Download

1 / 33
340 likes | 457 Views
Cross Tabs and Chi-Squared. Testing for a Relationship Between Nominal Variables. Cross Tabs and Chi-Squared. The test you choose depends on level of measurement: Independent Dependent Test Dichotomous Continuous Independent Samples t-test Dichotomous Nominal Nominal Cross Tabs

E N D
Cross Tabs and Chi-Squared Testing for a Relationship Between Nominal Variables
Cross Tabs and Chi-Squared The test you choose depends on level of measurement: Independent Dependent Test Dichotomous Continuous Independent Samples t-test Dichotomous Nominal Nominal Cross Tabs Dichotomous Dichotomous Nominal Continuous ANOVA Dichotomous Dichotomous Continuous Continuous Bivariate Regression/Correlation Dichotomous
Cross Tabs and Chi-Squared We are asking whether there is a relationship between two nominal variables—this includes dichotomous variables. One may also use cross tabs for ordinal variables, but it is generally better to treat them as interval variables and use more powerful statistical techniques.
Cross Tabs and Chi-Squared Cross tabs and Chi-Squared will tell you whether classification on one nominal variable is related to classification on a second nominal variable. For Example: Are rural Americans more likely to vote Republican in presidential races than urban Americans? Classification of Region Party Vote Are white people more likely to drive SUV’s than blacks or Hispanics? Race Type of Vehicle
Cross Tabs and Chi-Squared The statistical focus will be on the number of people in a sample who are classified in patterned ways on two variables. Why? Means and standard deviations are meaningless for nominal variables.
Cross Tabs and Chi-Squared The procedure starts with a “cross classification” of the cases in categories of each variable. Example: Data on male and female support for USA football from 650 students put into a matrix Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650
Cross Tabs and Chi-Squared In the example, I can see that the campus is divided on the issue. But are there associations between sex and attitudes? Example: Data on male and female support for USA football from 650 students put into a matrix Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650
Cross Tabs and Chi-Squared But are there associations between sex and attitudes? An easy way to get more information is to convert the frequencies to percentages. Example: Data on male and female support for USA football from 650 students put into a matrix Yes No Maybe Total Female: 185 (41%) 200 (44%) 65 (14%) 450 (99%)* Male: 80 (40%) 65 (33%) 55 (28%) 200 (101%) Total: 265 (41%) 265 (41%) 120 (18%) 650 (100%) *percentages d not add to 100 due to rounding
Cross Tabs and Chi-Squared We can see that in the sample men are less likely to oppose football, but no more likely to say “yes” than women—men are more likely to say “maybe” Example: Data on male and female support for USA football from 650 students put into a matrix Yes No Maybe Total Female: 185 (41%) 200 (44%) 65 (14%) 450 (99%)* Male: 80 (40%) 65 (33%) 55 (28%) 200 (101%) Total: 265 (41%) 265 (41%) 120 (18%) 650 (100%) *percentages d not add to 100 due to rounding
Cross Tabs and Chi-Squared Data on male and female support for USA football from 650 students put into a matrix Yes No Maybe Total Female: 185 (41%) 200 (44%) 65 (14%) 450 (99%)* Male: 80 (40%) 65 (33%) 55 (28%) 200 (101%) Total: 265 (41%) 265 (41%) 120 (18%) 650 (100%) *percentages d not add to 100 due to rounding Using percentages to describe relationships is valid statistical analysis: These are descriptive statistics! However, they are not inferential statistics. What can we say about the population? Could we have gotten sample statistics like these from a population where there is no association between sex and attitudes about starting football? This is where the Chi-Squared Test of Independence comes in handy.
Cross Tabs and Chi-Squared The whole idea behind the Chi-Squared test of independence is to determine whether the patterns of frequencies in your cross classification table could have occurred by chance, or whether they represent systematic assignment to particular cells. For example, were women more likely to answer “no” than men or could the deviation in responses by sex have occurred because of random sampling or chance alone?
Cross Tabs and Chi-Squared A number called Chi-Squared, 2, tells us whether the numbers in our sample deviate from what would be expected by chance. It’s formula: fo= observed frequency in each cell fe= expected frequency in each cell A bigger 2 will result as our sample data deviates more and more from what would be expected by chance. A big 2 will imply that there is a relationship between our two nominal variables. 2 = ((fo - fe)2 / fe)
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Calculating 2 begins with the concept of a deviation of observed data from what is expected by chance alone. Deviation in 2 = Observed frequency – Expected frequency Observed frequency is just the number of cases in each cell of the cross classification table. For example, 185 women said “yes,” they support football at USA. 185 is the observed frequency. Expected frequency is the number of cases that would be in a cell of the cross classification table if people in each group of one variable had a propensity to answer the same as each other on the second variable.
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Data on male and female support for USA football from 650 students Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650 Expected frequency (if our variables were unrelated): Since females comprise 69.2% of the sample, we’d expect 69.2% of the “Yes” answers to come from females, 69.2% of the “No” answers to come from females, and 69.2% of the “Maybe” answers to come from females. On the other hand, 30.8% of the “Yes,” “No,” and “Maybe” answers should come from Men. Therefore, to calculate expected frequency for each cell you do this: fe = cell’s row total / table total * cell’s column total or fe = cell’s column total / table total * cell’s row total The idea is that you find the percent of persons in one category on the first variable, and “expect” to find that percent of those people in the other variable’s categories.
