Download

1 / 12
180 likes | 343 Views
Linear Hashing. Appendix for Chapter 1. Linear Hashing. Allow a hash file to expand and shrink dynamically without needing a directory. Suppose the file starts with M buckets numbered 0,1,…,M -1 and used h(K) = K mod M. This hash function is called initial hash function h i .

E N D
Linear Hashing Appendix for Chapter 1
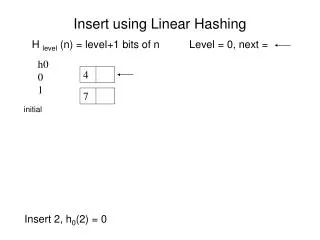
Linear Hashing • Allow a hash file to expand and shrink dynamically without needing a directory. • Suppose the file starts with M buckets numbered 0,1,…,M -1 and used h(K) = K mod M. This hash function is called initial hash function hi. • Overflow can be handled by maintaining individual overflow chains for each bucket. • When a collision leads to an overflow record in any file bucket, bucket 0 is split into 2 buckets: the original bucket 0 and a new bucket M at the end of the file. • The records originally in bucket 0 are distributed between the two buckets based on hi+1(K)=K mod 2M. • Any records that hashed to bucket 0 based on hi will hash to either bucket 0 or bucket M based on hi+1.
Linear Hashing (cont.) • With further overflow records, additional buckets are slit in the linear order 1,2, 3, 4,… • If enough overflows occur, all the original buckets 0,1,…,M-1 will have been split, so the file now has 2M instead of M buckets and all buckets use the hash function hi+1. • Hence, the records in overflow are redistributed into regular buckets, using hi+1. • There is a value n – which is initially set to 0 and is incremented by 1 whenever a split occurs – is needed to determine which buckets have been split. • To retrieve a record with hash key value K, first apply hi to K; if hi(K) < n, then apply the function hi+1 on K because the bucket is already split. Initially, n = 0, indicating hi applies to all buckets. • When n = M, this means that all the original buckets have been split and hi+1 applies to all records in the file. At this point, n is reset to 0, and any collisions lead to overflow lead to the use of a new hash function hi+2(K) = K mod 4M.
Linear Hashing (cont.) • In general, hi+j(K) = K mod(2jM), where j =0,1,2…. • A hash function is needed whenever all the buckets 0,1,2,…,(2jM)-1 have been split and n is reset to 0. • Splitting can be controlled by monitoring the file load factor: l = r/(bfr*N) where r is the current number of records, bfr is the max number of records that can fit in a bucket and N is the current number of file buckets. • Split can be triggered when the load of the file exceeds a certain threshold (e.g. 0.9) • Buckets that have been split can also be combined if the load of the file falls below a given threshold (e.g. 0.7)
The search procedure for linear hashing if n = 0 then m hj(k) else begin m hj(k); if m < n then m hj+1(k) end; search the bucket whose hash value is m (and its overflow, if any);