Download
1 / 20
200 likes | 212 Views
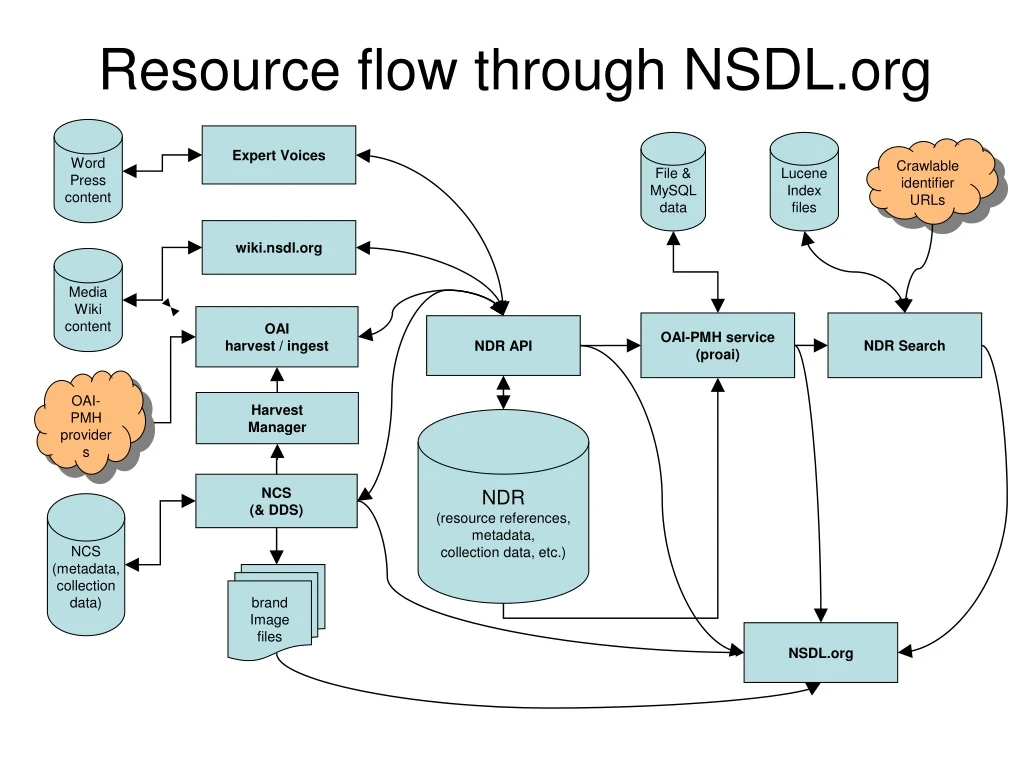
Resource flow through NSDL.org. Word Press content. Expert Voices. File & MySQL data. Lucene Index files. Crawlable identifier URLs. wiki.nsdl.org. Media Wiki content. OAI harvest / ingest. OAI-PMH service (proai). NDR Search. NDR API. OAI-PMH providers. Harvest Manager.

E N D
Resource flow through NSDL.org Word Press content Expert Voices File & MySQL data Lucene Index files Crawlable identifier URLs wiki.nsdl.org Media Wiki content OAI harvest / ingest OAI-PMH service (proai) NDR Search NDR API OAI-PMH providers Harvest Manager NDR (resource references, metadata, collection data, etc.) NCS (& DDS) NCS (metadata, collection data) brand Image files NSDL.org
NSDL.org resources • A resource in the NDR is (typically) a web page or URL reference. • NSDL.org contains some resource pages and hosts a UI for searching and browsing collected resource references in the library. • Resource references in the NDR: • Must have descriptive information (metadata). • All resources in the library must belong to a collection. • Collections are also represented in the library by resource references.
Community Portals(NSDL blog spaces, NSDL wiki spaces) Word Press content Expert Voices • Directly enter resource references and metadata in the NDR using the “plug in” extensions. • Authorized portal application administrators maintain the resource metadata in the NDR. • Administration of the portal space is local to the portal application. • Portals require initial authentication and set-up through collection administration (NCS) and direct NDR maintenance. wiki.nsdl.org Media Wiki content NDR API NDR (resource references, metadata, collection data, etc.)
NCS The NCS contains all NSDL administrative collection information and some individual collection’s resource metadata. • The NCS administers collections and metadata indirectly in a local data store. • Local NCS data is synchronized with the NDR as necessary. • The NCS’s Digital Discovery Service (DDS) is used by nsdl.org and the harvest manager. NDR API NDR (resource references, metadata, collection data, etc.) NCS (& DDS) NCS (metadata, collection data) brand Image files NSDL.org
OAI harvest / ingest The majority of library resources enter the NDR via OAI metadata sources. • The Harvest Manager (HM) reads NCS data to trigger scheduled harvests. • OAI Metadata providers are, by default, collections and have administrative collection information managed by the NCS. • Metadata records must be parsed to determine the resources represented. • The quality of harvested metadata varies widely. • The reliability of OAI-PMH services is similar to other web services: not always “up”, subject to server moves, budget cuts, and project life spans. OAI harvest / ingest NDR API OAI-PMH providers Harvest Manager NDR (resource references, metadata, collection data, etc.) NCS (& DDS)
OAI-PMH service • The NSDL.org OAI service is a customized version of the OAI provider (proai) from the fedora project. File & MySQL data • Proai queries the NDR for updates on a once per day schedule. • Calls to the fedora instance use the MPT store to determine what should be updated • Complete metadata records are constructed by NDR API calls • OAI records are indexed and cached by proai • Processes new updates as a batch. OAI-PMH service (proai) NDR API NDR (resource references, metadata, collection data, etc.)
