Download
1 / 132
1.33k likes | 1.42k Views
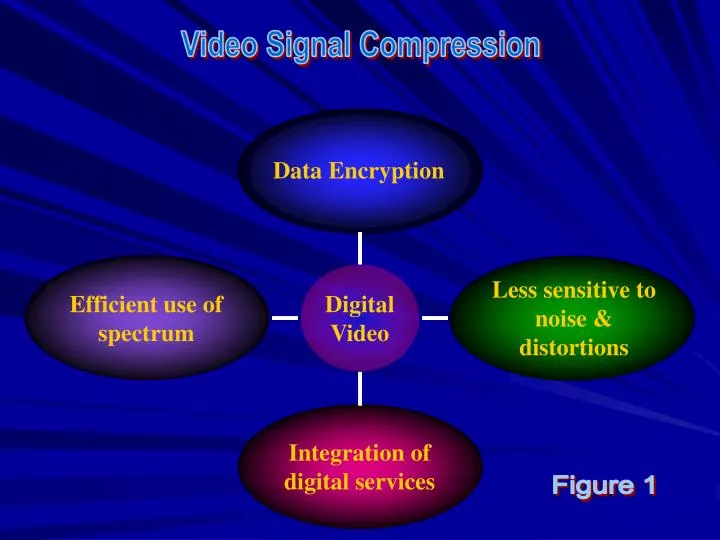
Video Signal Compression. Data Encryption. Less sensitive to noise & distortions. Efficient use of spectrum. Digital Video. Integration of digital services. Figure 1. 576 lines. Picture Size. R: 83Mbit/s. G: 83Mbit/s. B: 83Mbit/s. Total: 249Mbit/s. 5.5MHz = 720 pixels. Raw image.

E N D
Video Signal Compression Data Encryption Less sensitive to noise & distortions Efficient use of spectrum Digital Video Integration of digital services Figure 1
576 lines Picture Size R: 83Mbit/s G: 83Mbit/s B: 83Mbit/s Total: 249Mbit/s 5.5MHz = 720 pixels Raw image R,G andB 576 lines/frame 720 pixels/line 50 fields/second 8 bit per pixel Total: 576x720x25x3 x8 = 249Mbit/sec Figure 2a
A bit of saving in the PAL - YUV Representation Chroma at 4.43 MHz Y Sound at 6 MHz U,V VSB f -1.75 MHz Chrominance can be represented with a considerable narrower bandwidth (resolution) than luminance
576 lines Picture Size Y: 83Mbit/s U: V: Total: 5. 5MHz = 720 pixels PAL system LuminanceY 576 lines/frame 720 pixels/line 50 fields/second 8 bit per pixel Total: 576x720x25x8 = 83Mbit/sec Figure 2b
288 lines Picture Size Y: 83Mbit/s U: 21Mbit/s V: Total: 2.75MHz = 360 pixels PAL system Chrominance U 288 lines/frame 360 pixels/line 50 fields/second 8 bit per pixel Total: 288x360x25x8 = 21Mbit/sec Figure 2c
288 lines Picture Size Y: 83Mbit/s U: 21Mbit/s V: 21Mbit/s Total: 125Mbit/s 2.75MHz = 360 pixels PAL system Chrominance V 288 lines/frame 360 pixels/line 50 fields/second 8 bit per pixel Total: 288x360x25x8 = 21Mbit/sec Figure 2d
Typical Video Bandwidth Medium Quality : 1.2 Mbit/s Superior Quality : 6 Mbit/s Actual size - 249Mbit/s U,V downsampled - 125Mbit/s Result: Compression is necessary
Video Compression - Removal of Redundancy Redundancy in image contents Adjacent pixels are similar Intensity variations can be predicted Sequential frames are similar Lossy compression: Removal of redundant information, resulting in distortion that is insensitive to Human Perception
Adjacent pixels are similar (correlated) Pixels within this region have similar but not totally identical intensity. Lenna Figure 3a
Adjacent pixels are similar (correlated) Figure 3b
Adjacent pixels are similar (correlated) Intensity position Figure 3b
Adjacent pixels are similar (correlated) Autocorrelation function 1.0 0.8 0.6 0.4 0.2 -5 -4 -3 -2 -1 0 1 2 3 4 5 Figure 4
Adjacent pixels are similar (correlated) Interpolation • Pixel intensities usually varies in a smooth manner except at edge (dominant/salient) points • Record pixels at dominant points only. • Reconstruct the pixels between dominant points with “Interpolation”. • A straightforward method: Joining dominant points with straight lines. • High compression ratio for smooth varying intensity profile. • Difficulty: How to identify dominant points?
