Download
1 / 9
90 likes | 103 Views
Explore the roles of Data Management, Security, and System Management in orchestrating Big Data operations efficiently. Learn how Data Providers and Consumers interact with the system through service abstractions.

E N D
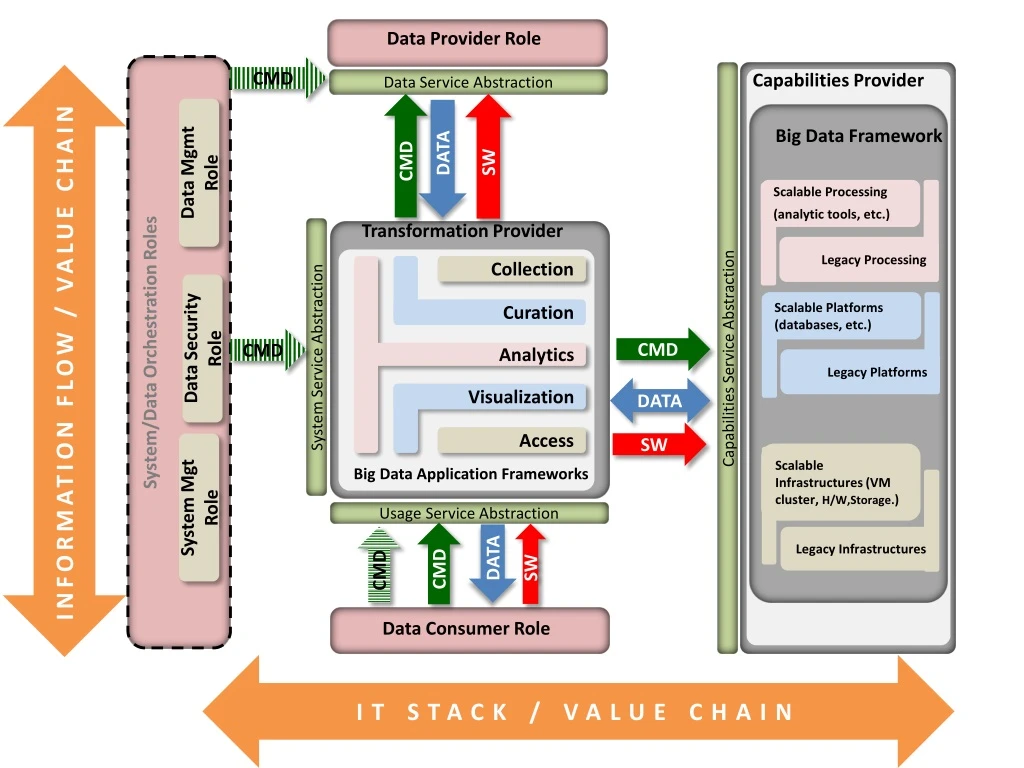
Data Provider Role CMD INFORMATION FLOW / VALUE CHAIN Data Service Abstraction DATA SW CMD Data Mgmt Role Capabilities Provider Big Data Framework Transformation Provider Collection Curation System/Data Orchestration Roles CMD CMD Data Security Role System Service Abstraction Capabilities Service Abstraction DATA Analytics Scalable Infrastructures (VM cluster, H/W,Storage.) Scalable Processing (analytic tools, etc.) Scalable Platforms (databases, etc.) SW Access Visualization Legacy Processing Legacy Platforms Big Data Application Frameworks System Mgt Role Usage Service Abstraction Legacy Infrastructures DATA CMD CMD SW Data Consumer Role IT STACK / VALUE CHAIN
Ref Architecture DescriptionFlows • Movement of Data: • Computer Generated Instructions: • E.g. Send me this data • Manual Instructions: • E.g. Set up an alert to send me data • Xfer and execution of Software: • E.g. SQL Query, JAR File with Map/Reduce DATA CMD CMD SW
Ref Architecture DescriptionSystem/Data Orchestration Roles • Collection of Roles performed by one or more actors which manages and orchestrates the operation of the Big Data System • Data Mgmt Role: This role is responsible for managing data flow into the system and management of the data with-in the system. • Works closely with the Data Security Role to control what data can leave the system and that when data is ingested it is properly secured. • Works closely with the System Mgt Role to insure that there are adequate resources to store and operate on the data and that data is archived/backed up as required. • Data Security Role: This role is responsible for managing the security of the data in the system. • Works closely with the Data Manager to identify and implement appropriate security controls on data to insure the no improper data enters the system and only allowed data is released to consumers (which may vary based on the consumer – Attribute/Role based access control) • Works closely with the System Mgt Role to make sure that security and data access controls are implemented across the system. • System Mgt Role: This role is responsible for managing the operations of, access to, and resources of the system (e.g. System Administrator) • Works with the Data Mgmt Role to allocate resources to data and associated applications. Implements data retention and backup policies identified by the Data Mgmt Role. • Works with the Data Security Role to implement system and data access controls. Insures that appropriate audit/security logs are maintained per the Data Security Role requirements. Manages access to system and data resources based on Data Security Role guidance.
Ref Architecture DescriptionData Provider and Data Service Abstraction • This role is frequently external to the system • They may be a system (legacy or big data) or someone with a tape. • They may have full or partial ownership of the data (e.g. they have limits on how they can share it). • They may be the direct producer of the data (a sensor) or someone to creates data from other data. • Data Service Abstraction • This is the interface to the provider for the data. It may be complex or simple • As an example the provider may be a data base with a SQL interface (absstraction) but the backend may be Oracle, MySQL, or Hadoop fronted by Hive. • The abstraction may also be that I am submitting a code for execution within a framework. • Not all commands to the abstraction may be automated (from a machine) but rather might involve a Data Mgmt role logging into the system and providing directions where new data should be transferred (say via FTP).
