Download
1 / 53
530 likes | 638 Views
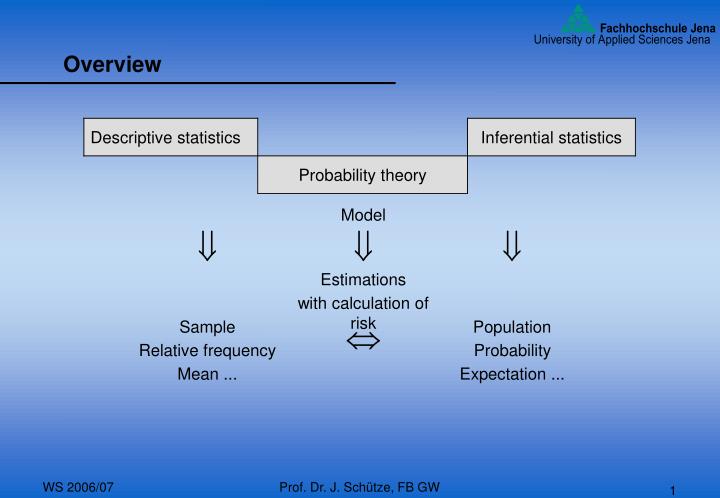
Model. . . . Estimations. with calculation of risk. Sample. . Population. Relative frequency. Probability. Mean. Expectation. Overview. Contents of the lecture. A Descriptive statistics basic terms, parameters for univariate and multivariate samples

E N D
Model Estimations with calculation of risk Sample Population Relative frequency Probability Mean ... Expectation ... Overview Prof. Dr. J. Schütze, FB GW
Contents of the lecture A Descriptive statistics basic terms, parameters for univariate and multivariate samples B Probability theory calculating with probabilities, random variables, distributions, limit theorems C Inferential statistics estimation of parameters, confidence intervals, hypothesis testing, non parametric tests LiteratureJ.D. Jobson, Applied Multivariate Data Analysis, Springer Texts in StatisticsHinkelmann, Kempthorne, Design and Analysis of Experiments, Wiley Series Prof. Dr. J. Schütze, FB GW
Examples Technics When measuring a certain quantity, various uncontrollable parameters can affect the result. Repeated measurement may lead to different results. We consider the data to be outcomes of a random variable. From the different results, we estimate the unknown quantity. How exact or reliable is this estimation? Biology/Medicine A newly developed drug to reduce cholesterol has to be compared to a standard drug concerning its effectivity. For reasons of time and costs, it is not possible to test the drug in the whole population of people suffering from elevated cholesterol level. How certain are the conclusions drawn from the measurements only in a the sample of the whole population? Which differences of effectivity are random, when do we see a significant difference in the effectivity? Prof. Dr. J. Schütze, FB GW
Statistical methods • Statistical methods • samples also allow reliable conclusions • however, only with certain confidence • sample survey has to be random Prof. Dr. J. Schütze, FB GW
Basic terms Sample space all in principle possible observation unit (intended population) Sample from the sample spacerandomly chosen subset of observation units Survey unit/statistical unit (proband) each observation unit contained in the sample Prof. Dr. J. Schütze, FB GW
Basic terms Characteristic/statistical variable intended aim (observed values) of survey Values of characteristic measured or observed values of a statistical unit/proband Possible values range of the statistical variable The characteristics are different concerning the content of information. We distinguish several different levels of scale. Prof. Dr. J. Schütze, FB GW
Level of scale of a variable Question: Which chocolate do you buy? Ritter Sport Milka Sarotti else The possible answers are categories, which can only have the relations "equal" or "different". For data input, they are usually coded with numbers, nevertheless, there is no way for reasonable calculating. No averages, no spread, only reports on frequency!!!! Such variables have categorical/nominal level. Prof. Dr. J. Schütze, FB GW
Level of scale of a variable • Question: • How much do you like chocolate? • not at all • less • neutral • a little • very much The possible answers 1,...,5 are an ordinal scale. They have the relations ‚>‘ or ‚<‘. The distances between the values can be regarded as different, dependent on the observer. Such variables have an ordinal level. Prof. Dr. J. Schütze, FB GW
Level of scale of a variable Question: How much money do you spend on chocolate per week? _ _,_ _ € The answer marks a number on the natural scale. We can distinguish the relations ‚>‘ or ‚<‘. Additionally, we can compute reasonable differences, sums and averages. Such variables have a cardinal or metric scale. For the metric scale, we distinguish between discrete and continuous scales. A discrete scale is realized if the answer originates from counting. Continuous variables can assume each value in an interval. Prof. Dr. J. Schütze, FB GW
Level of scale of data Nominal scale data expresses qualitative attributes (categories) order on a scale is impossible (only equal or different) differences in different values cannot be measured Ordinal scaledata can be sorted, but differences in values are not quantifiable Cardinal scale (metric) data is measured on a discrete or continuous scale difference between values characterizes a correspondingly high difference in characteristics The information content raises with this sequence. Prof. Dr. J. Schütze, FB GW
