Download

1 / 18
180 likes | 304 Views
MICE Data Flow. Henry Nebrensky Brunel University. 1. The Awesome Power of Grid Computing. The Grid provides seamless interconnection between tens of thousands of computers. It therefore generates new acronyms and jargon at superhuman speed. 2. MICE and Grid Data Storage.

E N D
MICE Data Flow Henry Nebrensky Brunel University 1 Henry Nebrensky – MICE DAQ review - 4 June 2009
The Awesome Power of Grid Computing The Grid provides seamless interconnection between tens of thousands of computers. It therefore generates new acronyms and jargon at superhuman speed. 2 Henry Nebrensky – MICE DAQ review - 4 June 2009
MICE and Grid Data Storage • The Grid provides MICE not only with computing (number-crunching) power, but also with a secure global framework allowing users access to data • Good news: storing development data on the Grid keeps it available to the collaboration – not stuck on an old PC in the corner of the lab • Bad news: loss of ownership – who picks up the data curation responsibilities? • Data can be downloaded from the Grid to user’s “own” PC – doesn’t need to be analysed remotely 3 Henry Nebrensky – MICE DAQ review - 4 June 2009
Grid Middleware We are currently using EGEE/WLCG middleware and resources, as they are receiving significant development effort and are a reasonable match for our needs. Outside Europe other software may be expected – e.g. the OSG stack in the US. Interoperability has not been investigated by us yet. In the worst case, users would have to install a gLite UI locally. 4 Henry Nebrensky – MICE DAQ review - 4 June 2009
Grid File Management (1) Each file is given a unique, machine-generated, GUID when stored on the Grid The file is physically uploaded to one (or more) SEs (Storage Elements) where it is given a machine-generatedSURL (Storage URL) A “replica catalogue” tracks the multiple SURLs of a GUID Machine-generated names are not (meant to be) human-usable For sanity's sake we would like to associate sensible filenames with each file (LFN, Logical File Name) A “file catalogue” is a database that translates between something that looks like a Unix filesystem and the GUIDs and SURLs needed to actually access the data on the Grid 5 Henry Nebrensky – MICE DAQ review - 4 June 2009
Grid File Management (2) • MICE has an instance of LFC (LCGFile Catalogue) run by the Tier 1 at RAL • The LFC service can do both the replica and LFN cataloguing • LFC presents the user with what looks like a normal Unix filespace - the Grid client SW keeps track of the data behind the scenes. LFC From MICE Note 247 6 Henry Nebrensky – MICE DAQ review - 4 June 2009
Data Integrity (For recent SE releases) a checksum is calculated automatically when a file is uploaded. This can be checked when the file is transferred between SEs, or the value retrieved to check local copies. Should we also do it ourselves before uploading the file in the first place, or should we use “compression” (can check integrity with gunzip –t …)? (Default algorithm is Adler32 – lightweight + effective) 7 Henry Nebrensky – MICE DAQ review - 4 June 2009
The VOMS server File permissions will needed e.g. to ensure that users can’t accidentally delete RAW data. These rules will need to last for at least the life of the experiment. VOMS is a Grid service that allows us to define specific roles (e.g. DAQ data archiver) which will then be allowed certain privileges (such as writing to tape at RAL Tier 1). The VOMS service then maps humans to those roles, via their Grid certificates. MICE VOMS server is provided via GridPP at Manchester, UK. New Mice are added or assigned to roles by the VO Manager (and Mouse) Paul Hodgson. Thus the VOMS service provides us with a single portal where we can add/remove/reassign Mice, without needing to negotiate with the operators of every Grid resource worldwide – we actually keep control “in-house.” 8 Henry Nebrensky – MICE DAQ review - 4 June 2009
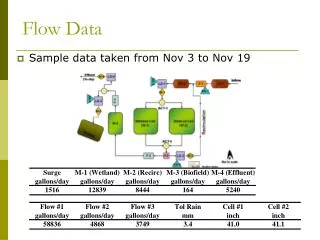