Search Lucene Index files Crawlable identifier URLs • Search harvests proai for updates once per day. • Metadata records are added or updated within the indexes. • Resources represented by the metadata are crawled separately and any available content is represented within the indexes. • Lucene index files are switched into production search after updating is complete. • The Lucene index is based on all metadata and crawled content. OAI-PMH service (proai) NDR Search
NSDL.org The NSDL.org web pages directly use: • NCS (DDS) • NDR API • nsdl OAI • NDR Search • nsdl.org brand image files OAI-PMH service (proai) NDR Search NDR API NCS (& DDS) brand Image files NSDL.org
Other services(not in the previous diagrams) • Sitemaps • Strand Map Service (SMS) • Publisher metadata processing • RSS ingest • On-Ramp
Sitemaps • Used by search engines to index all library resources • Provides “resource” page links (http://nsdl.org/resource/...) for all resource references. Sitemaps sitemapindex.xml NDR (resource references, metadata, collection data, etc.) Sitemap files NSDL.org
SMS contains a repository of AAAS Benchmarks, strands, grades bands, maps and chapters, stored in a MySQL database A visualization engine dynamically generates the map images from the repository JavaScript and REST APIs provide access to the benchmarks repository, visualizations and customizable interactive AJAX interfaces NSDL Science literacy Maps use the SMS APIs to create an interactive map interface NDR Search is used to bring related NSDL resources into the Science Literacy Maps Strand Map Service NSDL ScienceLiteracy Maps SMS JavaScriptand CSIP APIs NDR Search SMS - AAAS BenchmarksRepository and Map Visualization Engine (benchmarks, strands, grades, maps, chapters)
Publisher metadata preparation • Publisher data is either part of regular OAI harvesting, or is provided as files • File submissions for “one off” collections must be manually pre-processed and added to the CWIS instance at Columbia • Larger, continuous feeds of publisher data sets are pre-processed by scripts at Columbia and made available from the EPIC OAI server • The availability of Columbia CWIS and EPIC servers is not guaranteed • Final insertion of publisher metadata is via OAI harvest. Publisher metadata Metadata File conversion Local OAI content CWIS (on “grackle”) @ Columbia OAI-PMH providers
RSS ingest (proposed) Processing syndicated feed (RSS, etc.) sources requires: UI • The ability to browse, create, and edit the NDR data model objects and relationships • Acceptance & management of brand images • … RSS harvest / ingest NDR API Feed providers NDR (resource references, metadata, collection data, etc.) NCS (& DDS) brand Image files
Setup of RSS Feed for RSS Ingest according to the process required by RSS Ingest Setup of Destination for each registered RSS Feed to produce the RSS Feed Setting of controlled vocabulary metadata in records to be distributed that correspond to NSDL DC Distribution of records to the Destination NOTE: Requirements for registering results produced by destinations are also being explored. OnRamp (proposed) Allow users to register records in NDR requires… OnRamp Record Including NSDL DC controlled vocabulary Distribution Mapping of record fields to RSS Ingest fields Destination Produces RSS Feed OnRampas Feed provider RSS harvest / ingest (See RSS Ingest for more information)
Top 5 collection management issues • No tool exists to manage all metadata directly in the NDR • Resource link vitality and collection aging problems • Brand image management • Continued library growth and maintenance • Limited representation of metadata frameworks Criteria for identifying issues: • Collection quality concerns • Quality of user experience at NSDL.org • Streamlining collection operations
No tool exists to manage all metadata directly in the NDR • Most resources in the NDR are created by harvesting metadata. • Harvested metadata can not be edited. • Inappropriate or broken resources and metadata can only be excluded either manually by fedora tools, or by deaccessioning entire collections. • Challenges: • NCS can not currently manage all metadata items (millions) • Harvested metadata that is updated will be overwritten by subsequent harvests • An edited metadata record is no longer “owned” by the originator • De-funded and unsupported collections have no owner, but may be valuable and need maintenance
Link vitality and collection aging • As collections age, are defunded, or lose support, they lose resource links gradually or become out dated on a resource by resource basis. Broken links are still returned through NSDL.org search and browse functions. No tool exists to determine what links are broken. • Challenges: • Broken link checking appears as a crawl to site providers. Many sites block crawls. • Updated link vitality information needs to be fed into the system somewhere, and then made available to relevant services: Search, NSDL.org site, harvesting, etc.
Brand image management • Collection brand image files are entered and maintained by the NCS, but the Search and NSDL.org services get the information from the OAI metadata records that are served via the proai service. This requires that all collection metadata be updated for a brand image change. The changes must then propagate through proai and search indexing before the updated image references are available. • This process is long, unwieldy, and introduces delays. • Challenges: • Determine where to store brand images • Provide a collection-based service to reference and retrieve current brand images
Continued library growth and maintenance • The technical aspects of collection development and maintenance is not being provided for. New resources and new (non-Pathway) collection additions are requested, but no support is provided to add them to the library. Old collections age and become a liability to the library. • Challenges: • Educating, training, and supporting collection builders • New resources and collections must be added, cataloged, and accessioned • Old collections need to be monitored for subject relevance, and resource link vitality • Prevent NSDL.org from serving resource landing pages for rejected, declined, and deaccessioned resources
Limited representation of metadata frameworks • Standard metadata formats exist for many science and math disciplines, but the library can currently only harvest and ingest Dublin Core (oai_dc) and the NSDL’s qualified version of Dublin Core (nsdl_dc). This forces us to ignore much relevant metadata that is represented by the discipline-specific formats. The ability to build resource references and to search the information stored in metadata formats other than Dublin Core could enhance the utility of NSDL search. • Challenges: • All current metadata is served through proai as both oai_dc and nsdl_dc. Other metadata schemes would require conversion to these for this to continue. • The Search indexes are constructed to use the nsdl_dc fields to enhance retrieval. Search document architecture would need modification.