Download

1 / 15
220 likes | 642 Views
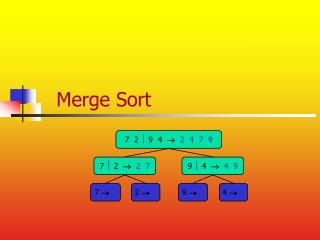
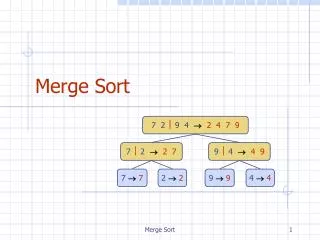
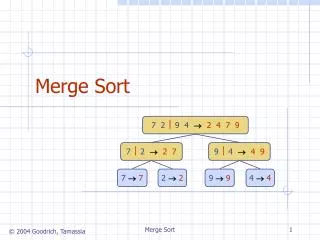
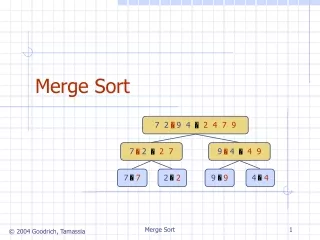
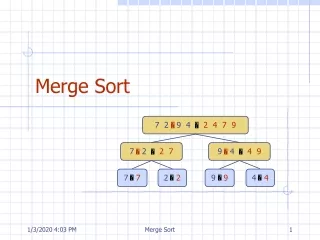
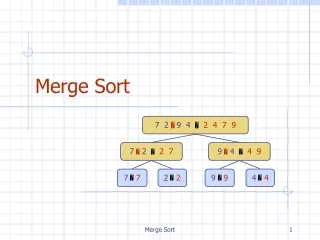
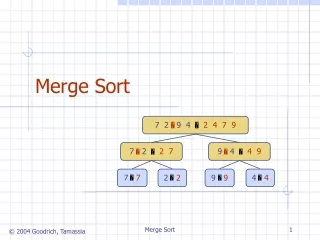
Two - Phase Multi-way Merge Sort. Submitted By:- Shams Azad Arun S. Abdullah Hattan. The Problem :. dataset of three different size we need to write Java program to sort the files. The sorting method is Two Phase Multi Way merge . The memory are restrict ed to 5 MB.

E N D
Two-Phase Multi-way Merge Sort Submitted By:- Shams Azad Arun S. Abdullah Hattan
The Problem : • dataset of three different size • we need to write Java program to sort the files. • The sorting method is Two Phase Multi Way merge. • The memory are restricted to 5 MB.
Design Principle • Have read the file and converted it to binary file to make calculation simple. As we don’t have to deal with encoding and decoding. • We have used dynamic size of block size. • Have used quick sort for sorting. • We have simply implemented 2PMMS.
Quick Sort • We have used quick sort for sorting as the data seems to be in jumbled . • The size of data was too in millions • Quick sort seems to be simple and efficient for this type of Data.
Data Structure • Array list has been used as a data structure. • Reading: • Buffer Reader. • File Reader. • Write: • File Write. • Print Writer. • Array: • Input Buffer. • Output Buffer. • Store the index. • List for storing the sub list
The Buffer: • We have taken dynamic memory to solve our problem. • We have not restricted it to any integer. • blockSize= ((memorySize/2)/numOfBuffers) • inputBuffers = new int[numOfBuffers][blockSize] • outputBuffer = new int [memorySize/2] • numOfBuffers = subListPointers.size
FREQUENT ITEMSET MINING Submitted By:- Shams Azad ArunS. Abdullah Hattan
PROBLEM STATEMENT • To compute the frequent itemsets of all size from a set of transactions based on input support threshold percentage. • The Application will read the data file as input and minimum support as in term of percentage. • Programming language restricted to java • Memory usage restricted to 5MB.
PCY Idea • Improvement upon A-Priori • Observe – during Pass 1, memory mostly idle • Idea • Use idle memory for hash-table H • Pass 1 – hash pairs from b into H • Increment counter at hash location • At end – bitmap of high-frequency hash locations • Pass 2 – bitmap extra condition for candidate pairs
Why we choose PCY - Motivation • Due to following reason we choose PCY over FP Growth and Apriori • 1) For Apriori Algorithm we need to scan the database again and again. Which is a time consuming job. • 2) For FP-Growth tree we need to have extra memory and extra cycle to create FP-tree again and again • 3) PCY uses memory efficiently.
BRIEF DESCRIPTION OF PCY • Pass 1 • m counters and hash-table T • Linear scan of baskets b • Increment counters for each item in b • Increment hash-table counter for each item-pair in b • Mark as frequent, f items of count at least s • Summarize T as bitmap (count > s bit = 1) • Pass 2 • Counter only for Fqualified pairs (Xi,Xj): • both are frequent • pair hashes to frequent bucket (bit=1) • Linear scan of baskets b • Increment counters for candidate qualified pairs of items in b
Design Principle • First we have read the Data file • Converted the .dat file to Binary • Have used ArrayList as a Data structure • Have used HashMap and hash function to find the frequent itemset with minimum support. • HashMap has two parameter initial Capacity and load factor. • Have created an ArrayList to store the frequent itemset.
Hash Function Used • int hash(int[] a) • Q = 433494437 • result = 0 • for each n in a: • result = result * Q + n * n • result *= Q • return Math.abs(result % 700000)
Result from Demo • The runtime comes out to be 200 sec.