MICE Data Flow • The basic data flow in MICE is thus something like: • The raw data file from the experiment are sent to tape using Grid protocols, including registering the files in LFC. • The offline reconstruction can then use Grid/LFC to pull down the raw data, and upload reconstructed (“RECO” or DST) files. • Users can use Grid/LFC to access RECO files they want to play with. • Combining the above description with the Grid and work being done by current users gives: 9 Henry Nebrensky – MICE DAQ review - 4 June 2009
MICE Data Flow Diagram • Short-dashed lines indicate entities that still need confirmation • Question marks indicate even higher levels of uncertainty • More details in MICE Note 252 • The diagram would look pretty much the same if non-Grid tools were used 10 Henry Nebrensky – MICE DAQ review - 4 June 2009
MICE Data Unknowns • MICE Note 252 identifies four main flavours of data: RAW, RECO, analysis results, and Monte Carlo simulation. • For all four, we need to understand the: • volume (the total amount of data, the rate at which it will be produced, and the size of the individual files in which it will be stored) • lifetime (ephemeral or longer lasting? will it need archiving to tape? replication?) • access control (who will create the data? who is allowed to see it? can it be modified or deleted, and if so who has those privileges?) • “service level” (desired availability? allowable downtime?) • Also need to identify use cases I’ve missed, especially ones that will need more VOMS roles or CASTOR space tokens. 11 Henry Nebrensky – MICE DAQ review - 4 June 2009
File Catalogue Namespace (1) • Also, we need to agree on a consistent namespace for the file catalogue • Proposal (MICE Note 247, Grid talk at CM23): • We get given /grid/mice/ by the server • Five upper-level directories: • Construction/ historical data from detector development and QA • Calibration/ needed during analysis (large datasets, c.f. DB) • TestBeam/ test beam data • MICE/ DAQ output and corresponding MC simulation 12 Henry Nebrensky – MICE DAQ review - 4 June 2009
File Catalogue Namespace (2) • /grid/mice/users/name For people to use as scratch space for their own purposes, e.g. analysis • Encourage people to do this through LFC – helps avoid “dark data” • LFC allows Unix-style access permissions • Again, the LFC namespace is something that needs to be finalised before production data can start to be registered. 13 Henry Nebrensky – MICE DAQ review - 4 June 2009
Metadata Catalogue For many applications – such as analysis – you will want to identify the list of files containing the data that matches some parameters This is done by a “metadata catalogue”.For MICE this doesn't yet exist A metadata catalogue can in principle return either the GUID or an LFN – it shouldn’t matter which as long as it’s properly integrated with the other Grid services. 14 Henry Nebrensky – MICE DAQ review - 4 June 2009
MICE Metadata Catalogue • We need to select a technology to use for this • use the configuration database? (no) • gLite AMGA (who else uses it – will it remain supported?) • ? • Need to implement – i.e. register metadata to files • What metadata will be needed for analysis? • Should the catalogue include the file format and compression scheme (gzip ≠ PKzip)? 15 Henry Nebrensky – MICE DAQ review - 4 June 2009
MICE Metadata Cataloguefor Humans or, in non-Gridspeak: we have several databases (configuration DB, EPICS, e-Logbook) where we should be able to find all sorts of information about a run/timestamp. but how do we know which runs to be interested in, for our analysis? we need an “index” to the MICE data, and for this we need to define the set of “index terms” that will be used to search for relevant datasets. 16 Henry Nebrensky – MICE DAQ review - 4 June 2009
MICE Metadata • Run, date/time • Step • Beam – μ, e-, π, p • Nominal 4-d / transverse normalised emittance • Diffuser setting • Nominal momentum • Configuration: • Magnet currents (nominal) • Physical geometry • Absorber material • RF? • MC Truth? 17 Henry Nebrensky – MICE DAQ review - 4 June 2009
Conclusions The data flow is more complex than people realise… … and probably won’t work by accident Some specific issues that need to be understood are the attributes of the data flows (Note 252), the LFC Namespace (Note 247) and the index terms for the metadata catalogue. There is to be a one-day workshop in the next month to finalise these. 18 Henry Nebrensky – MICE DAQ review - 4 June 2009