Properties Univariate discrete characteristics Discrete characteristic X is measured n times, sample if there are only k< n possible different values , you can count how often this values occur. Absolute frequency number of occurrences of among the values of the sample Relative frequency Prof. Dr. J. Schütze, FB GW
determination of frequency value cumulative frequency 1 2 0.10 0.10 (10%) 2 5 0.25 0.35 (35%) 3 7 0.35 0.70 (70%) 4 4 0.20 0.90 (90%) 5 2 0.10 1.00 (100%) Univariate discrete characteristics Example 1 grades of 20 students: 2, 1, 2, 3, 3, 3, 1, 4, 2, 4, 3, 3, 2, 3, 5, 4, 5, 4, 3, 2 sample size is n = 20 different possible values: 1, 2, 3, 4, 5 that means k = 5 Prof. Dr. J. Schütze, FB GW
Univariate discrete characteristics Graphical display e.g. with bar charts absolute/relative frequency or absolute/relative cumulative frequencies Prof. Dr. J. Schütze, FB GW
We divide the interval between smallest and largest observation in equally wide, mutually exclusive classes , number of classes Absolute frequency of class number of in Relative frequency Univariate continuous characteristics Continuous characteristic X is measured n times, sample thereby, all occurring values are different in general and a simply bar chart gives no information about the distribution of X Absolute / relative cumulative frequency H(x) / F(x) is computed as sum of frequencies upon all classes left of x, including x Prof. Dr. J. Schütze, FB GW
,5 1,2 relative relative sum frequency 1,0 frequency ,4 ,8 ,3 ,6 ,2 ,4 ,1 ,2 0,0 0,0 100 140 180 220 260 300 340 380 100 140 180 220 260 300 340 380 cholesterol (class midpoints) cholesterol value (class midpoints) Univariate continuous characteristics Example 2 cholesterol values of 1067 probands (raw data are classified) Function of cumulative frequency Histogram Prof. Dr. J. Schütze, FB GW
Empirical quantiles Problem Below which boundary do we find half of (a tenth of,...) the sample? We sort the sample in ascending order. By size n,one value matches to a fraction 1/n, k values to a fraction k/n. From k/n = α we find that the part for fraction α is reached for the first time when the value with index α·n (if it is an integer) is reached. Example 3 height of 10 newborn babies: 51, 50, 51, 49, 49, 51, 50, 57, 48, 52 in ascending order: 48, 49, 49, 50, 50, 51, 51, 51, 52, 57 E.g. the 10%-quantile is a border which parts the sample thus there is exactly one value (10%) below and nine values (90%) above the border. Therefore each value between 48 and 49 is possible, the border is not unique. To avoid this problem, we take the value in the middle, 48.5. Concerning the 15%-quantile, the demand for the percentage can only be fulfilled approximately, because a 5%-grid is too narrow for only ten values. Prof. Dr. J. Schütze, FB GW
Empirical quantiles Calculation of empirical quantiles sample sorted in ascending order Empirical α –Quantil for is the number The α –quantile divides the range of the sample into two parts thus below the quantile there are α·100%, and above there are (1-α)·100% of the sample values. Prof. Dr. J. Schütze, FB GW
51 51 51 49 49 50 50 52 48 57 10%-quantile: 15%-quartile: Empirical quantiles Example 3 continued height of 10 newborn babies: 51, 50, 51, 49, 49, 51, 50, 57, 48, 52 in ascending order: 48, 49, 49, 50, 50, 51, 51, 51, 52, 57 Prof. Dr. J. Schütze, FB GW
51 51 51 49 49 50 50 52 48 57 lower quartile: median: upper quartile: interquartile range Empirical quantiles Example 3 continued height of 10 newborn babies: 51, 50, 51, 49, 49, 51, 50, 57, 48, 52 in ascending order: 48, 49, 49, 50, 50, 51, 51, 51, 52, 57 Prof. Dr. J. Schütze, FB GW
51 51 51 49 49 50 50 52 48 57 Boxplots lower quartile median upper quartile width of box = interquartile range = 2 Prof. Dr. J. Schütze, FB GW
Detection of outliers lower quartile median upper quartile The normal range is from the lower quartile – 1.5*box width to the upper quartile + 1.5*box width. width of box = 2, therefore we find: normal range (49 – 1.5*2, 51 + 1.5*2) = (46, 54) values outside of the normal range are outliers, like the value 57 the fences denote the area which is covered by the "normal values" of the sample Prof. Dr. J. Schütze, FB GW
