Download
1 / 6
60 likes | 231 Views
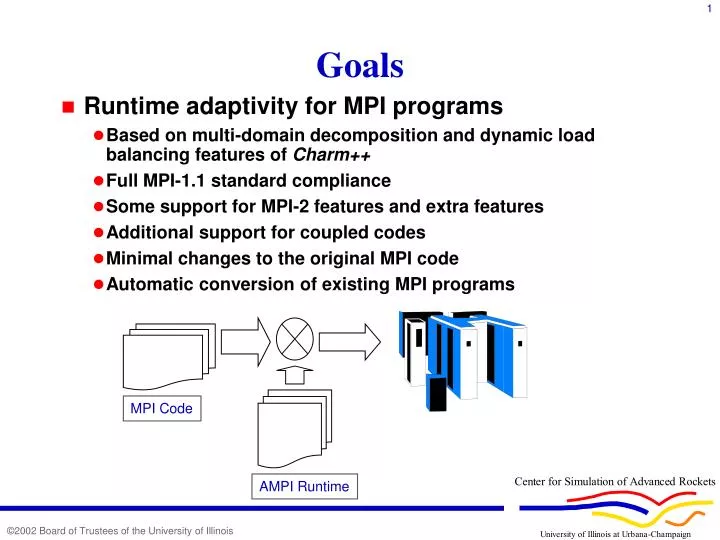
MPI Code. AMPI Runtime. Goals. Runtime adaptivity for MPI programs Based on multi-domain decomposition and dynamic load balancing features of Charm++ Full MPI-1.1 standard compliance Some support for MPI-2 features and extra features Additional support for coupled codes

E N D
MPI Code AMPI Runtime Goals • Runtime adaptivity for MPI programs • Based on multi-domain decomposition and dynamic load balancing features of Charm++ • Full MPI-1.1 standard compliance • Some support for MPI-2 features and extra features • Additional support for coupled codes • Minimal changes to the original MPI code • Automatic conversion of existing MPI programs
Features • Gen2 and Gen2.5 now running with AMPI • RocFlo, RocFlomp, RocFlu, RocFrac, RocFace, RocCom • Asynchronous collective operations • Automatic checkpoint/restart • On different number of physical processors, and/or • On different number of virtual MPI processors • New support for dynamic allocations frees user from writing pack/unpack routines • Full compliance with MPI-1.1 Standard and partially MPI-2 • ROMIO is integrated in AMPI as its parallel I/O library • New features support porting MPI programs to AMPI • Recompile programs with a different header file • Re-link with Charm libraries • AMPI modules can now coexist and interact with modules written using Charm’s component frameworks
7 MPI “processes” Real Processors Implementations • Virtualization overhead is small • A migration path for legacy MPI codes: AMPI = MPI + dynamic load balancing • Uses Charm++ object arrays and migratable user-level threads • Each MPI process is implemented as a migratable thread • Load balancer migrates threads as needed
Asynchronous Collective Operations • This graph shows the time breakdown of an all-to-all operation using Mesh library. Only a small proportion of the elapsed time is spent on computation. • Asynchronous collective operations: AMPI overlaps useful computation with the waiting time of collective operations and reduces the total completion time.
Phase 16P3 16P2 8P3,8P2 w/o LB 8P3,8P2 w/ LB Fluid update 75.24 97.50 96.73 86.89 Solid update 41.86 52.50 52.20 46.83 Pre-Cor Iter 117.16 150.08 149.01 133.76 Time Step 235.19 301.56 299.85 267.75 Performance Data • The power of Virtualization • Running your program on any given number of physical processors • Charm++ provides: • Load balancing framework • Seamless object migration support • Migrating threads “Overhead” of multi-partitioning AMPI runs on any given number of PEs (eg 19, 33, and 105), but vendor MPI needs cube number. Problem setup: Jacobi 3D problem size 2403 run on LeMieux.
Future Plans • MPI-2 Implementation • Integrating ROMIO into AMPI • One-sided communications • Language bindings • Handling Global Variables • Making global variables thread-safe with the ELF library • With this feature, all existing MPI programs would become legal AMPI programs • Fault Tolerance Features • Automatic recovery • Minimal impact on forward execution • Scalable recovery • Avoid rolling back all processors






















