Download

1 / 16
160 likes | 322 Views
RAMCloud Scalable High-Performance Storage Entirely in DRAM.

E N D
RAMCloudScalable High-Performance Storage Entirely in DRAM John Ousterhout, ParagAgrawal, David Erickson, Christos Kozyrakis, Jacob Leverich, David Mazières, SubhasishMitra, Aravind Narayanan, Guru Parulkar, Mendel Rosenblum, Stephen M. Rumble, Eric Stratmann, and Ryan Stutsman Stanford University Presented by Sangjin Han (many slides are stolen from https://ramcloud.stanford.edu)
Features (or Goals) • Low latency: 5-10 µs (not milliseconds) • High throughput: 1M operations/s • Key-value storage with 1000s of servers • No replicas • Entirely in DRAM • Disks only for backup • Fast recovery (1-2 secs)
Data Model create(tableId, blob)=>objectId, version read(tableId, objectId)=> blob, version write(tableId, objectId, blob)=> version cwrite(tableId, objectId, blob, version)=> version delete(tableId, objectId) Tables Object Identifier (64b) (Only overwrite ifversion matches) Version (64b) Blob (≤1MB) RAMCloud Overview & Status
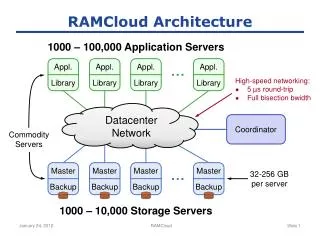
Overall Architecture 1000 – 100,000 Application Servers … Appl. Appl. Appl. Appl. Library Library Library Library DatacenterNetwork Coordinator Master Master Master Master Backup Backup Backup Backup 32-64GB/server … 1000 – 10,000 Storage Servers
Per-Node Architecture • One server per data • 2-3 backups for buffered logging
Coordinator • Centralized server for data placement • E.g, • Clients obtain a map from the coordinator • And cache
Fast Recovery (First Try) RecoveryMaster • Reconstruct data from backup logs • Bottleneck: disk B/W • Solution: more disks Backups Crashed Master
Fast Recovery (Second Try) • Randomly distribute log shards • Bottleneck: recovery master • Solution: no single recovery master CrashedMaster RecoveryMaster ~1000Backups
Fast Recovery (Third Try) • Temporarily distributed recovery masters • Happy? • 35 GB recovery in 1.6s using 60 nodes (SOSP 2011) CrashedMaster RecoveryMasters Backups
Publication History • Unveiling: SOSP 2009 WIP • White paper: Operating Systems Review 2009 • What you read • (Call for) low latency: HotOS 2011 • Fast recovery: SOSP 2011 • Ongoing work: index, transaction, transport, … • Visit http://ramcloud.stanford.edu
Thoughts & Discussion • Garbage collection? • Infiniband vs. Ethernet • HW support for transport layer? • Killer app? • Non volatile memory? • Synchronous vs. asynchronous query • Moving data vs. Moving code • How many papers out of this project? :P
SORRY • My English still s^^ks • Would you repeat the question • SLOWLY and • CLEARLY ???