Download

1 / 37
370 likes | 600 Views
Matrices, Digraphs, Markov Chains & Their Use by Google. Leslie Hogben Iowa State University and American Institute of Mathematics. Bay Area Mathematical Adventures February 27, 2008. With material from Becky Atherton. Outline. Matrices Markov Chains Digraphs Google’s PageRank.

E N D
Matrices, Digraphs, Markov Chains & Their Use by Google Leslie Hogben Iowa State University and American Institute of Mathematics Bay Area Mathematical Adventures February 27, 2008
With material from Becky Atherton Outline • Matrices • Markov Chains • Digraphs • Google’s PageRank
Introduction to Matrices • A matrix is a rectangular array of numbers • Matrices are used to solve systems of equations • Matrices are easy for computers to work with
Matrix arithmetic • Matrix Addition • Matrix Multiplication
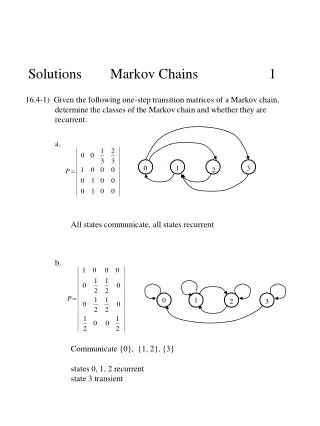
Introduction to Markov Chains • At each time period, every object in the system is in exactly one state, one of 1,…,n. • Objects move according to the transition probabilities: the probability of going from state j to state i is tij • Transition probabilities do not change over time.
The transition matrix of a Markov chain • T = [tij] is an nn matrix. • Each entry tij is the probability of moving from state j to state i. • 0 tij 1 • Sum of entries in a column must be equal to 1 (stochastic).
Example:Customers can choose from three major grocery stores: H-Mart, Freddy’s and Shopper’s Market. • Each year H-Mart retains 80% of its customers, while losing 15% to Freddy’s and 5% to Shopper’s Market. • Freddy’s retains 65% of its customers, loses 20% to H-Mart and 15% to Shopper’s Market. • Shopper’s Market keeps 70% of its customers, loses 20% to H-Mart and 10% to Freddy’s.
Look at the calculation used to determine the probability of starting at H-Mart and shopping there two year later: We can obtain the same result by multiplying row one by column one in the transition matrix:
This matrix tells us the probabilities of going from one store to another after 2 years: • Compute the probability of shopping at each store 2 years after shopping at Shopper’s Market:
If the initial distribution was evenly distributed between H-Mart, Freddy’s, and Shpper’s market, compute the distribution after two years:
To utilize a Markov chain to compute probabilities, we need to know the initial probability vector q(0) If there are n states, let the initial probability vector be where • qiis the probability of being in state i initially • All entries 0 qi 1 • Column sum = 1
What happens after 10 years? Example:
Let q(k) be the probability distribution after k steps. • We are iterating q(k+1) = T q(k) • Eventually, for a large enough k, q(k+1) = q(k) = s • Resulting in s = T s • s is called a steady state vector • s =q(k) is an eigenvector for eigenvalue 1
In the grocery example, there was a unique steady state vector s, and T q(k) s. This does not need to be the case:
How can we guarantee convergence to an unique steady state vector regardless of initial conditions? • One way is by having a regular transition matrix • A nonnegative matrix is regular if some power of the matrix has only nonzero entries.
Digraphs • A directed graph (digraph) is a set of vertices (nodes) and a set of directed edges (arcs) between vertices • The arcs indicate relationships between nodes • Digraphs can be used as models, e.g. • cities and airline routes between them • web pages and links
How does Google work? • Robot web crawlers find web pages • Pages are indexed & cataloged • Pages are assigned PageRank values • PageRank is a program that prioritizes pages • Developed by Larry Page & Sergey Brin in 1998 • When pages are identified in response to a query, they are ranked by PageRank value
Why is PageRank important? • Only a few years ago users waited much longer for search engines to return results to their queries. • When a search engine finally responded, the returned list had many links to information that was irrelevant, and useless links invariably appeared at or near the top of the list, while useful links were deeply buried. • The Web's information is not structured like information in the organized databases and document collections - it is self organized. • The enormous size of the Web, currently containing ~10^9 pages, completely overwhelmed traditional information retrieval (IR) techniques.
By 1997 it was clear that IR technology of the past wasn't well suited for Web search • Researchers set out to devise new approaches. • Two big ideas emerged, each capitalizing on the link structure of the Web to differentiate between relevant information and fluff. • One approach, HITS (Hypertext Induced Topic Search), was introduced by Jon Kleinberg • The other, which changed everything, is Google's PageRank that was developed by Sergey Brin and Larry Page
How are PageRank values assigned? • Number of links to and from a page give information about the importance of a page. • More inlinks the more important the page • Inlinks from “good” pages carry more weight than inlinks from “weaker” pages. • If a page points to several pages, its weight is distributed proportionally.
1 2 3 6 5 4 • Imagine the World Wide Web as a directed graph (digraph) • Each page is a vertex • Each link is an arc • A sample 6 page web (6 vertex digraph)
PageRank defines the rank of page i recursively by rj is the rank of page j Ii is the set of pages that point into page i Oj is the set of pages that have outlinks from page j
1 2 3 6 5 4 • For example, the rank of page 2 in our sample web:
Since this is a recursive definition, PageRank assigns an initial ranking equally to all pages: • then iterates
Process can be written using matrix notation. • Let q(k) be the PageRank vector at the kth iteration • Let T be the transition matrix for the web • Then q(k+1)= T q(k) • T is the matrix such that tij is the probability of moving from page j to page i in one time step • Based on the assumption that all outlinks are equally likely to be selected.
1 2 3 6 5 4 Using our 6-node sample web: • Transition matrix:
To eliminate dangling nodes and obtain a stochastic matrix, replace a column of zeros with a column of 1/n’s, where n is the number of web pages.
Web’s nature is such that T would not be regular Brin & Page force the transition matrix to be regular by making sure every entry satisfies 0 < tij < 1 Create perturbation matrix E having all entries equal to 1/n Form “Google Matrix”:
By calculating powers of the transition matrix, we can determine the stationary vector:
Query requests term 1 or term 2 Inverted file storage is accessed Term 1 doc 3, doc 2, doc 6 Term 2 doc 1, doc 3 Relevancy set is {1, 2, 3, 6} s1=.2066, s2=.1770, s3=.1773, s6=.1309 Doc 1 deemed most important How does Google use this stationary vector?
Adding a perturbation matrix seems reasonable, based on the “random jump” idea- user types in a URL This is only the basic idea behind Google, which has many refinements we have ignored PageRank as originally conceived and described here ignores the “Back” button PageRank currently undergoing development Details of PageRank’s operations and value of are a trade secret.
Updates to Google matrix done periodically Google matrix is HUGE Sophisticated numerical methods are be used