Download

1 / 28
280 likes | 452 Views
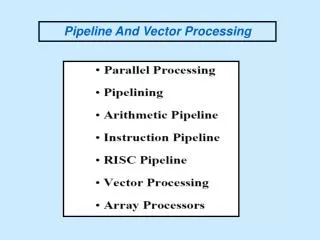
Pipelined Vector Processing and Scientific Computation John G. Zabolitzky. Applications of High-Performance Computing. Weather prediction, climatic simulation fluid dynamics simulation (aerodynamics for aerospace, automobile, combustion, ....) basic science cosmology

E N D
Pipelined Vector Processing and Scientific ComputationJohn G. Zabolitzky Eine Zeitreise in die Welt der Computer.
Applications of High-Performance Computing • Weather prediction, climatic simulation • fluid dynamics simulation (aerodynamics for aerospace, automobile, combustion, ....) • basic science • cosmology • quantum mechanical many-body problems • chemistry • solid-state • quantum fluids • high-energy physics • cryptography • weapons research • energy research • nuclear reactor simulation • fusion research • many many more Eine Zeitreise in die Welt der Computer.
Terminal State of Scalar Computing: CDC 7600, 1968 • Maximum RISC performance of 1 operation/cycle achieved • No further improvement possible without change of paradigm • 36 MHz => 36 MIPS => 5 MFLOPS real Eine Zeitreise in die Welt der Computer.
Pipelined Scalar Execution Eine Zeitreise in die Welt der Computer.
Scalar Code Example • DO i=1,100 a(i)=b(i)*c(i) • load b, inc addesss • load c, inc address • multiply • store a, inc address • decrement count, loop? • 5 instructions = cycles (optimum) for one multiply • pipelined multiply: could start one multiply each and every cycle => only 20% efficient use • expensive multiplier sits idle most of the time Eine Zeitreise in die Welt der Computer.
Architectural Alternatives • * Pipelined Scalar (RISC) as outlined before • * Pipelined Vector (this presentation further down) • * SIMD (Single Instruction Multiple Data) parallel arithmetic (e.g., ILLIAC IV) • too expensive, inefficient: larger number of lightly used multipliers • * Superscalar = multiple issue in one cycle • all modern single-chip CPUs (Intel to TI); keep all functions busy • * VLIW (Very Long Instruction Word) = Variant of Superscalar • * MIMD (Multiple Instruction Multiple Data) true parallel streams, e.g. Cray T3E, IBM Blue Gene, IBM Cell: may be superimposed on top of ANY CPU architecture Eine Zeitreise in die Welt der Computer.
Vector Computation • Scientific codes have high percentage in looping over simple data structures • DO i=1,100 a(i) = b*c(i) + d(i) • simple logical structure ==> • set up such that one multiply/cycle • one instruction for entire loop • MFLOP rate = cycle rate or multiple thereof • specialized for scientific/engineering tasks Eine Zeitreise in die Welt der Computer.
Vector Pipeline c(i)=a(i)*b(i) Inventor: Henry Ford Eine Zeitreise in die Welt der Computer.
Need to Vectorize; some automatic, high quality requires hand-optimization • Naive scalar code for matrix multiply • s=0.0 • do j=1,n • s=s+a(i,j)*b(j,k) • Recursive on s => adder pipeline blocked • vector code for matrix multiply • do i=1,n • c(i,k) = c(i,k) + a(i,j)*b(j,k) • Independent vector elements, but 1.5x bandwidth • Frequently good idea: exchange inner/outer loop Eine Zeitreise in die Welt der Computer.
First Vector Computers • Control Data Corporation (CDC) STAR-100 [STring ARray 100 MFLOPS] • memory-to-memory architecture • therefore long startup times (~n00 cycles) • very slow scalar unit (~2 MFLOPS) • overall disappointing performance • contracted 1967, announced 1972, delivered 1974 • total of 4 machines, 2 Lawrence Livermore Lab • Thornton (CDC) and Fernbach (LLL) loose their jobs Eine Zeitreise in die Welt der Computer.
CDC STAR-100 Photograph courtesy of Charles Babbage Institute, University of Minnesota, Minneapolis Eine Zeitreise in die Welt der Computer.
Texas Instruments ASC • Advanced Scientific Computer, early 1970s • architecturally similar to CDC STAR-100 • 7 units sold • TI dropped out of mainframe computer manufacturing after this machine Eine Zeitreise in die Welt der Computer.
Vector Performance I • MFLOP rate (MFLOPS) as function of vector length n • scalar: ~constant (only some loop overhead, then n * loop time) • vector: (n = length of vector) • # cycles = startup + n / nflop_per_cycle • rate/clock = #ops / #cycles ~ n / (startup + n) • half rate at vectorlength n ~ startup • full rate needs n >> startup => “Long Vector Machine” Eine Zeitreise in die Welt der Computer.
Performance vs. Startup, Length Eine Zeitreise in die Welt der Computer.
Vector Performance II • Vector/Scalar Subsections • ALL codes have some scalar (non-vectorizable) sections • total time = (scalar fraction)/(scalar rate) + (vector fraction)/(vector rate) • example: 10% / 1 MFLOPS + 90% / 100 MFLOPS = • 100 / (0.1 * 100 + 0.9 * 1) = 9.2 MFLOPS !!! Eine Zeitreise in die Welt der Computer.
Vector Version of Amdahl’s Law Eine Zeitreise in die Welt der Computer.
