Download
1 / 16
160 likes | 366 Views
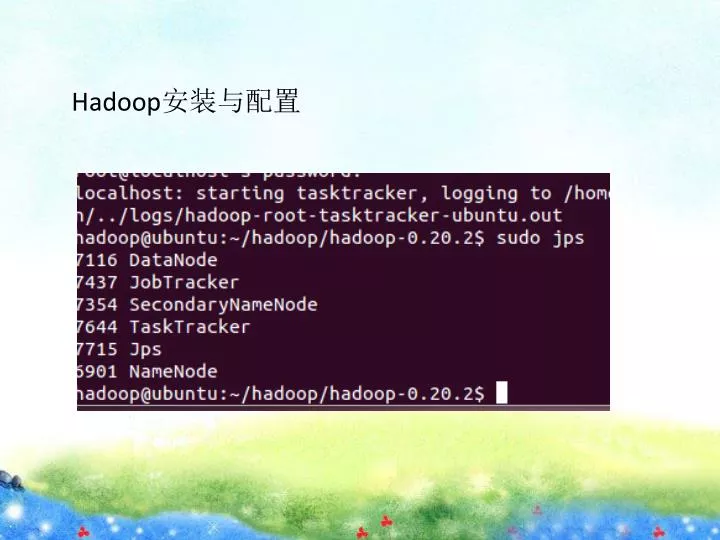
Hadoop 安装与配置. NameNode 无法启动,则需要重新格式化 namenode. WordCount 程序解析. public class WordCount {

E N D
WordCount程序解析 public class WordCount { public static class Map extends MapReduceBase implementsMapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value,OutputCollector<Text, IntWritable> output, Reporter reporter)throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); }}}
public static class Reduce extends MapReduceBase implementsReducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } }
Pig 的安装与使用 • 下载pig-0.10.0,解压到相应目录 • ./bashrc 文件的配置 export JAVA_HOME=/usr/lib/jvm/java-7-sun export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH export Pig_HOME=/home/hadoop/pig-0.10.0 export PATH=/home/hadoop/pig-0.10.0/bin:$PATH export Pig_CLASSPATH=$HADOOP_HOME/conf
Pig 的安装与使用 • 安装成功之后,使用pig -help 查看,显示安装成功 • Pig –x local 登陆,本地模式(便于验证)
使用pig进行简单的读写 结果如图
聚类操作 结果如图
关系运算符的操作 结果如图
关系运算符的操作:Split 结果如图
关系运算符的操作:过滤 结果如图
关系运算符的操作:聚类 结果如图
经验总结及感悟 对linux平台的命令行要熟悉(文本编辑工具、用户权限指令) 开发者应该Hadoop及其插件配置的繁琐的细节屏蔽掉,不要交给用户去做



