Adjacent pixels are similar (correlated) Transmit only selected pixels predicted the rest Intensity position Figure 5a
Quantizer (Q) Predictor (P) Input signal Predicted signal Error signal Quantized error signal Reconstructed signal Predictive Coding Prediction of current sample based on previous ones Quantizer: representation of a continuous dynamic range with a finite number of discrete levels (will be discussed later) Error = Quantization error
8 bits 3 bits Prediction error Predictive Coding Function of Predictive Coding: Data Compression Quantizer (Q) Predictor (P) Thebetter the predictor, the higher is the compression ratio
Predictive Coding A simple example: Quantizer (Q) 6 bits Predictor (P) 2 bits Quantizer
Reconstructed signal Reconstruction error Quantization error Predictive Coding Predictive Decoder Q-1 Quantizer (Q) Q-1 Predictor (P) Predictor (P) Option: the quantized levels are transmitted instead of the actual errors
Predictive Codec Predictive Decoder 6 bits Q-1 Quantizer (Q) Q-1 Predictor (P) Predictor (P) 2 bits Quantizer Error = Quantization error
Delta Modulation Predictive Decoder 6 bits Q-1 Quantizer (Q) Q-1 Predictor (P) Predictor (P) 1 bits Quantizer S = Fix step size
Linear Predictor Prediction based on the linear combination of previously reconstructed samples Current sample = Where Optimal predictor design by minimizing the Mean Square Prediction Error
Linear Predictor Optimal predictor design by minimizing the Mean Square Prediction Error
Intensity variation can be approximated by known functions Intensity A Y position Figure 5b
Intensity variation can be approximated by known functions e.g. Asin(n/T)+Y Intensity A Y position n Figure 5d
Intensity variation can be approximated by known functions Major Steps 1. Select a basis - a set of fixed functions {f0(n), f1(n), f2(n), f3(n), ……………, fN(n)} 2. Assuming all types of signals can be approximated by a linear combination of these functions (i.e. A(n) = a0f0(n)+ a1f1(n)+ a2f2(n)+…+ aNfN(n) 3. Calculate the coefficients a0, a1, ….., aN 4. Represents the input signal with the coefficients instead of the actual data 5. Compression: Use less coefficients, e.g. a0, a1, ….., aK (K<N) 6. For example: the set of sine and cosine waves
Intensity variation can be approximated by sinusoidal functions Sinusoidal Waves 1. Adopt the sine and cosine waves as a basis 2. Calculate the Fourier coefficients (Note: a sequence of N points will give N complex coefficients 3. Encoding (compression): Represents the signal with the first K coefficients, where K < N 4. Decoding (decompression): Reconstruct the signal with the K coefficients with inverse Fourier Transform. 5. Other Transforms (e.g. Walsh Transform) can be adopted
Transform Coding Set of basis functions
Transform Coding Transform from the “s” domain to the “S” domain denotes Dot Product between A and B
Transform Coding x(0) x(1) x(2) …….. x(N-2) x(N-1) W(0,k) W(2,k) W(1,k) W(N-2,k) W(N-1,k) X(k)