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Data on male and female support for USA football from 650 students Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650 Now you know how to calculate the expected frequency (and the observed frequency is obvious). fe1 = (450/650) * 265 = 183.5 fe4 = (200/650) * 265 = 81.5 fe2 = (450/650) * 265 = 183.5 fe5 = (200/650) * 265 = 81.5 fe3 = (450/650) * 120 = 83.1 fe6 = (200/650) * 120 = 36.9 You already saw how to calculate the deviations too. Dc = fo – fe D1 = 185 – 183.5 = 1.5 D4 = 80 – 81.5 = -1.5 D2 = 200 – 183.5 = 16.5 D5 = 65 – 81.5 = -16.5 D3 = 65 – 83.1 = -18.1 D4 = 55 – 36.9 = 18.1
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Data on male and female support for USA football from 650 students Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650 Deviations: Dc = fo – fe D1 = 185 – 183.5 = 1.5 D4 = 80 – 81.5 = -1.5 D2 = 200 – 183.5 = 16.5 D5 = 65 – 81.5 = -16.5 D3 = 65 – 83.1 = -18.1 D4 = 55 – 36.9 = 18.1 Now, we want to add up the deviations… What would happen if we added these deviations together? To get rid of negative deviations, we square each one (like in computing standard deviations).
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Data on male and female support for USA football from 650 students Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650 Deviations: Dc = fo – fe D1 = 185 – 183.5 = 1.5 D4 = 80 – 81.5 = -1.5 D2 = 200 – 183.5 = 16.5 D5 = 65 – 81.5 = -16.5 D3 = 65 – 83.1 = -18.1 D4 = 55 – 36.9 = 18.1 To get rid of negative deviations, we square each one (like in standard deviations). (D1)2 = (1.5)2 = 2.25 (D4)2 = (-1.5)2 = 2.25 (D2)2 = (16.5)2 = 272.25 (D5)2 = (-16.5)2 = 272.25 (D3)2 = (-18.1)2 = 327.61 (D6)2 = (18.1)2 = 327.61
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Squared Deviations: (D1)2 = (1.5)2 = 2.25 (D4)2 = (-1.5)2 = 2.25 (D2)2 = (16.5)2 = 272.25 (D5)2 = (-16.5)2 = 272.25 (D3)2 = (-18.1)2 = 327.61 (D6)2 = (18.1)2 = 327.61 Just how large is each of these squared deviations? The next step is to give the deviations a “metric.” The deviations are compared relative to the what was expected. In other words, we divide by what was expected. You’ve already calculated what was expected in each cell: fe1 = (450/650) * 265 = 183.5 fe4 = (200/650) * 265 = 81.5 fe2 = (450/650) * 265 = 183.5 fe5 = (200/650) * 265 = 81.5 fe3 = (450/650) * 120 = 83.1 fe6 = (200/650) * 120 = 36.9 Relative Deviations-squared—Small values indicate little deviation from what was expected, while larger values indicate much deviation from what was expected: (D1)2 / fe1 = 2.25 / 183.5 = 0.012 (D4)2 / fe4 = 2.25 / 81.5 = 0.028 (D2)2 / fe2 = 272.25 / 183.5 = 1.484 (D5)2 / fe5 = 272.25 / 81.5 = 3.340 (D3)2 / fe3 = 327.61 / 83.1 = 3.942 (D6)2 / fe6 = 327.61 / 36.9 = 8.878
2 = ((fo - fe)2 / fe) Cross Tabs and Chi-Squared Relative Deviations-squared—Small values indicate little deviation from what was expected, while larger values indicate much deviation from what was expected: (D1)2 / fe1 = 2.25 / 183.5 = 0.012 (D4)2 / fe4 = 2.25 / 81.5 = 0.028 (D2)2 / fe2 = 272.25 / 183.5 = 1.484 (D5)2 / fe5 = 272.25 / 81.5 = 3.340 (D3)2 / fe3 = 327.61 / 83.1 = 3.942 (D6)2 / fe6 = 327.61 / 36.9 = 8.878 The next step will be to see what the total relative deviations-squared are: Sum of Relative Deviations-squared = 0.012 + 1.484 + 3.942 + 0.028 + 3.340 + 8.878 = 17.684 This number is also what we call Chi-Squared or 2. So… Of what good is knowing this number? 2 = ((fo - fe)2 / fe)
Cross Tabs and Chi-Squared This value, 2, would form an identifiable shape in repeated sampling if the two variables were unrelated to each other. That shape depends only on the number of rows and columns. We technically refer to this as the “degrees of freedom.” For 2, df =(#rows – 1)*(#columns – 1)
Cross Tabs and Chi-Squared For 2, df =(#rows – 1)*(#columns – 1) 2 distributions: df = 5 FYI: This should remind you of the normal distribution, except that, it changes shape depending on the nature of your variables. df = 10 df = 20 df = 1 1 5 10 20
Cross Tabs and Chi-Squared Think of the Power!!!! We can use the known properties of the 2 distribution to identify the probability that we would get our sample’s 2 if our variables were unrelated! This is exciting!
