Download

1 / 36
360 likes | 424 Views
A New Algorithm of Fuzzy Clustering for Data with Uncertainties: Fuzzy c -Means for Data with Tolerance Defined as Hyper-rectangles. ENDO Yasunori MIYAMOTO Sadaaki. Outline. Background and goal of our study The concept of tolerance New clustering algorithms for data with tolerance

E N D
A New Algorithm of Fuzzy Clustering for Data with Uncertainties:Fuzzy c-Means for Data with Tolerance Defined as Hyper-rectangles ENDO Yasunori MIYAMOTO Sadaaki
Outline • Background and goal of our study • The concept of tolerance • New clustering algorithms for data with tolerance • Numerical examples • Conclusion and future works
Introduction Clustering is one of the unsupervised automatic classification. Classification methods classify a set of data into several groups. Many clustering algorithms have been proposed and fuzzy c-means (FCM) is the most typical method of fuzzy clustering. In this presentation, I would like to talk about one way to handle the uncertainty with data and present some new clustering algorithms which are based on FCM.
Uncertainty In clustering, each data on a real space is regarded as one point in a pattern space and classified. However, the data with uncertainty should be often represented not by a point but by a set.
Three examples of data with uncertainty • Example 1: Data has errors When a spring scale of which the measurement accuracy is plus/minus 5g shows 450g, an actual value is in the interval from 445g to 455g.
Three examples of data with uncertainty • Example 2: Data has ranges An apple has not only one color but also a lot of colors so that colors of the apple couldnot be represented as one point on color space.
Three examples of data with uncertainty • Example 3: Missing values exist in data In case of a social investigation, if there are unanswered items in the questionnaire, the items are handled as missing values.
Background In the past, these uncertainties of data have been represented as intervaldata. Some algorithms for interval data have been proposed (e.g., Takata and Miyamoto[1]). In those algorithms, dissimilarity is defined between interval data by using particular measures, e.g., nearest-neighbor, furthest-neighbor or Hausdorff distance.
Background The methodology of interval has the following disadvantages: We have to introduce a particular measure. But how do we select the adequate measure? Actually, only boundary of interval data is handled by these measures.
Goal of our study From a view point of strict optimization problem, we handle uncertainty as tolerance and consider the new type of optimization problem for the data with tolerance. Moreover, we construct new clustering algorithms in the optimization framework. In these algorithms, dissimilarity is defined between target data by using L1or squared L2 norm.
Features of proposed algorithms The methodology of tolerance has the following advantages: • Particular distances between intervals don’t have to be defined. • Not only the boundary but also all region in tolerance is handled. • Our discussion becomes mathematically simpler than using interval distances.
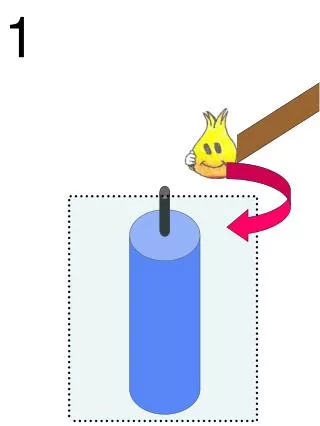
The concept of tolerance We define as the -th data on a dimensional vector space , and as the tolerance vector of . The constraint condition is shown by following expression.
An example of tolerance vector on R : Tolerance It is decided before calculate. : Tolerance vector It is calculated in algorithm.
Comparison of Tolerance and Other Measures Nearest-neighbor method Furthest-neighbor method Proposed method
Conventional fuzzy c-means sFCM: standard fuzzy c-means ….. Number of clusters ….. Number of data ….. Number of dimensions of the pattern space ….. Membership grade ….. Data ….. Cluster center
Optimization problem: sFCM-L2 • Objective function: • Membership grade U : • Cluster center V :
Algorithm: sFCM-L2 • Step1 Set the initial value of V . • Step2 Update U by . • Step3 Update V by . • Step4 If is convergent, stop. Otherwise, go back to Step2.
Proposed algorithms The constraint condition:
An example of tolerance vector on R : Tolerance It is decided before calculate. : Tolerance vector It is calculated in algorithm.
Optimization problem: sFCMT-L2 • Objective function: • Membership grade U : • Cluster center V :
Optimization problem: sFCMT-L2 • Tolerance vector E :
Algorithm: sFCMT-L2 • Step1 Set the initial values of V and E. • Step2 Update U by . • Step3 Update V by . • Step4 Update E by . • Step5 If is convergent, stop. Otherwise, go back to Step2.
Diagnosis of heart disease data • Heart disease database has five attributes. The result of diagnosis, presence or absence is known. The number of data is 866 and 560 data contains missing values in some attributes.
Diagnosis of heart disease data • In all algorithms, the convergence condition is where is the previous optimal solution. In addition, in sFCM. • To handle missing values as tolerance, we define it as follows.
Diagnosis of heart disease data • We try to classify all 866 data with missing values by using proposed algorithms, and only 306 data without missing values by using conventional algorithms. • In each algorithm, we give initial cluster centers at random and classify the data set into two clusters. We run this trial 1000 times and show the average of ratio of correctly classified results.
Diagnosis of heart disease data • This tables shows the results of classifying only 306 data without missing values. • This table shows the results of classifying all 866 data.
Diagnosis of heart disease data • This table shows the results of classifying all 866 data by using the proposed algorithms in our research. • This table shows the results of classifying all 866 data by using an algorithm which handles missing value as interval data and uses nearest-neighbor distance to calculate dissimilarity.
Conclusion and future works • Conclusion • We considered the optimization problems for data with tolerance and solved the optimal solutions. Using the results, we have constructed new six algorithms. • We have shown the effectiveness of the proposed algorithms through some numerical examples.
Conclusion and future works • Future works • We will calculate other data sets with tolerance. • We will apply the concept of tolerance to regression analysis, support vector machine and so on.
References 1.Osamu Takata, Sadaaki Miyamoto : “Fuzzy clustering of Data with Interval Uncertainties”, Journal of Japan Society for Fuzzy Theory and Systems, Vol.12, No.5, pp.686-695 (2000) (in Japanese)