Download
1 / 31
310 likes | 331 Views
Learn about reliability and validity in research methods, types of measurements, scales, and factors affecting reliability for advertising and public relations. Exam review for COM420.8.

E N D
Reliability and Validity Research Methods in AD/PR COMM 420.8 Fall 2007 Nan Yu
Exam 1 • Multiple choices (70%) • Short answer (30%) • Time: 9/27 (Thursday), 3:35-5:30p • Place: 143 Stuckeman • No made-up exams will be given if you miss the exam without a prior notice or a verifiable excuse.
Overview of Last Class • Levels of measurement • Nominal • Ordinal • Interval • Ratio • Types of measurement • Open-ended question • Likert-type scale • Thurstone scale • Semantic Differential scale
How to differentiate interval/ratio/ordinal variable? • How many hours do you watch TV everyday? ________hours • How many hours do you watch TV everyday? 1 2 3 4 5 6 7 8 9 hour hours • How many hours do you watch TV every day? • 0-2 • 3-5 • 5-7 • 7-9 • 9-11 • more than 11 hours
Nominal variable • Categories are mutually exclusive • Categories are exhaustive: all possible responses are provided (One individual case should fit in at least one category.) • Ethnicity • Caucasian • African American • Native American • Asian • Hispanic • Other
Likert-type scale • Likert-type scale • A neutral point is always provided Listening to heavy metal music makes one prone to violent acts. __Strongly agree __Agree __Neutral __Disagree __Strongly disagree How would you rate the quality of Daily Collegian? __poor__ unsatisfactory __neither unsatisfactory nor satisfactory __ satisfactory __ excellent Listening to heavy metal music makes one prone to violent acts. Strongly disagree Neutral Strongly agree -3 -2 -1 0 1 2 3
Semantic Differential Scales (bipolar) If the scale looks like this: Not at all Very much Likable 1 2 3 4 5 6 7 8 9 Good 1 2 3 4 5 6 7 8 9 Pleasant 1 2 3 4 5 6 7 8 9 Then what type of measurement is it now?
Corrections • http://www.personal.psu.edu/mbo1/forms/survey1/survey1.html • A few corrections • 0-25% 26%-50% 51%-75% 76-100% • ordinal, closed question • Gender 1=male, 2=female • nominal, closed question
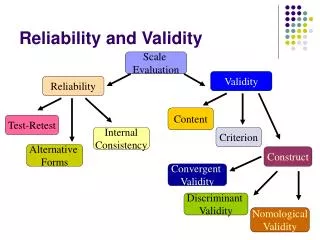
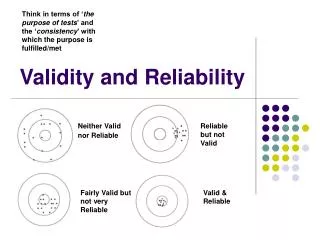
Reliability • The extend to which measurement are consistent, stable, dependable, predicable • Suggests that the same thing is repeated or recurs under identical or similar conditions • Every time you measure, you get similar or same data • Why reliability is important? • Guarantee the quality of your data • Replicability • E.g., degree in which replicating a study using the same procedures, the same instruments, etc. will lead to the same results
Factors that reduce reliability • Instrumental error • Double-barreled question • Do you like to watch and play basketball? • Application error • Instrument is used improperly • Random error • Unpredictable error
Types of Reliability • Test-retest reliability • Degree of matching between measurement results when the measurements are repeated • E.g., They are taken more than once, for the same object of measurement
Types of Reliability • Measurement item reliability • Internal consistency of several items • The degree in which a bunch of items stand together. • E.g., happiness measured by answering questions such as • “how thrilled you are?” 1 2 3 4 5 • “how happy you are?” 1 2 3 4 5 • “how cheerful you are?” 1 2 3 4 5 Answers to these three questions should be similar; it would mean that the happiness scale is reliable / it has internal consistency • Cronbach alpha: 0.7-0.9 (interval variable)
Types of Reliability • Inter-coder reliability • When a researcher has to code or interpret open-ended answers of the respondents, or news stories material, etc., his or her interpretation might be subjective and therefore, not completely reliable. • One way of dealing with this problem is to ask other individuals to “code” the same material. • Degree in which they agree upon the results of coding is inter-coder reliability • 90% of agreement, Cohen’s kappa, Scott’s pi.
Inter-coder reliability example • Imagine that three coders are asked to code the amount of violence on a certain televised program; they are given a coding sheet, explaining to them what they should consider as being violent. However, they do not always agree that certain acts or behaviors pertain to one of the violence descriptions. If they agree 87 percent of the time, the inter-coder reliability is of 87% (0.87).
How to improve reliability • Clearly conceptualize all constructs; reliability increases when a single construct or sub-dimension of a construct is measured • Increase the level of measurement; more precise levels of measurement are more likely to be reliable than less precise measures because the latter pick up less detailed information • Age • Young • Middle-aged • Old • Age 0-10 11-20 21-30 31-40 41-50 51-60 61+ • Age • What is your age?__________
How to improve reliability • Use multiple indicators of a variable; multiple indicator measures tend to be more stable than measures with one item • Sadness • gloom • sorrow • grief • unhappiness • Use pretests, pilot studies, and replication • trained observers/coders
Validity • Degree to which a measure “measures” what is supposed to measure (e.g., degree of matching between the concept and the measurement).
Content and Face Validity • Whether a measure captures the meaning of the variable being measured.
Face and Content Validity • Face validity • In face validity, you look at the operationalization and see whether "on its face" it seems like a good translation of the construct. • Example of lacking face validity • Use a ruler to measure weight • Use shoe size to measure intelligence • Content validity • Very similar to face validity • Needs careful operationalization of the concept. Researchers are the judges of measurement validity (face and content).
Criterion Validity • Criterion validity • Uses some standard or criterion to indicate a construct accurately. • “concurrent validity” and “predictive validity”
Types of Criterion Validity • Concurrent validity: • a measure (indicator) must be associated with a preexistent one that is judged to be valid. • E.g. GRE • Predictive validity: • indicator predicts future events that are logically related to a construct is called predictive validity. • E.g. SAT and college academic performance
Construct validity • Construct validity refers to the degree to which inferences can legitimately be made from the operationalizations in your study to the theoretical constructs on which those operationalizations were based. • Convergent validity • Discriminant validity (Divergent validity)
Construct validity • Convergent validity (multiple-item measures) • Applies when multiple indicators converge or are associated with one another. • you should be able to show a correspondence or convergence between similar constructs • Convergent validity means that multiple measures of the same construct hang together or operate in similar ways.
Discriminant validity • Discriminant validity • measures of constructs that theoretically should not be related to each other are, in fact, observed to not be related to each other • you should be able to discriminate between dissimilar constructs • you are measuring what you want to measure, not something else.
Internal Validity • Internal validity • Degree to which one can prove causation • Practically, degree to which you can eliminate third variables or confounds.
External Validity • External validityDegree to which one can generalize the conclusions of the study from the sample used in the study to the overall population. generalize
Relationship betweenreliability and validity (p. 143-144) • “Reliability must be present or validity is impossible.” • Reliability is a necessary condition for validity, but not sufficient. • Even the measure turns to be reliability, it may not measure what you want to measure --lack of validity
In-Class Demo 1 and 2 • Download the file “in-class demo 1” and “1-class demo 2” in “week 5” folder on ANGEL • Complete both of them • Submit your answers to the corresponding drop boxes in “week 5” folder on ANGEL • Answers of are also in the “week 5” folder.