Download

1 / 18
180 likes | 312 Views
Motif Discovery in Heterogeneous Sequence Data. Mathieu Blanchette McGill U. Montreal. Saurabh Sinha Rockefeller U. New York. Amol Prakash U. Washington Seattle. Martin Tompa U. Washington Seattle. Outline. What is a motif? Homogeneous vs. Heterogeneous

E N D
Motif Discovery in Heterogeneous Sequence Data Mathieu Blanchette McGill U. Montreal Saurabh Sinha Rockefeller U. New York Amol Prakash U. Washington Seattle Martin Tompa U. Washington Seattle
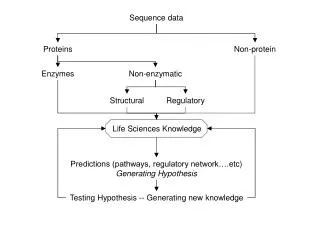
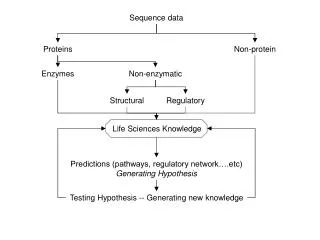
Outline • What is a motif? • Homogeneous vs. Heterogeneous • What makes our approach unique • Algorithm description • Results • Conclusion
CAGTGTTAGTCTCGACGTGAGTGGTATGAACTGGAGTTTTAGTATGATGGTCGTACAGTGTTTCGACATGGGAAGCAGTGTTAGTCTCGACGTGAGTGGTATGAACTGGAGTTTTAGTATGATGGTCGTACAGTGTTTCGACATGGGAAG Predicting Regulatory Elements • Functionally important: binding site for a protein that regulates gene expression • Near gene • Short: Typically 6-20 nucleotides • How can you possibly predict them?
Homogeneous Sequence Data I • Input: DNA sequences near co-regulated genes from a single organism • Tools : MEME, Consensus, Gibbs sampler, Projection, YMF, and many others. CAR2 AGTCTCGACGTGAGTTTGCCTTAGGTGGTAGTTTTAAACAGTCTCGACTAGTCTCGATCGTACAGTGTTTAGTCTTTCGACATG ARG5,6 TTTTTTCCATTAGGTGGAGTTTTTTAGGTCTCGACAGTCTCGACTCGTTAGTCTCGAATACAGTTTAGTCTCGAGTTTCGACATG CAR1TCTCGACAGTTTTCACTTAGCGTTTTATCTCGAGACGTGAGTATGCCATTAGCTGGACATG
Homogeneous Sequence Data II • DNA sequences near orthologous genes • Tools: • Multiple alignment (ClustalW, etc.), then find highly conserved aligned regions • FootPrinter CCTTGGACCAAGTCCAGCACCCTCGGGGTCGAGGAAAACAGGTAGGGTATAAAAAGGGCATGCAAGGACCTGCAGCCAAGCTTGCAGGTAGGGTATAAAAAGGGCACGCAAGGGACCCCAAAAAAAGAAACTGCTCAGAGTCCTGTGGACAGATCACTGCTTGGCAAGAAGTGATAGATGGGGCCAGGGTATAAAAAGGGCCCAACTCCCCGAACCACTCAGGGTCCTGTGGACAGCTCACCTAGCTGCAAGAGGGCCCCAAAGCGCTCAGGGTCCTGTGGACAAGGGACCAGGGTATAAAGAGGGCCCGCACAGCTGGCTCACCCCGGCTGCG
Heterogeneous Sequence Data • Co-regulated genes from one species, and their orthologs from other species. Rat Mouse Human g1.rn g1.mm g1.hs g2.rn g2.mm g2.hs g3.rn g3.mm g3.hs g4.rn g4.mm g4.hs
Heterogeneous Data : Approach 1 • Pool everything together • Search for statistical overrepresentation g3.mm g2.hs g1.mm g2.rn g1.rn g4.hs g4.rn g4.mm g1.hs g3.hs g2.mm g3.rn Gelfand et al. 2000 , McGuire et al. 2000
Rat Mouse Human Heterogeneous Data : Approach 2 • Filter well conserved orthologous regions • Search for overrepresentation in one species g1.rn g1.mm g1.hs g2.rn g2.mm g2.hs g3.rn g3.mm g3.hs g4.rn g4.mm g4.hs Wasserman et al. 2000 , Kellis et al. 2003, Cliften et al. 2003, Wang & Stormo 2003
Human Rat Mouse Heterogeneous Data : Approach 3 • Filter overrepresentation in co-regulated regions. • Search for well conserved orthologous regions g1.mm g1.rn g1.hs g2.mm g2.rn g2.hs g3.mm g3.rn g3.hs g4.mm g4.rn g4.hs GuhaThakurta et al. 2002
OrthoMEME : Our Approach • An integrated approach: no “filtering” step • Treats orthology and co-regulation differently. • Based on Expected-Maximization • Does not use global alignment, which can fail on diverged sequences. • Focus on two-species case
OrthoMEME: Algorithm • Maximization of Expected Likelihood • Model • As MEME, uses a “profile” to model the motifs in one genome • Another “phylogenetic profile” to model motifs in orthologous regions.
OrthoMEME : Profile Profile [ ] 0.75 … 0.25 … 0 … 0 … Rat Human A... g1.rn g1.hs C… g2.rn g2.hs A… g3.rn g3.hs A… g4.rn g4.hs
Phylogenetic Profile [ ] Profile [ ] A C G T A 0.67 0.33 0 0 … C 0 1 0 0 … G 0 0 0 0 … T 0 0 0 0 … [ ] 0.75 … 0.25 … 0 … 0 … Rat Human A... A... g1.rn g1.hs C… C… g2.rn g2.hs C… A… g3.rn g3.hs A… A… g4.rn g4.hs
Experimental Results • Implemented and tested on various pairs of species • Compared to MEME • on single species data • same parameters • Results from top 3 motifs are reported.
Result 1 : Mammals • SRF motif • OrthoMEME missed 2 occurrences • MEME found none
Result 2 : Yeast • HAP2;HAP3;HAP4 motif • OrthoMEME missed 2 occurrences • MEME missed 4 occurrences
Result 3 : Worm • DAF-19 motif • OrthoMEME missed no occurrences • MEME missed no occurrences
Conclusion • First integrated algorithm to handle heterogeneous sequence data. • Focus on two species case • Improve algorithm for multiple species. • More experiments will help us improve the tool/parameters.