Download

1 / 62
660 likes | 1.18k Views
制限付き最尤法 REML; Restricted Maximum Likelihood. 増田 豊. 正規分布と最尤法 Normal Distribution and Maximum Likelihood. 正規分布. 正規分布と母数. 分布の特性を表す値を母数という 正規分布の母数は m と s 2 である m 頻度が最大になる位置(平均) s 2 分布の広がり(分散) ある変数 Y が正規分布に従うとき Y ~ N ( m , s 2 ) と表記する. m と分布のイメージ. m は頻度が最大になる位置(平均)を表す. s 2 と分布のイメージ.

E N D
正規分布と最尤法Normal Distribution and Maximum Likelihood
正規分布と母数 • 分布の特性を表す値を母数という • 正規分布の母数は mと s2である • m頻度が最大になる位置(平均) • s2分布の広がり(分散) • ある変数 Yが正規分布に従うとき Y ~N( m, s2 ) と表記する
mと分布のイメージ • mは頻度が最大になる位置(平均)を表す
s2と分布のイメージ • s2は分布の広がり(分散)を表す
母集団と標本 • 正規母集団からの標本も正規分布をなす • 標本(データ)から母数を推定することができる → 統計的推測
統計的推測の例 • ある中学校の生徒30人の身長を測定した • 母集団(この学校の全生徒)の身長の平均と分散を推定したい。 • 身長測定値は正規分布に従うとする。
N ( 165, 15 ) N ( 165, 10 ) N ( 165, 5 ) 正規分布の当てはめ
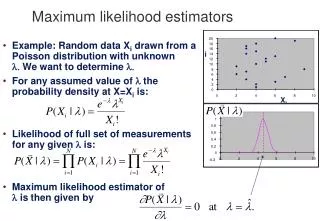
尤度 (l) • データが、特定の分布にどの程度当てはまっているかを示す数値 • 尤度が大きいほど、よく当てはまっている • 尤度の自然対数がよく用いられる (対数尤度 ... log l)
尤度の計算 • 尤度と対数尤度は以下のように計算する
尤度が最大になる点 ただし s2は不偏分散、 S2は標本分散
最尤法と最尤推定量 • データを固定して母数を動かし、尤度を最大にする母数を探す方法を最尤法という。 • このときの値を最尤推定量という。 • この場合は、以下のようになる。 および
最尤法と尤度関数 • 尤度 lの値はmとs2の値によって変動する • 尤度を母数 m と s2 の関数と見なすとき、これを尤度関数という。 • 最尤法は、尤度関数を最大にする母数を求める方法である。 • 結局は関数の最大値を求める問題である。
尤度関数の最大値を探す • 母数を適当に動かし、そのつど尤度を計算する方法が、直接検索法である • 直接検索法は、求める母数が多くなると、ちょっと(かなり)面倒である • 二分法やシンプレックス法などがある • 直接検索法を用いることは derivative-free(DF)であると言われる
最尤法の問題点 • 記録数が少ないときに偏りがある • 平均と分散の両方を推定することによるもの • この例の場合では、不偏分散ではない • 尤度関数を最大にする点を探すのが困難 • この例の場合は、簡単に求められる • 一般には、面倒な数値計算が必要である • REMLでもこの問題は解消されない
モデル • 以下のモデルを仮定する • y = Xb + e = 1m + e • y:観察値, m:集団平均, e:残差(変量効果) • yは多変量正規分布に従う • 期待値と分散を以下のように仮定する • E(y) = Xb = 1m • Var(y) = Var(e) = Is2
最尤推定量 (ML) • log L を最小にする mと s2の値 • log Lを mと s2で偏微分し、0とする (関数の最小値を求める) • この場合は、以下のようになる および
偏微分した式に注目する • s2の式に mが含まれている • いま mが未知なので、 で代用する • 推定量の中に推定量を含んでいる • この結果、 の値によって が変化する • の値による変動はどの程度かを調べる
