Download

1 / 15
150 likes | 321 Views
The NUMAchine Multiprocessor. ICPP 2000. Outline. Presentation Overview. Architecture System Overview Key Features Fast ring routing Hardware Cache Coherence Memory Model: Sequential Consistency Simulation Studies Ring performance Network Cache performance Coherence overhead

E N D
The NUMAchine Multiprocessor ICPP 2000
Outline Presentation Overview • Architecture • System Overview • Key Features • Fast ring routing • Hardware Cache Coherence • Memory Model: Sequential Consistency • Simulation Studies • Ring performance • Network Cache performance • Coherence overhead • Prototype Performance • Hardware Status • Conclusion
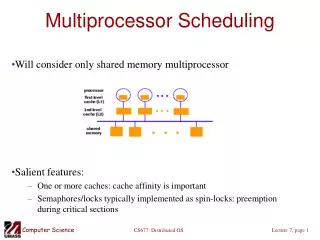
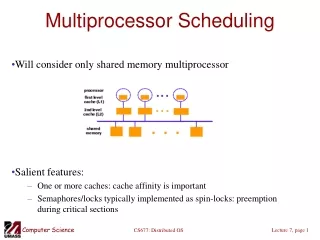
Arch:Sys System Architecture • Hierarchical ring network, based on clusters ( NUMAchine’s ‘Stations’) which are themselves bus-based SMPs
Arch:Features NUMAchine’s Key Features • Hierachical rings • Allow for very fast and simple routing • Provide good support for broadcast and multicast • Hardware Cache Coherence • Hierarchical, directory-based, CC-NUMA system • Writeback/Invalidate protocol, designed to use the broadcast/ordering properties of rings • Sequentially Consistent Memory Model • The most intuitive model for programmer’s trained on uniprocessors • Simple, low cost, but with good flexibility, scalability and performance
Arch:Fmask Fast Ring Routing: Filtermasks • Fast ring routing is achieved by the use of Filtermasks (I.e. simple bit-masks) to store cache-line location information (imprecision reduces directory storage requirements) • These Filtermasks are used directly by the routing hardware in the ring interfaces
CC Hardware Cache Coherence • Hierarchical, directory-based, writeback/invalidate • Directory entries are stored in both the per-station memory (‘home’ location), and cached in the network interfaces (hence the name, Network Cache) • The Network Cache stores both the remotely cached directory information, as well as the cache lines themselves, and allows the network interface to perform coherence operations locally (on-Station), avoiding remote accesses to the home directory • Filtermasks indicate which Stations (I.e. clusters) may potentially have a copy of a cache line (with the fuzziness due to the imprecise nature of the filter masks) • Processor Masks are used only within a Station, to indicates which particular caches may contain a copy (with the fuzziness here due to Shared lines that may have been silently ejected)
SC Memory Model: Sequential Consistency • The most intuitive model for the normally trained programmer: increases the usability of the system • Easily supported by NUMAchine’s ring network: the only change necessary is to force invalidates to pass through a global ‘sequencing point’ on the ring, increasing the average invalidation latency by 2 ring hops (40 ns with our default 50 MHz rings)
SS:RP1 Simulation Studies: Ring Performance 1 • Use the SPLASH-2 benchmarks suite, and a cycle-accurate hardware simulator with full modeling of the coherence protocol • Applications with high communication-to-computation ratios (e.g. FFT, Radix) show high utilizations, particularly in the Central Ring (indicating that a faster Central Ring would help)
SS:RP2 Simulation Studies: Ring Performance 2 • Maximum and average ring interface queue depths indicate the network congestion, which correlates to bursty traffic • Large differences between the maximum and average values indicates large variability in burst size
SS:NC Simulation Studies: Network Cache • Graphs show a measure of the Network Cache’s effect by looking at the hit rate (I.e. reduction in remote data and coherence traffic) • By categorizing the hits by the coherence directory state, we also see where the benefits come from: caching shared data, or reducing invalidations and coherence traffic
SS:CO Simulation Studies: Coherence Overhead • Measure the overhead due to cache coherence, by allowing all writes to succeed immediately without checking cache-line state, and comparing against runs with the full cache coherence protocol in place (both using infinite-capacity Network Caches to avoid measurement noise due to capacity effects) • Results indicate that in many cases it is basic data locality and/or poor parallelizability that are impeding performance, not cache coherence
PP Prototype Performance • Speedups from the hardware prototype, compared against estimates from the simulator
Status Hardware Prototype Status • Fully operational running the custom Tornado OS, with a 32-processor system shown below
Fin Conclusion • 4- and 8-way SMPs are fast becoming commodity items • The NUMAchine project has shown that a simple, cost-effective, CC-NUMA multiprocessor can be built using these SMP building blocks and a simple ring network, and still achieve good performance and scalability • In the medium-scale range (a few tens to hundreds of processors), rings are a good choice for a multiprocessor interconnect • We have demonstrated an efficient hardware cache coherence scheme, which is designed to make use of the natural ordering and broadcast capabilities of rings • NUMAchine’s architecture efficiently supports a sequentially consistent memory model, which we feel is essential for increasing the ease of use and programmability of multiprocessors
Ack Acknowledgments: The NUMAchine Team • Hardware • Prof. Zvonko Vranesic • Prof. Stephen Brown • Robin Grindley (SOMA Networks) • Alex Grbic • Prof. Zeljko Zilic (McGill) • Steve Caranci (Altera) • Derek DeVries (OANDA) • Guy Lemieux • Kelvin Loveless (GNNettest) • Prof. Sinisa Srbljic (Zagreb) • Paul McHardy • Mitch Gusat (IBM) • Operating Systems • Prof. Michael Stumm • Orran Krieger (IBM) • Ben Gamsa • Jonathon Appavoo • Robert Ho • Compilers • Prof. Tarek Abdelrahman • Prof. Naraig Manjikian (Queens) • Applications • Prof. Ken Sevcik