Disk I/O • 図6.6はScale済み • 図6.7をデンドログラムと呼ぶ
6.8.9 クラスタの解釈 • 全ての測定コンポーネントをクラスタに割り当てる • 所属コンポーネントが少ないクラスタは廃止すべき • クラスターの重要性は全体的な資源需要によって決まる • クラスタごとのコンポーネント数は関係ない
6.8.10 クラスタリングの問題点 • 同じデータでも矛盾した結果がでる可能性 • ゴールの定義に関連する • intracluster分散値を最小にする場合 • Intercluster分散値を最大にする場合 ex)図6.8の場合、分散値の最小化をすると目に見えるグループと異なるクラスタリングが行われる。
クラスタリングの問題点(2) • クラスタリングはプログラムのランダム選択よりはよい • でも結果がとても変わりやすい • selection of parameters • distance measure • scaling • …