条件付き期待値 • 標本 と分散 を仮定したときの期待値 • 分散は未知なので、適当な値を仮定する
条件付き期待値の値 • 標本平均 の分布は次のようになる • 分散の定義から、条件付き期待値の値は
推定式 • 適当な値 を設定し、 を計算する • 求めた を に代入し、計算を繰り返す • 値が動かなくなったとき「収束」したという
収束値 • この収束値をREML推定量という • この場合は、不偏分散である • 分散についてはMLよりもREMLのほうが好ましい推定量であるようだ
EMアルゴリズム • 「期待値をとる→代入」を繰り返す方法 • 計算式が単純である • 解が必ず母数空間内に収束する • 収束が非常に遅い (収束値に近づくほど、速度が遅くなる)
REML推定量を導く方法 • ML推定量を修正する • 今回の例のように式変形して期待値をとる • 尤度関数そのものを修正する • 尤度関数に mが含まれないようにする • 用いる尤度関数が違うだけで、考え方はMLと全く同じである • 制限付き尤度関数を最大にする母数を求める
主なアプローチ • derivative-freeな方法 • 直接検索により試行錯誤的に求める • EMアルゴリズム • 尤度関数を1回だけ微分して期待値をとる • 数値計算による方法 • 収束が非常に速い • 尤度関数を2回微分した式が必要になる
考え方 • 尤度関数を最大とする値を得たい = 1次導関数が 0 となる点を探す • 式で考えれば簡単だが、コンピュータにとっては困難(具体的な数値しか扱えない) • 徐々に解に近づくような計算を繰り返す • これを「数値計算」という
この点で接する接線を求める (x0, g(x0)) ニュートン・ラフソン法 g(x) y=a x+b 傾き a: g’(x0) 切片 b: g(x0)-g’(x0)x0 接線 y= g’(x0) x+g(x0)-g’(x0)x0 x x0
x軸と交わる点 x1を求める ニュートン・ラフソン法 g(x) 接線 y= g’(x0) x+g(x0)-g’(x0)x0 y=0 を代入して x1を求める x x1 x0
r 回めの反復結果 ニュートン・ラフソン法 g(x) これを繰り返して近似値を得る x x2 x1 x0
ニュートン・ラフソン法 r 回めの反復結果 g(x) に相当するのは log Lrの1次導関数である
1次および2次導関数 • 反復式は以下のようになる
ニュートン・ラフソン法の特徴 • 初期値によっては収束しない • 収束値から離れた値を与えると発散しやすい • 収束値付近では速度が上昇する • 負の分散が推定されることがある • 2次導関数(分母)の式が複雑になる • 計算量が多くなりやすい
スコアリング法 • 2次導関数のかわりに、期待値を用いる • 反復式は以下のようになる
スコアリング法の特徴 • 非常に収束しやすい • 母数効果のみを含むモデルの場合は、反復式が非常に簡単になる • Fisherのスコアリング法とも呼ばれる • 尤度関数の2次導関数の負の期待値が、Fisher情報量と呼ばれているため
AIアルゴリズム • ニュートン・ラフソン法とスコアリング法で用いた分母を「平均」する • これを分母として反復式をつくる
AIアルゴリズム • AI = Average Information である • ニュートン・ラフソン法よりは収束しやすい • スコアリング法よりは発散しやすい • 混合モデルの場合は、他の方法よりも計算量が少ない
モデル • 以下のモデルを仮定する • y = Xb + Za +e • y:観察値, b:母数効果, a:育種価, e:残差 • X, Z: 計画行列 • yは多変量正規分布に従う • 期待値と分散を以下のように仮定する • E(y) = Xb • Var(y) = V = ZGZ’ + R = ZAZ’sa2 + Ise2
混合モデル方程式 または
Derivative-free (DF) REML • Smith と Graser(1987), Graser ら(1987)が提案した方法 • MeyerのDFREML,BoldmanらのMTDFREMLに実装され、爆発的に普及した • 尤度の計算を繰り返し、直接検索によって最大となる点を探す