Download

1 / 17
170 likes | 314 Views
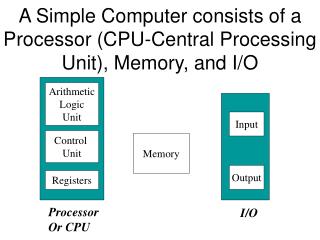
Revisiting the Processor Arvind Computer Science & Artificial Intelligence Lab Massachusetts Institute of Technology. An unpipelined multicycle architecture. Only one instruction at a time. RFile. pc. PCGen. Exec. WB. dstReg. DCache. ICache. The Multi-stage Design.

E N D
Revisiting the Processor Arvind Computer Science & Artificial Intelligence Lab Massachusetts Institute of Technology
An unpipelined multicycle architecture Only one instruction at a time RFile pc PCGen Exec WB dstReg DCache ICache
The Multi-stage Design • 3 Rules (one for each stage) • 1 instruction active at a time • 2-3 stages / instruction • Little inter-stage buffering • Multi-cycle memory interface
Rules for multistage/multicycle design rule pcgen(stage == PC); imemReq.enq(Rd{a:pc}); stage <= EX; endrule rule exec(stage == EX); let inst = imemResp.first(); imemResp.deq(); match {.nextpc, .rf_cmd, .mem_cmd} = doInst(pc,inst,rf); pc <= nextpc; case (rf_cmd) matches tagged RF {.dst,.val}: rf.upd(dst,val); endcase case (mem_cmd) matches tagged Ld {.dst,.addr}: begin dmemReq.enq(Rd{a:addr}}; dstReg <= dst; end tagged St {.addr,.val}: dmemReq.enq(Wr{a:addr,v:val}); endcase stage <= (mem_cmd matches tagged Ld .*)? WB: PC; endrule rule writeback (stage == WB); let dresp = dmemResp.first(); dmemResp.deq(); case (dresp) matches tagged RdResp {.val}: rf.upd(dstReg, val); endcase stage <= PC; endrule case (inst) …
Discussion Point s • Can these 3 rules be combined into one rule? • No, memory takes multiple cycles • What will happen if we forgot to dequeue (imemResp)? • System will get stuck • Eventually, PCgen can not longer fire
Pipelining the Design RFile Step 1: Insert buffers pc PCGen Exec WB dstReg DCache ICache
Pipelining the Design 2 It is problematic to write RFile from two stages: structural hazards & possible out-of-order writes(and reads) to RFile RFile pc PCGen Exec WB Step 2: delay all RFile writes to WB stage (Requires passing dst-val pairs to WB stage. Subsumes dstReg) DCache ICache
Pipelining the Design 3 PC is read by PCGen and written by Exec. No parallelism without PC speculation RFile pc PCGen Exec WB epoch If speculation fails, we must reset the PC and discard false path instructions (may take many cycles) DCache ICache Epochs to identify to which speculative path an instruction belongs
Pipelining the Design 4 Final concern: Data hazards RFile pc Exec PCGen WB epoch DCache ICache
Isolating RFile Port Usage rule pcgen(stage == PC); imemReq.enq(Rd{a:pc}); stage <= EX; endrule rule exec(stage == EX); let inst = imemResp.first(); imemResp.deq(); match {.nextpc, .rf_cmd, .mem_cmd} = doInst(pc,inst,rf); pc <= nextpc; case (rf_cmd) matches tagged RF {.dst,.val}: rf.upd(dst,val); endcase case (mem_cmd) matches tagged Ld {.dst,.addr}: begin dmemReq.enq(Rd{a:addr}}; dstReg <= dst; end tagged St {.addr,.val}: dmemReq.enq(Wr{a:addr,v:val}); endcase stage <= (mem_cmd matches tagged Ld .*)? WB: PC; endrule rule writeback (stage == WB); let dresp = dmemResp.first(); dmemResp.deq(); case (dresp) matches tagged RdResp {.val}: rf.upd(dstReg, val); endcase stage <= PC; endrule case (inst) … … Reg2RegOp: …wbData <= RF{dst,val};… LoadOp: …wbData <= Ld{dst};… Suppose we use a wbData register to pass information to the WB stage about updating the RFile rule writeback (stage == WB); case (wbData) matches tagged RF {.dst,.val}: rf.upd(dst,val); tagged Ld {.dst}: begin let dresp = dmemResp.first(); dmemResp.deq(); rf.upd(dst,memVal(dresp)); end endcase stage <= PC; endrule
Rules for the Pipelined machine rule pcgen; imemReq.enq(Rd{a:pc}); pc <= predPC; pcQ.enq(tuple2(pc,epoch)); endrule rule discard (epoch != eEpoch); pcQ.deq(); imemResp.deq(); endrule rule exec ((epoch != eEpoch)&& !(stall(inst,wbQ))); case based on the fetched instruction rule writeback (True); wbQ.deq(); case (wbQ.first()) matches tagged RF {.dst,.val}: rf.upd(dst,val); tagged Ld {.dst}: begin let dresp = dmemResp.first(); dmemResp.deq(); rf.upd(dst, memVal(dresp)); end endcase endrule
The Execute Rule let inst = imemResp.first(); match {.predPC,.eEpoch} = pcQ.first(); rule exec(epoch == eEpoch && !stall(inst, wbQ)); pcQ.deq(); imemResp.deq(); match {.nextPC, .rf_cmd, .mem_cmd} = doInst(pc,inst,rf); if(predPC!=nextPC) begin pc <= nextPC; epoch<= epoch+1; end case (tuple2(rf_cmd, mem_cmd)) matches {tagged RF {.dst,.val}, .*}: wbQ.enq(RF{dst,val}); {.*, tagged Ld {.dst,.addr}}: begin wbQ.enq(Ld{dst,addr}); dmemReq.enq(Rd{a:dst}}; end {.*, tagged St {.addr,.val}}: begin wbQ.enq(St); dmemReq.enq(Wr{a:addr,v:val}); end endcase endrule
Design Flow • Are these rules correct? I.e. do they produce the correct results regardless of the order in which they are executed • test – fix – test – fix …. • Run the design and look at the traces to understand concurrency • traces tell you what is happening at each cycle but not why something is not happening • Does your design permit “concurrent firings”, i.e., multiple instructions in the pipeline • Compiler output can tell you • Can multiple guards be true simultaneously? • Structural conflicts? • Permitted rule orderings within a cycle • You may want to split a rule into multiple rules
Top down concurrency analysis • Determine the concurrent rule firings and rule ordering you want • To hand analysis to determine the required concurrent behavior of methods of submodules. • If this behavior is prohibited by a submodule, create a submodule with the desired behavior • this may require Rwires and ConfigRegs
Branch Prediction • Pipeline has simple speculation rule pcGen (True); pc <= pc + 4; otherActions; endrule Simplest prediction: Always not-taken
Branch Predictors RFile pred pc Exec PCGen WB epoch DCache ICache
Branch Prediction Make prediction interface BranchPredictor; method Addr getNextPC(Addr pc); method Action update (Addr pc, Addr correct_next_pc); endinterface rule pcGen (True); pc <= pred.getNextPC(pc); otherActions; endrule rule execute … if (nextPC != correctPC) pred.update(curPc, nextPC); case (instr) matches … BzTaken: if (mispredicted) … endrule Update predictions