Download

1 / 44
440 likes | 583 Views
Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing. Seminar: Ausgewählte Kapitel des Softcomputing Dezember 2007 . Gliederung. Einleitung k-Nearest-Neighbor Algorithmus Simulated Annealing Realisierung von KNN mit SA Zusammenfassung. Einleitung.

E N D
Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing Seminar: Ausgewählte Kapitel des Softcomputing Dezember 2007
Gliederung • Einleitung • k-Nearest-Neighbor Algorithmus • Simulated Annealing • Realisierung von KNN mit SA • Zusammenfassung Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Einleitung • Häufiges Problem in der Informatik: Große, ungeordnete/unbestimmte Datenmengen. • Webpages • Bildsammlungen • Datencluster • … • Lösung: Klassifikation, d.h. Einordnung der Daten in vorher bestimmte Klassen. • Spezialfall: Textklassifikation Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Textklassifikation Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Textklassifikation (2) • Anwendungen: • Klassifikation von Dokumenten • Filtern von Spam-Mails • … • Einzelne Dokumente sind für Menschen leicht zu klassifizieren. • Klassifizierung von großen Mengen an Dokumenten sehr zeitaufwendig. Maschinelle Klassifikation Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Textklassifikation (3) • Algorithmen/Methoden: • Decision Rules • Support Vector Machines • Naive Bayes • Neuronale Netze • Lineares Trennen • k-Nearest-Neighbor (KNN) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
k-Nearest-Neighbor • KNN einer der beliebtesten Algorithmen für Klassifizierung. • Verwendung z.B. bei Suchmaschinen. • Nachteil: KNN sehr rechenintensiv • Lösung: Beschleunigung von KNN durch heuristische Optimierungsverfahren Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
KNN (1) • Voraussetzung: Alle Instanzen eines Problems können als Punkte im dargestellt werden. • Algorithmus berechnet die k nächsten Nachbarn einer Instanz. • Abstandwird durch Distanzfunktionen bestimmt. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Distanzfunktionen • Beispiele für Distanzfunktionen: • Euklidische Distanz: • Kosinus Distanz: Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
5-NN Beispiel (1) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
5-NN Beispiel (2) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
5-NN Beispiel (3) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
KNN (2) • Fehlerwahrscheinlichkeit bzgl. des optimalen Bayes-Klassifikator: • Nachteil: Für jede Testinstanz muss die Distanz zu jeder anderen Instanz berechnet werden Hohe Komplexität Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Voraussetzungen (1) • Voraussetzungen für die Anwendung von KNN auf Textklassifikation: • Kodierung der Dokumente • Wissensbasis • Methode zur Kodierung: Feature Extraction. Features (lat. Wörter, chin. Schriftzeichen, etc.) des Dokumentes werden extrahiert und in schnellen Speicherstrukturen abgelegt. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Voraussetzungen (2) • Für jedes Feature wird zusätzlich eine Gewichtung gespeichert. • Mögliche Gewichtungen: • Relatives Wortvorkommen • Absolutes Wortvorkommen • Information Gain • … • Wissensbasis wird aus Trainingsdokumenten erstellt. • Für jedes Trainingsdokument: manuelle Ergänzung der Klasse Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel: Tabelle Hier: • Speicherstruktur: Tabelle. • Binäre Angabe, ob Wort in Dokument vorkommt. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Performance (1) • Vergleich mit anderen Algorithmen durch Benchmarks • Vergleichskriterien: • Precision: • Recall: • F1: F = Wobei D = #Dokumente, = # insg. korrekt zugewiesenen Dokumente = # vom Algorithmus korrekt zugewiesenen Dokumente Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Performance (2) • Benchmark von Yang/Sigir 1998 • Textsammlung: Reuter-Corpus 21578 Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Performance (3) • Fazit: SVM und KNN z.T. deutlich besser als andere Algorithmen • SVM jedoch effizienter als KNN Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Optimierung durch SA • Ziel: Beschleunigung von KNN. • Methode: Verwendung von heuristischen und Metaheuristischen Optimierungsverfahren zur Approximation der optimalen Lösung. • Gewähltes Verfahren: Simulated Annealing. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
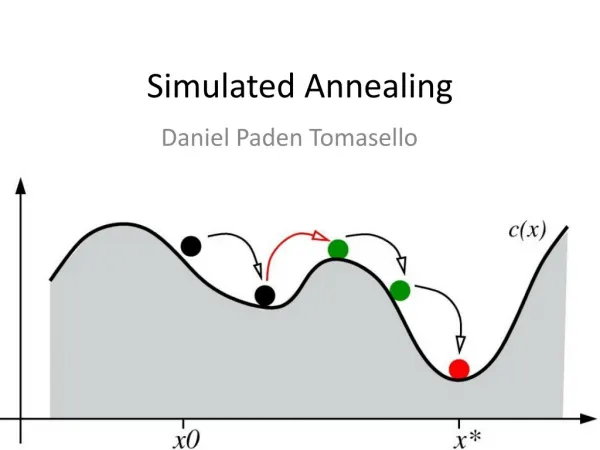
