Download

1 / 32
330 likes | 546 Views
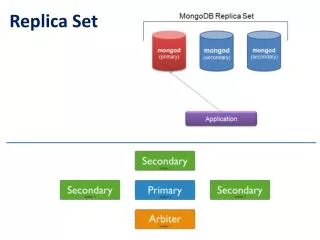
Replica Management. Mansi Radke mansir1@umbc.edu. What is replication? ?& why replication?. Replication is having multiple copies of data and services in a distributed system Reasons: Reliability of the system Better protection against corrupted data

E N D
Replica Management Mansi Radke mansir1@umbc.edu
What is replication? ?& why replication? • Replication is having multiple copies of data and services in a distributed system • Reasons: • Reliability of the system • Better protection against corrupted data • Improved Performance and faster response time • Facilitates scaling in numbers and geographical area.
Key Issues: • Where, when and by whom replicas should be placed. • Mechanisms to keep them consistent. • Two main sub-problems: • Replica-server Placement • Finding best location or placed where a server can be placed. • Content Placement • Finding out which server is best for storing a particular content.
Replica Server Placement • Based on Distance between clients and locations as starting point. (latency , bandwidth) • Best K out of N locations (K<N) are selected • By applying Clustering • Group nodes accessing the same content and with low inter-nodal latencies into groups or clusters and place a replica on the k largest clusters.
Content Replication and Placement • Permanent Replicas • Geographically distributed - Mirroring • Same location – Round Robin • Server Initiated Replicas • Client Initiated Replicas
Server Initiated Replicas • Initiative of owner of data store • Enhance performance C2 Server without copy of F P Q Server with copy of F C1
Client Initiated Replicas • Client caches • Managing is entirely by client • Improve access time • Placement • Same machine • LAN • WAN
Content Distribution • Propagation of Updated content • Propagate only notification of an update • Invalidation Protocols • Transfer data from one copy to another • Propagate the update operation to other copies
Push Vs Pull Protocols • Push • Server based • Read to update ratio is high • High degree of consistency • Multicasting • Pull • Client based • Read to update ratio is low • Unicasting • Lease
What next ? • Consistency Protocols • Continuous consistency • Primary based protocols • Remote write protocols • Local write protocols • Replicated write protocols • Active Replication • Quorum-based protocols • Cache coherence Protocols • Coherence detection strategy • Coherence enforcement strategy • Write through and write back caches • Client centric consistency implementation
Algorithms for replica Placement • Greedy Approach • Places replicas one by one each time exhaustively evaluating all possible locations. It produces very good replica placements but the computational cost is very high. O(KN^2). • Hot Spot • Places replicas on nodes that along with their neighbors generate greatest load. o(N^2 + min (N . Log N + N.K)).
Hot zone – Michal szymaniak, Marteen Steen • Two step algorithm: • Identify network region where replica is to be placed. • Once a n/w region is identified then a replica holding node is chosen from each group.
Hot zone – Latency Driven Replica Placement Algorithm • GNP ( Global netwrork positioning) represents the complex structure of the internet by simple geometric space. It approximates the latency between two nodes based on the coordinates in an M –dimensional Euclidean space. • Network regions are identified by determining the clusters of node coordinates in Euclidean space.
For identifying and measuring the coordinate clusters, split the M-dimensional space into cells of identical size. • Each cell is uniquely defined by its center point. • The density of the cell is defined by the number of nodes whose coordinates fall within that cell. Coordinates of the node are mapped to the cell. • The replicas are then placed in the most dense cells.
Split clusters • The clusters may span multiple cells. This hampers the optimal performance of the algorithm. Hence zones were introduced. • Zone: • Each zone consists of the cell and its neighbors. i.e 3^m cells in total
Split clusters Split cluster Non Split cluster
Complexity Analysis of the Algorithm • N - No of nodes • K - No of replicas • M - GNP space dimension. • Step 1 – To determine the Average distance between nodes – This is computed with fixed number of randomly selected nodes. This step has constant cost.
Step 2 Construct the zones. • Assign nodes to their corresponding cells. O(N) • Set of non empty cells is translated to zones by identifying the neighboring cells of each cell and sum their densities. • Each zone = 3^m cells and no of cells = N , so O(N) cell accesses. • Sort the cells according to their centre points using Radix sort O(N) and then indivisual cells accessed using binary search , so O(log N). • So total cost of step 2 = O( N. logN)
Step 3 Placing replicas • For each replica we identify the most dense zones which needs inspecting all the zones O(N). • The same operation performed on all replicas . So O(K.N). • Total cost of Hot zone = O(1) + O(N.logN) + O(K.N) = O(N .max(log N, K))
Replication Criteria to be considered for a Replica Management system • Openness. The replicas should be useful to many requesters,not only a single user. • Locality. Obtaining a “nearby” replica is preferable. The actual distance (or cost) metric used may include dynamic parameters such as network and server load. • Addressability. For management, control, and updates, support should be provided for enumeration and individual or group-wise addressing of replicas.
Freshness. The replicas should be the most up to date version of the document. • Adaptivity. The number of replicas for a resource should be adaptable to demand, as a tradeoff between storage requirement and server load. • Flexibility. The number of replicas for one resource should not depend on the number of replicas for another resource • Variability. The locations of replicas should be selectable.