Cross Tabs and Chi-Squared If our 2 in a particular analysis were under the shaded area or beyond, what could we say about the population given our sample? 5% of 2 values
Cross Tabs and Chi-Squared Answer: We’d reject the null, saying that it is highly unlikely that we could get such a large chi-squared value from a population where the two variables are unrelated. 5% of 2 values
Cross Tabs and Chi-Squared So, what is the critical 2 value? 5% of 2 values
Cross Tabs and Chi-Squared That depends on the particular problem because the distribution changes depending on the number of rows and columns. df = 5 df = 10 df = 20 df = 1 1 5 10 20 Critical 2 ‘s
Cross Tabs and Chi-Squared According to Table C, df = 1, critical 2 = 3.84 with -level = .05, if: df = 5, critical 2 = 11.07 df = 10, critical 2 = 18.31 df = 20, critical 2 = 31.41 df = 5 df = 10 df = 20 df = 1 1 5 10 20
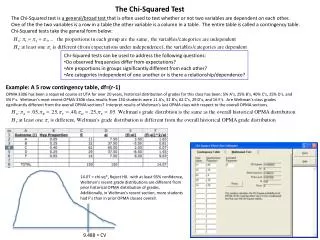
Cross Tabs and Chi-Squared In our football problem above, we had a chi-squared of 17.68 in a cross classification table with 2 rows and 3 columns. Our chi-squared distribution for that table would have df = (2 – 1) * (3 – 1) = 2. According to Table C, with -level = .05, Critical Chi-Squared is: 5.99. Since 17.68 > 5.99, we reject the null. We reject that our sample could have come from a population where sex was not related to attitudes toward football.
Cross Tabs and Chi-Squared Now let’s get formal… 6 steps to Chi-squared test of independence: • Set -level (e.g., .05) • Find Critical 2 (depends on df and -level) • The null and alternative hypotheses: Ho: The two nominal variables are independent Ha: The two variables are dependent on each other • Collect Data • Calculate 2 : 2 = ((fo - fe)2 / fe) • Make decision about the null hypothesis
Cross Tabs and Chi-Squared Afterwards, what have you found? If Chi-Squared is not significant, your variables are unrelated. If Chi-Squared is significant, your variables are related. That’s All! Chi-Squared cannot tell you anything like the strength or direction of association. For purely nominal variables, there is no “direction” of association. Chi-Squared is a large-sample test. If dealing with small samples, look up appropriate tests. (A condition of the test: no expected frequency lower than 5 in each cell) The larger the sample size, the easier it is for Chi-Squared to be significant. 2 x 2 table Chi-Square gives same result as Independent Samples t-test for proportion and ANOVA.
Cross Tabs and Chi-Squared If you want to know how you depart from independence, you may: • Check percentages (conditional distributions) in your cross classification table. • Do a residual analysis: The difference between observed and expected counts in a cell behaves like a significance test when divided by a standard error for the difference. That s.e. = fe*(1-cell’s row )*(1 – cell’s column ) fo – fe Z = s.e.
Cross Tabs and Chi-Squared Residual Analysis: Let’s do cell 5! s.e. = fe*(1-cell’s row )*(1 – cell’s column ) fo – fe #5 row = 200/650 = .308, column = 265/650 = .408 Z = s.e. s.e. = 81.5 * (.692) * (.592) = 5.78 Z = 65 – 81.5 / 5.78 = -2.85; 2.85 > 1.96, there is a significant difference in cell 5 Data on male and female support for USA football from 650 students Yes No Maybe Total Female: 185 200 65 450 Male: 80 65 55 200 Total: 265 265 120 650 fe1 = (450/650) * 265 = 183.5 fe4 = (200/650) * 265 = 81.5 fe2 = (450/650) * 265 = 183.5 fe5 = (200/650) * 265 = 81.5 fe3 = (450/650) * 120 = 83.1 fe6 = (200/650) * 120 = 36.9 Deviations: Dc = fo – fe D1 = 185 – 183.5 = 1.5 D4 = 80 – 81.5 = -1.5 D2 = 200 – 183.5 = 16.5 D5 = 65 – 81.5 = -16.5 D3 = 65 – 83.1 = -18.1 D4 = 55 – 36.9 = 18.1
Cross Tabs and Chi-Squared Further topics you could explore: Strength of Association • Discussing outcomes in terms of difference of proportions • Reporting Odds Ratios (likelihood of a group giving one answer versus other answers or the group giving an answer relative to other groups giving that answer) Strength and Direction of Association for Ordinal Variables • Gamma (an inferential statistic, so check for significance) Ranges from -1 to +1 Valence indicates direction of relationship Magnitude indicates strength of relationship Chi-squared and Gamma can disagree when there is a nonrandom pattern that has no direction. Chi-squared will catch it, gamma won’t. • Kendall’s tau-b • Somer’s d