51 51 51 49 49 50 50 52 53 48 lower quartile median upper quartile Detection of outliers altered data set height of 10 newborn babies: 51, 50, 51, 49, 49, 51, 50, 53, 48, 52 box width = 2, normal range (49 – 3, 51 + 3) = (46, 54), there is no outlier Prof. Dr. J. Schütze, FB GW
51 51 51 49 49 50 50 52 55 48 lower quartile median upper quartile Detection of outliers newly altered data set height of 10 newborn babies: 51, 50, 51, 49, 49, 51, 50, 55, 48, 52 box width = 2, normal range (49 – 3, 51 + 3) = (46, 54), the value 55 is an outlier Prof. Dr. J. Schütze, FB GW
measures of location measures of deviation 1 n å = - 2 2 s ( x x ) arithmetic empirical variance i - n 1 = i 1 mean 1 æ ö n å = - 2 2 ( x n x ç ÷ i - è ø n 1 = i 1 k k 1 1 å å = = - * * 2 * 2 * x x h ( x ) s ( x x ) h ( x ) with absol. frequencies i i i i i i - n n 1 = = i 1 i 1 n k k å = * * å = - x x f ( x ) 2 * 2 * s ( x x ) f ( x ) i i i i i i - with relat. frequencies n 1 = i 1 = i 1 = + 2 s s standard deviation s = v coeff. of variation x s = s standard error x n ~ ~ = x x n 1 ~ å = - d x x 0 , 5 i median medium absolute n = i 1 ~ deviation ~ ~ = - d x x 0 . 5 0 . 75 0 . 25 inter quartile range Statistical measures Prof. Dr. J. Schütze, FB GW
Age 20 23 24 59 55 26 32 29 43 38 31 36 Speeding 22 22 40 23 34 22 22 21 28 27 25 29 Multivariate characteristics When measuring more than one characteristic at the same object, we often want to know if those characteristics are dependent. Example 4 During atraffic check, all those driver who had to pay a speeding fine were asked their age. Here we have two cardinal characteristics for 12 drivers. For analyzing the dependence, the points can be shown graphically. Such plots are called scatter plots. Prof. Dr. J. Schütze, FB GW
Age 20 23 24 59 55 26 32 29 43 38 31 36 Speeding 22 22 40 23 34 22 22 21 28 27 25 29 45 40 35 30 25 speeding 20 10 20 30 40 50 60 age Measures of dependence for cardinal characteristics Example of a scatter plot Prof. Dr. J. Schütze, FB GW
ascending tendency: decreasing tendency: If the points are distributed over all quadrants, there is no linear tendency. Products are the main items for the measure of dependence Covariance Correlation coefficient (Pearson) Measures of dependence for cardinal characteristics We divide the area of the plot into 4 quadrants by the mean values of the single dimensions. An argument for a linear dependence is that all points are situated in the first and third respectively in the second and forth quadrant. Prof. Dr. J. Schütze, FB GW
Measures of dependence for cardinal characteristics Equivalent notation of the Pearson-correlation Prof. Dr. J. Schütze, FB GW
Measures of dependence for cardinal characteristics Interpretation of the Pearson-correlation The correlation coefficient of Pearson measures, how close the linear dependence between X and Y is. we always find: For r = 1, all data points are situated on a ascending line. For r = -1, all data points are situated on a descending line. For r = 0, there is no linear tendency. Prof. Dr. J. Schütze, FB GW
Measures of dependence for cardinal characteristics Example 4 Calculation of the correlation coefficient of Pearson Prof. Dr. J. Schütze, FB GW
rank number of in ascending order of values of X rank number of in ascending order of values of Y Multiple appearing values receive the same middle rank. Measures of dependence for cardinal characteristics Correlation coefficient of Spearman for ordinal characteristics or cardinal characteristics with outliers The correlation coefficient of Spearman measures a monotonous dependence.For r = 1 all data points show a monotonous ascending tendency. For r = -1 all data points show a monotonous descending tendency. For r = 0 there is no monotonous tendency. Prof. Dr. J. Schütze, FB GW
Measures of dependence for cardinal characteristics Correlation coefficient of Spearman Example 4 Prof. Dr. J. Schütze, FB GW
Then, value 22 appears four times, on the ranks 2, 3, 4 and 5. Instead of those rank numbers each receives the same average rank, Measures of dependence for cardinal characteristics Correlation coefficient of Spearman Example 4 The smallest value of y is 21, it receives rank 1. afterwards the numeration is continued with 6. Prof. Dr. J. Schütze, FB GW