Vector Computer Design Guide • Must have SHORT vector startup => can work with short vectors • Must have FASTEST POSSIBLE scalar unit => can afford scalar sections • irregular data structures ==> need gather, scatter, merge operations (and a few more) • x(i) = a(index(i)) * b(i) • y(index(i)) = c(i) + d(i) • where (a(i) > b(i)) c(i) = d(i) Eine Zeitreise in die Welt der Computer.
Cray Research, Inc. • Founded by Seymour Cray (father of CDC 6600/7600) in 1972 (STAR-100 known) • first Cray-1 delivered in 1976 to Los Alamos Scientific Laboratory (LASL) • 8 vector registers of 64 elements each • Vector load/store instructions • fastest scalar computer of its time • 160 MFLOPS peak rate ( 2 ops/cycle @ 80 MHz), few cycles startup Eine Zeitreise in die Welt der Computer.
Seymour Cray Cray-1 1976 Single Processor 80 MFLOPS 1 Mword = 8 Mbyte Photograph courtesy of Charles Babbage Institute, University of Minnesota, Minneapolis Eine Zeitreise in die Welt der Computer.
Large working set: - 8 vector registers, 64 words - 8 scalar registers - 8 address registers - large instruction buffer Performance Features: - vector processing: one operation affects 64 vector elements, streamed through functional unit - small vector startup time - chaining between vector ops - large, fast semiconductor memory Eine Zeitreise in die Welt der Computer.
Cray Research, Inc. cnt’d • 1982 Cray-XMP (Steve Chen improvements, up to 4 processors, shared memory) • 1985 Cray-2, 256 Mword memory, 4 processors, immersion cooled • 1988 Cray-YMP (last Chen machine) • 1991 Cray C90 (up to 16 vector CPUs, shared memory) • 1993 Cray T3D (massively parallel Alpha) • one and only Cray-3 delivered to NCAR (Cray Comp Corp) • 1994 Cray J90 (up to 32 vector CPUs, shared memory), air cooled • 1995 Cray T3E (most successful MPP machine), Cray T90 (parallel vector, immersion cooled) • Cray-4 abandoned (Cray Computer Corporation ch. 11) • 1996 acquired by Silicon Graphics • 1998 Cray SV1 (parallel vector, air cooled) • 1999 acquired by Teradata => Cray, Inc. • 2002 Cray X1, parallel vector, immersion spray cooled • 2004 Cray X1e, enhanced version of X1 • Cray XT3, AMD based 3D Torus massively parallel machine Eine Zeitreise in die Welt der Computer.
CDC Cyber 200 Family • - 1980, enhanced version of STAR-100 • - reduced startup time, ~ 50 cycles • - fast scalar unit • - rich instruction repertoire • - still memory-to-memory, 400 MFLOPS peak • - Cyber 203, Cyber 205, ETA-10 [10 GFLOPS] • - vector FORTRAN language extensions provided • - terminated in 1989 since unprofitable • - around 40 Cyber 200, 34 ETA-10 sold Eine Zeitreise in die Welt der Computer.
Minnesota Supercomputer Center Minneapolis, 1986 Cray-2, CDC Cyber 205 Eine Zeitreise in die Welt der Computer.
NEC Japan • - 1983 SX-1 single processor vector 650 MFLOPS • - 1985 SX-2 single processor vector 1300 MFLOPS • - 1990 SX-3 four processors at ~ 5 GFLOPS each, 4 Gbyte = 0.5 Gword memory • - 1995 SX-4 32 processors at ~ 2 GFLOPS each (CMOS; all previous ECL) • - 1998 SX-5 upto 512 processors 8 GFLOPS each • - 2002 SX-6 upto 1024 processors 8 GFLOPS each • - 2004 SX-7 upto 2048 processors 8.8 GFLOPS each • - 2004 SX-8 upto 4096 processors 16 GFLOPS each Eine Zeitreise in die Welt der Computer.
IBM - Sony - Toshiba CELL processor - 8 vector CPUs + GPU on single chip - 256 kbyte = 32 kword local storage (very small !!) - 12 word/cycle internal interconnect = 386 Gbyte/sec - 24 Gbyte/sec = 3 Gword/sec main memory - 76 Gbyte/sec = 9.5 Gword/sec communication - @ 4 GHz clock 256 GFLOPS (32 bit) peak - 26 GFLOPS (64 bit) peak - max 4.5 Gbyte addressable, 512 Mbyte implemented - system interconnect ? - used within Sony Playstation 3 - Mercury, IBM blades available; 512 Mbyte only - highly imbalanced for scientific computation Eine Zeitreise in die Welt der Computer.
IBM - Sony - Toshiba CELL processor - 90 nm SOI, 8 layers Cu interconnect - 234 M Transistors - 221 mm² die size - significant potential in future revisions - but: 80W @ 1.1V 4.0 GHz is too much - 180W @ 1.4V 5.6 GHz is much too much - work needed in power reduction - larger internal memory - 64 bit arithmetic improved Eine Zeitreise in die Welt der Computer.
IBM - Sony - Toshiba CELL processor From: S. Williams et. al., Lawrence Berkeley Laboratory - single Cell chip performance - compared with Cray X1E single vector processor and several commodity microprocessors (AMD, Intel) - already current version shows impressive speedup, at cost of significant programming complexity (explicit storage moves as opposed to caching) - slightly enhanced Cell (Cell+) simulation provides very significant additional speedup (more efficient DP) - current version insufficient for major impact - future versions may change that, great potential Eine Zeitreise in die Welt der Computer.