State size. The amount of additional state required for maintaining and using the replicas should be minimum. This applies to both distributed and centralized state. • Resilience. As DHTs themselves are completely distributed and resilient to outages, centralized state or other single points of failure should be avoided. • Independence. The introduction of a new replica (respectively, the removal of an existing replica) on a node should depend on as few other nodes as possible. • Performance. Locating a replica should not cause excessive traffic or delays.
Replica Enumeration - Dynamic Replica Management Algorithm Basic Idea: For each document with ID d, the replicas are placed at the DHT addresses determined by h(m; d), where m is the index, or number, of that particular replica, and h(; ) is the allocation function, typically a hash function, which is shared by all nodes The following four simple replica-placement rules govern the basic system behavior: 1) Replicas are placed only at addresses given by h(m; d). 2) For any document d in the system, there always exists an initial replica with m = 1 at h(1; d). 3) Any further replica (m > 1) can only exist if a replica currently exists for m- 1. 4) No document has more than R replicas (including the initial replica).
ADDITION of a replica • 1: /* Triggered by high load */ • 2: rd NumReplicas(d); /* using linear or binary search • */ • 3: Exclusively lock h(rd; d) to prevent removal, retry if • replica no longer exists; • 4: Create replica at h(rd + 1; d), ignore existing-replica • errors; • 5: Release lock on h(rd; d);
DELETION of Replica • 1: /* Run at replica having an underutilized document d */ • 2: Determine the replica index, m, for this replicated document; • 3: Exclusively lock the document h(m; d); • 4: /* Are we the last replica? */ • 5: if exists h(m + 1; d) then • 6: /* Cannot remove replica, would break rule 3 */ • 7: else • 8: Remove local replica; • 9: end if • 10: Release lock on h(m; d);
AWARE: Location-aware replica selection • 1: /* Locate a replica for document ID d */ • 2: r R; • 3: /* Calculate cost for each potential replica */ • 4: 8i 2 [1;R] : ci cost(h(i; d)); • 5: while r 1 do • 6: m index of minimal cost among ci; (i r); • 7: Request document with ID h(m; d); • 8: if request was successful then • 9: return document; • 10: end if • 11: r m 1; • 12: end while • 13: return nil;
K-PROBES: Location-unaware parallel probes • 1: r R; • 2: while r 1 do • 3: p min(k; r); /* Number of probes this turn */ • 4: P (p distinct random indices from [1; r]); • 5: 8i 2 P : Check for document h(i; d) in parallel; • 6: if any request was successful then • 7: return document retrieved from closest actual • replica; • 8: end if • 9: r min(8i 2 P) 1; • 10: end while • 11: return nil; • A
LOOKUP: Full lookup algorithm; handles unresponsive • nodes and timeouts • 1: r R; • 2: B ;; /* Blacklist of unresponsive nodes */ • 3: label retry; • 4: while r 1 do • 5: b min(k; j[1; r] n Bj); /* Number of probes */ • 6: P (b distinct indices from [1; r] n B); /* Pick • according to distance metric or randomly */ • 7: 8i 2 P : Send query for document h(i; d); • 8: Start timeout with period ; • 9: while fewer than min(b; q) replies processed this turn • do • 10: Wait for timeout or next reply; • 11: if timeout then • 12: B B [ P; • 13: goto retry; • 14: end if • 15: Y replica index of replying node; • 16: if reply was positive then • 17: if document retrieval successful then • 18: return document; • 19: end if • 20: else • 21: r min(r; Y 1); /* Never raise r again */ • 22: end if • 23: end while • 24: end while • 25: return nil; • IV.
Some Examples of Replica Management systems: • GlobeDB: Automatic Data replication for web applications. • GReplica: Web based data grid replica management system.
References [1]Andrew S. Tanenbaum & Maarten van Steen. (2007) Distributed Systems Principles and Paradigms (2nd Edition) Prentice Hall. [2]Swaminathan Sivasubramanian, Gustavo Alonso, Guillaume Pierre, and Maarten van Steen. GlobeDB: Autonomic data replication for Web applications. In 14th International World-Wide Web Conference, Chiba, Japan, May 2005. [3]T. Loukopoulos, P. Lampsas, and I. Ahmad, “Continuous replica placement schemes in distributed systems,” in Proceedings of the 19th ACM International Conference on Supercomputing (ACM ICS), Boston, MA, June 2005
References (continued) [4] Micha l Szymaniak, Guillaume Pierre, and Maarten van Steen. Latency-driven replica placement. In IEEE Symposium on Applications and the Internet, Trento, Italy, January 2005. [5] L. Qiu, V. Padmanabhan, and G. Voelker. On the Placement of Web Server Replicas. in Proceedings of IEEE INFOCOM, April 2001, pp. 1587–1596. [6] P. Radoslavov, R. Govindan, and D. Estrin, “Topology-Informed Internet Replica Placement,” Computer Communications, vol. 25, no. 4, pp. 384–392, March 2002. [7] Waldvogel, M., Hurley, P., and Bauer, D. Dynamic Replica Management in Distributed Hash Tables. IBM Research Report RZ-3502, July 2003.