Download

1 / 23
230 likes | 374 Views
Hierarchically Tiled Arrays. Taylor Finnell Alex Schwartz. Overview. Background and g oals of HTA approach Tiling and Locality Structure of HTAs Creating an HTA Accessing an HTA’s components Operations Communication Operations Global Computations Implementations of HTA (Libraries)

E N D
Hierarchically Tiled Arrays Taylor Finnell Alex Schwartz
Overview • Background and goals of HTA approach • Tiling and Locality • Structure of HTAs • Creating an HTA • Accessing an HTA’s components • Operations • Communication Operations • Global Computations • Implementations of HTA (Libraries) • MATLAB • C++ • Conclusions
Background and Goals • Developed in 2006 by researchers from University of Illinois, IBM, and University of Coruña(Spain) • HTA is the first attempt to make tiles part of a language • Main goals of HTA: • Extend a sequential language to support parallel computation • Facilitate • Control of locality • Communication in parallel programs
Locality • Definition • The phenomenon of the same value or related storage locations being frequently accessed • Types • Temporal Locality • Reuse of specific data within relatively small time durations • Spatial Locality • Use of data elements within relatively close storage locations • Sequential Locality • Special case of Spatial Locality • Data elements are arranged and accessed linearly
Tiling • The structured division of memory to facilitate parallel computation • Used to organize computations so that communication costs in parallel programs are reduced • Important in scientific computing • Many iterative and recursive algorithms can be expressed naturally with tiles • Planned by programmer during program design • Some compilers have automatic tiling • Not always effective in tiling of complex algorithms
Structure of HTA • Type of tiled array object • Tiles can be composed of additional nested tiles • Uses array operations to manipulate tiles directly • Parallel computations and interprocessor communications are represented by assignments between HTAs
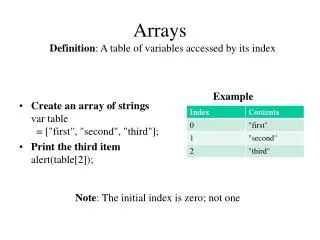
Creating an HTA • From an existing array (pictured) • Empty HTA of thesame size can becreated usinghta(3,3) • Empty HTAs must beassigned content tobe considered com-plete
Accessing an HTA • Accessing Tiles • C{2,1} refers to lowerleft tile • Accessing Elements Directly • C(5,4) refers to specific element, disregarding the tile structure • Note parenthesis vs. brackets • Accessing Elements Relatively • C{2,1}{1,2}(1,2) and C{2,1}(1,4) refer to the same element as C(5,4)
Accessing an HTA (cont.) • Regional Access (Flattening) • Disregards tiling, returns a standard array • C(1:2, 3:6) in example returns 2x4 matrix • Logical Indexing/Selection • Matrix of boolean valueswith same dimensions asthe HTA
Operations on HTAs • Two types of operations • Communication Operations • Global Computations
Communication Operations • Represented as assignments on distributed HTAs • Array Operations • HTA's provide overloaded array operations (circular shift, transpose, arithmetic operators, etc.) so that you can perform these operations at the tile level • Ex. Circular Shift will shift whole tiles instead of individual array elements
Communication Operations (cont.) • Example: Cannon’s algorithm • Distributed algorithm for matrix multiplication • Uses circular shift to distribute the work • Normal implementation • shifts rows and columns • Performs the multiplication element by element • HTA implementation • Shifts tiles • Performs the multiplication as matrix multiplication of tiles • Each processor owns a tile • Advantages • Aggregates data into a tile for communication • Increased locality due to single matrix multiplication • Locality further increased if more levels of tiling are used
Cannon’s Algorithm • Can use an alternative matrixmultiplication function toincrease locality
Global Computations • Passing an HTA to a function/operation • Operates in parallel on a set of tiles from an HTA distributed across a parallel machine • parHTA(@func, H) • @func is a function pointer • Reduction • An operation applied to all the components of a vector to produce a scalar • Applied to all the components of a n-dimensional array to produce a n-1 dimensional array • Matrices have row reduction and column reduction • Ex. Matrix Vector multiplication
Global Computations (cont.) • Ex. Matrix Vector multiplication • Matrix-vector multiplication takes place locally at each processor (the A*B part)
Implementations of HTA • MATLAB • Advantages • Disadvantages • C++ • Allocation approach • Advantages over MATLAB • Comparison to existing paradigm (MPI)
MATLAB implementation • Advantages • MATLAB's syntax for array access is convenient for representing HTA access (“Triplet Notation”) • Disadvantages • Not as efficient as C++'s implementation • Interpreted MATLAB limits efficiency due to immense overhead • Lots of temporary variables created to hold partial expression results • Parameters passed by value • Assignment statements also replicate data
C++ Implementation • Allocation/construction of HTAs • HTAs represented as composite objects with methods to operate on HTAs • HTAs allocated on heap, return a handle/reference • All HTA access occurs through this handle • Uses reference counting for garbage collection • Advantages over MATLAB • Higher performance than MATLAB implementation • Memory layout is controllable by the user unlike MATLAB
HTA vs. MPI (Message Passing Interface) • HTA is integrated into languages using operator overloading and polymorphism • Improved readability • HTA requires much less code • Communication takes place through assignment rather than • send and receive instructions • packing and unpacking data • checking boundary conditions • HTAs are partitioned and distributed through a single constructor • MPI has to compute • limits of data owned by each processor • Neighbors of a processor • Acitve set of processors, etc. • Communication is made more obvious
Conclusions • Ideal for algorithms that can be naturally expressed in terms of blocks • Communication is less involved versus other parallel programming approaches • Slow and elegant in MATLAB, but fast and verbose in C++ • Due to lack of operator overloading in the C++ library • Good for architectures consisting of multiple independent processing cores • One example given by the authors is the CELL processor
References Bikshandi, G. (2006, October 12). Hierarchically Tiled Arrays: A Programming paradigm for parallelism and locality. Urbana, IL, USA.:www.cs.uiuc.edu/class/fa06/cs498dp/notes/hta.pdf Bikshandi, Guo, & Hoeflinger. (2006, March 29). Programming for Parallelism and Locality with Hierarchically Tiled Arrays. New York, NY, USA.:https://wiki.engr.illinois.edu/download/attachments/195766122/p48-bikshandi.pdf Various. (2010, January 15). Programming for Parallelism and Locality with Hierarchically Tiled Arrays. Retrieved July 12, 2012, from CSU Computer Science Department Wiki: https://www.cs.colostate.edu/wiki/Programming_for_Parallelism_and_Locality_with_Hierarchically_Tiled_Arrays. Various. (2012, May 16). Locality of Reference. Retrieved July 12, 2012, from Wikipedia: http://en.wikipedia.org/wiki/Locality_of_reference
Hierarchically Tiled Arrays Taylor Finnell Alex Schwartz