Measures of dependence for cardinal characteristics Correlation coefficient of Spearman Example 4 Prof. Dr. J. Schütze, FB GW
Set up: The unknown coefficients are determined after the following criteria of optimality (method of least squares) residuals are the vertical differences between the measured points and the line The sum of the squared residuals is mini- mized by choosing the correct parameters. Linear regression If the cardinal characteristics X, Y have a high correlation coefficient, they have a close linear dependence, which can be described by a linear equation. Prof. Dr. J. Schütze, FB GW
Optimal estimation for parameters is received by calculating the minimal value of system of normal equations Regression coefficient with the following solutions: Regression constant Linear regression Setting the partial derivatives of f by b0, b1to zero leads to a system of equations Prof. Dr. J. Schütze, FB GW
Linear regression Example 5 Prof. Dr. J. Schütze, FB GW
Regression coefficient Regression constant Linear regression In the example: Regression function: y = 3.25 – 0.5 x Prof. Dr. J. Schütze, FB GW
Linear regression Function of regression y = 3.25 – 0.5 x Thus the calculated function of regression fits the points optimal according to the used criteria. Because the criteria minimizes the sum of the squared deviations of the points and the line, it is called MLS-regression(Method of Least Squares). Prof. Dr. J. Schütze, FB GW
residuals: residual variance: MSE: Mean Square Error Linear regression Goodness of fit of the function of regression Residuals: vertical difference between the points and the regression line from those, we derive the residual variance square sum: For MSE, the division by n - 2 corresponds to the number of degrees of freedom which diminishes the sample size n by two because of the two estimated values b0 and b1. Prof. Dr. J. Schütze, FB GW
Residual variance Linear regression Evaluation of goodness of fit for y = 3.25 – 0.5 x The sum of the residuals is always zero, therefore we cannot use it for evaluating the goodness of the fit. We calculate the residual variance from the sum of the squares of the residuals. Prof. Dr. J. Schütze, FB GW
The explained variance is the squared deviation of the points on the regression function to the mean line Linear regression Prof. Dr. J. Schütze, FB GW
Linear regression total variance explained variance Prof. Dr. J. Schütze, FB GW
We get always: (decomposition of variance) Linear regression total variance explained variance residual variance Attention: The decomposition of variance is only valid for the square sums - without factors. Prof. Dr. J. Schütze, FB GW
Coefficient of determination: The coefficient of determination is the part of the explained variance in the total variance. It is equal to the square of the correlation coefficient rxy For the example we find with SSE = 0.25, SSY = 2.75 the coefficient of determination Linear regression From the decomposition of the variance SSY = SSŶ + SSE we find, dividing by SSY Prof. Dr. J. Schütze, FB GW
speeding age Linear regression The goodness of fit of the linear regression could be affected by the existence of outliers in the dataset. Consider again example 4. Function of regression Y = 0.087x + 23.218 Coefficient of determination0.035 The linear relationship is not very strong. Prof. Dr. J. Schütze, FB GW
speeding age Linear regression Removing this possible outlier will improve the coefficient of determination: function of regression Y = 0.197x + 17.971 coefficient of determination0.365 Prof. Dr. J. Schütze, FB GW
speeding age Linear regression Repeating the procedure with another ‘outlier’, we get function of regression Y = 0.375x + 12.717 coefficient of determination 0.831 Prof. Dr. J. Schütze, FB GW
Linear regression The noncritical elimination of outliers can be misleading. It can simulate strong relationships, which are only wishes. function of regression Y = 0.087x + 23.218 coefficient of determination0.035 function of regression Y = 0.197x + 17.971 coefficient of determination0.365 function of regression Y = 0.375x + 12.717 coefficient of determination 0.831 Prof. Dr. J. Schütze, FB GW
Linear regression with SPSS Data set reg.sav Analyze / Regression / Linear Prof. Dr. J. Schütze, FB GW