Simulated Annealing (1) • Simulated Annealing (SA) ist ein heuristisches Optimierungsverfahren zur Lösung von n-dimensionalen Optimierungsproblemen. • 1983 von Kirkpatrick, Gelatt und Vecchi vorgestellt • Urspung in der Mechanik beim sog. Glühen. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Simulated Annealing (2) • Benötigte Komponenten: • Energiefunktion • Funktion für zufällige Zustandsänderungen • Temperatur T und Abkühlungsstrategie • Entscheidungsfunktion für die Akzeptanz schlechterer Zustände Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Simulated Annealing (3) • Lösungen werden durch Vektoren repräsentiert • Energiefunktion Optimierungsfunktion Q(x) • Zustandsänderungen sind zufällige Änderungen in den Komponenten einer Lösung • Abkühlungsstrategie und Temperatur sollten problemabhängig gewählt werden • Wahrscheinlichkeit für Akzeptanz schlechterer Zustände: • Bessere Zustände werden immer akzeptiert. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Algorithmus Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (1) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (2) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (3) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (4) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (5) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (6) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Beispiel (7) Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Simulated Annealing (4) • Suchverhalten des Algorithmus wird von der Temperatur T und der Abkühlungsstrategie bestimmt: • Hohe Temperatur: • Schlechte Zustände werden häufig akzeptiert • Großer Teil des Suchraums wird erforscht • Niedrige Temperatur: • Schlechte Zustände werden selten akzeptiert • Suche wird lokaler • Vorteil von SA: Verlassen lokaler Minima Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Rahmenbedingungen (1) • Speicherstrukturen: • Dokumente samt Gewichtung werden in Arraylists gespeichert • Features werden in einer Featurelist gespeichert. • Gewichtung: Information Gain • Jedes Feature wird mit allen Dokumenten verlinkt, die es enthalten (verlinkte Feature-Arraylist) • Listen werden nach Gewichtung sortiert. • Erschaffung der Wissensbasis durch Feature Extraction der Trainingsdokumente. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Speicherstruktur Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Rahmenbedingungen (2) • Voraussetzungen für SA: • Lösungsrepräsentation Set von k Dokumenten (result) • Zustandsübergänge Abarbeitung der höchstgewichteten Features des Testdokumentes. • Starttemperatur T wird auf k gesetzt. • Initiale Lösung: erste k Dokumente aus der Arraylist des höchstgewichteten Features. • Übergangslösungen werden in temporären result set (temp) zwischengespeichert. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Algorithmus (1) • Suche Feature mit nächst höchster Wertung. • Speichere die T vordersten Dokumente in temp. • Berechne Distanzen zwischen dem Testdokument und temp und speichere sie. • Bestimme aus result und temp die k Dokumente mit dem geringsten Abstand und speichere sie in result. Dabei sei n die Anzahl der ersetzten Dokumente. • Falls n=0: Algorithmus beenden mit Lösung result. • Falls n>0: und beginne wieder mit Schritt 1. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Algorithmus (2) Modifiziertes SA: Schlechtere Zustände werden zwar in temp zwischengespeich- ert, allerdings nie akzeptiert. • Erklärungsansatz: Kaum lokale Optima, daher nicht notwendig, schlechte Zustände zu akzeptieren Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Tests • Vergleich des modifizierten KNN (KNN_SA) mit dem traditionellen KNN (KNN_trad) durch Benchmark. • Samples: • Peking-Corpus: 19.892 Webseiten • Sogou-Corpus: 17.910 Dokumente • Vergleichskriterien: • Precision • Performance Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Resultat Peking-Corpus Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Resultat Sogou-Corpus Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Resultat Allgemein • Generell: • Erkennungsrate beim Peking-Corpus höher • Beste Ergebnisse von KNN_trad für k=10, 25 • Beste Ergebnisse von KNN_SA für T=35,50 • Vergleich: • Precision von KNN_trad geringfügig besser • Performance von KNN_SA viel besser Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Zusammenfassung • KNN ist ein einfach zu realisierender Algorithmus, der im Vergleich mit anderen Verfahren guteErgebnisse liefert, allerdings sehr uneffizient ist. • Simulated Annealing ist ein heuristisches Optimierungsverfahren mit der Stäke, lokale Optima verlassen zu können. • Die Realisierung von KNN mit SA liefert zwar geringfügig schlechtere Ergebnisse, ist allerdings viel effizienter als das traditionelle KNN. Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Offene Fragen… • Stärke von SA, das Verlassen lokaler Optima, wird nicht genutzt: Ist SA wirklich geeignet für diese Realisierung? • Wie ist die Performance von anderen Optimierungsverfahren wie GA, PSO, ACO,… ? Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing
Schlusswort Vielen Dank für ihre Aufmerksamkeit! Marcel Scheibmayer: Schnelle k-Nearest-Neighbor Algorithmen auf der Basis von Simulated Annealing