Download

1 / 25
250 likes | 397 Views
Strategies towards improving the utility of scientific big data Evan Bolton, PhD National Center for Biotechnology Information (NCBI) National Library of Medicine (NLM) National Institutes of Health (NIH ) Sep. 4, 2014. http://www.nlm.nih.gov/.

E N D
Strategies towards improving the utility of scientific big data Evan Bolton, PhD National Center for Biotechnology Information (NCBI) National Library of Medicine (NLM) National Institutes of Health (NIH) Sep. 4, 2014
U.S. National Center for Biotechnology Information https://www.ncbi.nlm.nih.gov/
PubChem website https://pubchem.ncbi.nlm.nih.gov/
PubChem primary goal … to be an on-line resource providing comprehensive information on the biological activities of substances where “substance” means any biologically testable entity Small molecules, RNAs, carbohydrates, peptides, plant extracts, etc.
PubChem data growth over ten years Chemicals Biological Assays Contributors Protein Targets Tested Chemicals Bioactivity Results +280 substance contributors, +60 assay contributors, +150M substances, +50M compounds, +1.0M bioassays, +6.1T protein targets, +2.9M tested substances, +2.0M tested compounds, +225M bioactivity result sets [M=millions, T=thousands, MLP = Molecular Libraries Program]
Big data has “big errors” Hypothetical If your average data error rate is 1 in 1,000,000, you have 99.999% data accuracy If you have one trillion facts (10^12), can you accept one million errors (10^9)? Strategies to mitigate errors? Manual curation has its limits (accuracy, cost, time) So .. what do you do?
Error suppression strategies for scientific big data Identify quality {un}known known/unknowns use to formulate an error suppression strategy Perform data normalization improves utility by helping to refine identification “Trust but verify” cross compare authoritative and curated data Consistency filtering improves precision by removal of outliers Address error feedback loops use “is”, “can be”, and, if all else fails, “is not” lists
Error suppression strategies for scientific big data Identify quality {un}known known/unknowns use to formulate an error suppression strategy there are known knowns; there are things that we know that we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns, the ones we don't know we don't know Feb. 2002 news briefing Ring Closed Salt-form drawing variations are common (+)-Iridodial Defense chemicals from abdominal glands of 13 rove beetle species of subtribe Staphylinina Tautomers and resonance forms of same chemical structure are prolific Ring Open Chemical meaning of a substance may change upon context Image credit: http://en.wikipedia.org/wiki/Donald_Rumsfeld
Error suppression strategies for scientific big data Perform data normalization improves utility by helping to refine identification • Verify chemical content • Atoms defined/real • Implicit hydrogen • Functional group • Atom valence sanity • Normalize representation • Tautomer invariance • Aromaticity detection • Stereochemistry • Explicit hydrogen • Detect components • Isolate covalent units • Neutralize (+/- proton) • Reprocess • Detect unique • Calculate • Coordinates • Properties • Descriptors
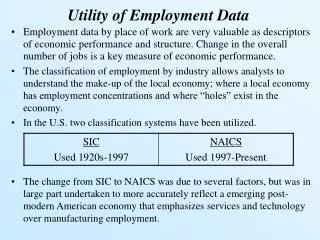
Error suppression strategies for scientific big data “Trust but verify” cross compare authoritative and curated data Cross concept count % CTD HDO KEG MED NDF ORD CTD 100.0 14.3 79.1 40.7 49.7 35.8 HDO 26.0 100.0 38.7 52.4 48.3 26.2 KEG 24.8 6.7 100.0 10.7 6.4 25.2 MED 97.2 68.9 81.6 100.0 93.8 79.6 NDF 30.4 16.3 12.5 24.0 100.0 10.8 ORD 31.9 12.8 71.6 29.7 15.7 100.0 Доверяй, но проверяй (doveryai, no proveryai) Russian proverb used extensively by Ronald Regan when discussing relations with the Soviet Union or John Kerry’s more recent adaption of the phrase when discussing Syria’s chemical weapons disposal: “Verify and verify” Cross-reference overlaps between various disease resources: Human Disease Ontology (HDO), NCBI MedGen (MED), CTD MEDIC (CTD), KEGG Disease (KEG), NDF-RT (NDF), and OrphaNet (ORD) using NLM Medical Subject Headings (MeSH) as the basis of comparison. Image credit: http://en.wikipedia.org/wiki/Ronald_Reagan Image credit: http://en.wikipedia.org/wiki/John_Kerry
Error suppression strategies for scientific big data Consistency filtering improves precision by removal of outliers Keep consensus, remove the rest Image credit: http://withfriendship.com/images/c/11229/Accuracy-and-precision-picture.png
Error suppression strategies for scientific big data Address error feedback loops use “is”, “can be”, and, if all else fails, “is not” lists Prevent error proliferation at the data source, when possible
Error suppression strategies for scientific big data Identify quality {un}known known/unknowns use to formulate an error suppression strategy Perform data normalization improves utility by helping to refine identification “Trust but verify” cross compare authoritative and curated data Consistency filtering improves precision by removal of outliers Address error feedback loops use “is”, “can be”, and, if all else fails, “is not” lists
Okay … now what? … you have cleaned up your data … but it is huge, unwieldy, unstructured How can it be made more useful?
Data organization strategies for scientific big data Crosslink and annotate data provides context and identifies associated concepts Establish similarity schemes enables identification of related records Associate to concept hierarchies improves navigation between related records Perform data reduction suppresses “redundant” information Be succinct simplifies presentation by hiding details
Data organization strategies for scientific big data Crosslink and annotate data provides context and identifies associated concepts Substance Patent Protein inhibit cites encode participates Gene Pathway cites Compound associates Disease Publication ingredient treat cites Drug
Data organization strategies for scientific big data Establish similarity schemes enables identification of related records Vioxx
Data organization strategies for scientific big data Associate to concept hierarchies improves navigation between related records Match to concept = chemical protein gene patent publication pathway … … Organized records Independent hierarchy
Data organization strategies for scientific big data Perform data reduction suppresses “redundant” information Be succinct simplifies presentation by hiding details subject object predicate “subject-predicate-object” “atorvastatinmay treat hypercholesterolemia” Provenance information Evidence citation (PMID) From whom? (Data Source)
Data organization strategies for scientific big data Crosslink and annotate data provides context and identifies associated concepts Establish similarity schemes enables identification of related records Associate to concept hierarchies improves navigation between related records Perform data reduction suppresses “redundant” information Be succinct simplifies presentation by hiding details
Concluding remarks Scientific “big data” … … contains an amazing amount of information … provides opportunities to make discoveries … benefits from strategies to massage it PubChem is doing its part … … making chemical substance data broadly accessible … cross-integrating it to key scientific resources … suppressing errors and their propagation … organizing the data and making it available https://pubchem.ncbi.nlm.nih.gov
PubChem Crew … SiqianHe Sunghwan Kim Ben Shoemaker Paul Thiessen Jiyao Wang Yanli Wang Bo Yu Jian Zhang Steve Bryant TiejunChen Gang Fu Lewis Geer Renata Geer Asta Gindulyte Volker Hahnke Lianyi Han Jane He Special thanks to the NCBI Help Desk, especially Rana Morris
Any questions? If you think of one later, email me: bolton@ncbi.nlm.nih.gov