Transform Coding A. Orthogonal Property Delta function B. Orthonormal Property
Transform Coding Inverse Transform from the “S” domain to the “s” domain s are complex conjugates denotes Dot Product between A and B
Transform Coding X(0) X(1) X(2) …….. X(N-2) X(N-1) W*(n,0) W*(n,2) W*(n,1) W*(n,N-2) W*(n,N-1) x(n)
Discrete Fourier Transform Note: X(k) is complex
Discrete Cosine Transform (DCT) Note: X(k) is real
Inverse Discrete Cosine Transform (IDCT) N-1 C(k) x(n) = X(k)W’(n,k) 2 k=0 W’(n,k) =cos[(2n+1)kp/2N] C(k) = 2-0.5 for k = 0 = 1 otherwise Note: Wk is real, therefore W’k = Wk
Transform for Compression Transform that are suitable for compression should exhibit the following properties: a. There exist an inverse transform b. Decorrelation c. Good Energy Compactness Optimal Transform : Karhunen-Loeve Transform(KLT)
Correlation - Similarity between adjacent samples x(0), x(1), x(2), x(3), x(4), x(5), x(6), x(7), ….., x(N-2), x(N-1) A sample can be predicted from its neighbor(s)
Transform with good decorrelation property After DFT, a coefficient is less predictable from its neighbor(s) X(0) X(1) X(2) X(3) X(4) X(5) X(6) X(7) Magnitude of frequency components
Energy Compactness - Importance of each sample x(0), x(1), x(2), x(3), x(4), x(5), x(6), x(7), ….., x(N-2), x(N-1) All samples are important
Energy Compactness - Importance of each sample x(0), x(1), x(2), x(3), x(4), x(5), x(6), x(7), ….., x(N-2), x(N-1) Any missing sample causes large distortion All samples are important
Energy Compactness - Importance of each sample DFT samples X(0) X(1) X(2) X(3) X(4) X(5) X(6) X(7) x(0) x(1) x(2) x(3) x(4) x(5) x(6) x(7)
Energy Compactness - Importance of each sample X(0) X(1) X(2) X(3) X(4) X(5) X(6) X(7) x(0) x(1) x(2) x(3) x(4) x(5) x(6) x(7)
Energy Compactness The signal can be constructed with the first 3 samples with good approximation X(0) X(1) X(2) X(3) X(4) X(5) X(6) X(7) x(0) x(1) x(2) x(3) x(4) x(5) x(6) x(7)
Good Energy Compactness All information is concentrated in a small number of elements in the transformed domain DCT has very good Energy Compactness and Decorrelation Properties
2D Discrete Cosine Transform (DCT) N-1 M-1 C(j) C(k) X(j,k) = x(m,n)W(m,j) W(n,k) 2 2 n=0 m=0 W(n,k)= cos[(2n+1)kp/2N] W(m,j)= cos[(2m+1)jp/2N] C(k) , C(j) = 2-0.5 for k = 0 and j = 0, respectively = 1 otherwise
x(0,0) x(0,1) x(0,2) x(0,N-1) x(1,0) x(1,1) x(1,2) x(1,N-1) x(M-1,0) x(M-1,1) x(M-2,2) x(M-1,N-1) 2-D DCT X(0,0) X(0,1) X(0,2) X(0,N-1) X(1,0) X(1,1) X(1,2) X(1,N-1) X(M-1,0) X(M-1,1) X(M-2,2) X(M-1,N-1)
M-1 N-1 C(j) C(k) 2 2 j=0 k=0 2D Discrete Inverse Cosine Transform (IDCT) x(m,n) = X(j,k)W(m,j) W(n,k) W(n,k)= cos[(2n+1)kp/2N] W(m,j)= cos[(2m+1)jp/2N] C(k) , C(j) = 2-0.5 for k = 0 and j = 0, respectively = 1 otherwise
x(0,0) x(0,1) x(0,2) x(0,N-1) x(1,0) x(1,1) x(1,2) x(1,N-1) x(M-1,0) x(M-1,1) x(M-2,2) x(M-1,N-1) X(0,0) X(0,1) X(0,2) X(0,N-1) X(1,0) X(1,1) X(1,2) X(1,N-1) X(M-1,0) X(M-1,1) X(M-2,2) X(M-1,N-1) 2-D IDCT