Ref Architecture DescriptionData Consumer • This role may be an end user or another system (big data or legacy) • Typically they are external or at most at the edge of the system • They gain access to the data via the Usage Service Abstraction Layer • Their access is controlled by the System/Data Orchestration Roles • Consumption may mean: • Downloading a raw data chunk • Downloading the results of an analytic • Viewing and interacting with a visualization
Concerns • Use colors explicitly, roles one color, capabilities another, etc. • I am not certain of the purpose use of the orange arrows (Info Flow/Val Chain, IT Stack/Val Chain). • On the Info flow that is really a top to bottom flow • Data moves from provider to consumer • In that move value is added • On the IT Stack – I am just not certain what it provides. • To me: there should be a single Data/Usage Service Abstraction term. • If you stack these diagram where the consumer is a system it is really interacting with the big data systems as a data provider. • I focused on providing words around the boxes which had the most discussion. Still need lots of words around the middle and right boxes.
1. Why is hardware, storage, and networking completely separate from the Big Data Framework? I am asking this because my experience is that they are intimately tied to and part of the overall Big Dataframework. For example, Using a large centralized SAN with say an Hadoop implementation is generally consideredvery poor practice. If I am implementing any sort of Grid or Cluster environment the networking between the nodesand racks is critical to the performance of the cluster. My recommendation which I believe will make the diagram more internally consistent is to extend the Big Data Frameworkbox to include the Scalable Infrastructure and delete the grey Hardware box. If nothing else it is one less box to explain. But if I am describing a Big Data framework I almost always have to discuss Hardware components. Capabilities Provider Big Data Framework Processing (analytic tools, etc.) Platforms (databases, etc.) Capabilities Service Abstraction Infrastructures (VM cluster, H/W,Storage.)
2. In looking at the transformation Provider all the "Application" functionality is embedded in there. In Big Data Frameworkthere is Scalable and Legacy Applications. But it mentions Analytic Tools. Tools themselves do not implement application functionality but rather enable it. As a component of a Capabilities Provider the indication that general capabilities are provided versus applications. Applications are also not Frameworks. An analytic tool like R or Distributed R is a capability whichwould allow transformation, visualization, analytics to be run on some data stored in a platform (HDFS, RDBMS, HBASE, etc.).My question is what is the purpose or meaning of the term application and how is it different from the application functions provided in the transformation provider? My recommendation is to replace the word "Applications" in that box with "Processing". That brings that box more inline withthe idea of a framework. To illustrate by example:Scalable Processing: Map/Reduce, R, Giraph, Storm, Messaging (MPI, Active Mqueue)Legacy Processing: Service Bus, SOA platforms (JBOSS, Tomcat, etc.), Web ServersScalable Platforms: HDFS, Accumulo, HBASE, Solr, Mongo.Legacy Platforms: MySQL, Oracle, Berkley DBAlso, I should point out that in some discussions there have been objections to the word "Scalable" being used here.Lots of things in the legacy realm are scalable. Oracle and MySQL will certainly scale not just vertically but also havefairly well known horizontal scaling strategies.My personnel thought is that we simplify the diagram and just talk about Processing, Platforms, and Infrastructure.BTW - By going to those terms in my mind we would align better with the Cloud Computing Ref Architecture with:Infrastructrue ~ IaaSPlatform ~ PaaSProcessing ~ SaaS Capabilities Provider Big Data Framework Processing (analytic tools, etc.) Platforms (databases, etc.) Capabilities Service Abstraction Infrastructures (VM cluster, H/W,Storage.)
2. In looking at the transformation Provider all the "Application" functionality is embedded in there. In Big Data Frameworkthere is Scalable and Legacy Applications. But it mentions Analytic Tools. Tools themselves do not implement application functionality but rather enable it. As a component of a Capabilities Provider the indication that general capabilities are provided versus applications. Applications are also not Frameworks. An analytic tool like R or Distributed R is a capability whichwould allow transformation, visualization, analytics to be run on some data stored in a platform (HDFS, RDBMS, HBASE, etc.).My question is what is the purpose or meaning of the term application and how is it different from the application functions provided in the transformation provider? My recommendation is to replace the word "Applications" in that box with "Processing". That brings that box more inline withthe idea of a framework. To illustrate by example:Scalable Processing: Map/Reduce, R, Giraph, Storm, Messaging (MPI, Active Mqueue)Legacy Processing: Service Bus, SOA platforms (JBOSS, Tomcat, etc.), Web ServersScalable Platforms: HDFS, Accumulo, HBASE, Solr, Mongo.Legacy Platforms: MySQL, Oracle, Berkley DBAlso, I should point out that in some discussions there have been objections to the word "Scalable" being used here.Lots of things in the legacy realm are scalable. Oracle and MySQL will certainly scale not just vertically but also havefairly well known horizontal scaling strategies.My personnel thought is that we simplify the diagram and just talk about Processing, Platforms, and Infrastructure.BTW - By going to those terms in my mind we would align better with the Cloud Computing Ref Architecture with:Infrastructrue ~ IaaSPlatform ~ PaaSProcessing ~ SaaS


















