Download
1 / 12
120 likes | 139 Views
Explore the evolution and future challenges of workflow management software, focusing on PanDA - a powerful production and distributed analysis system. Learn about its applications beyond high-energy physics, integration with diverse computing resources, and the development of the Harvester project.

E N D
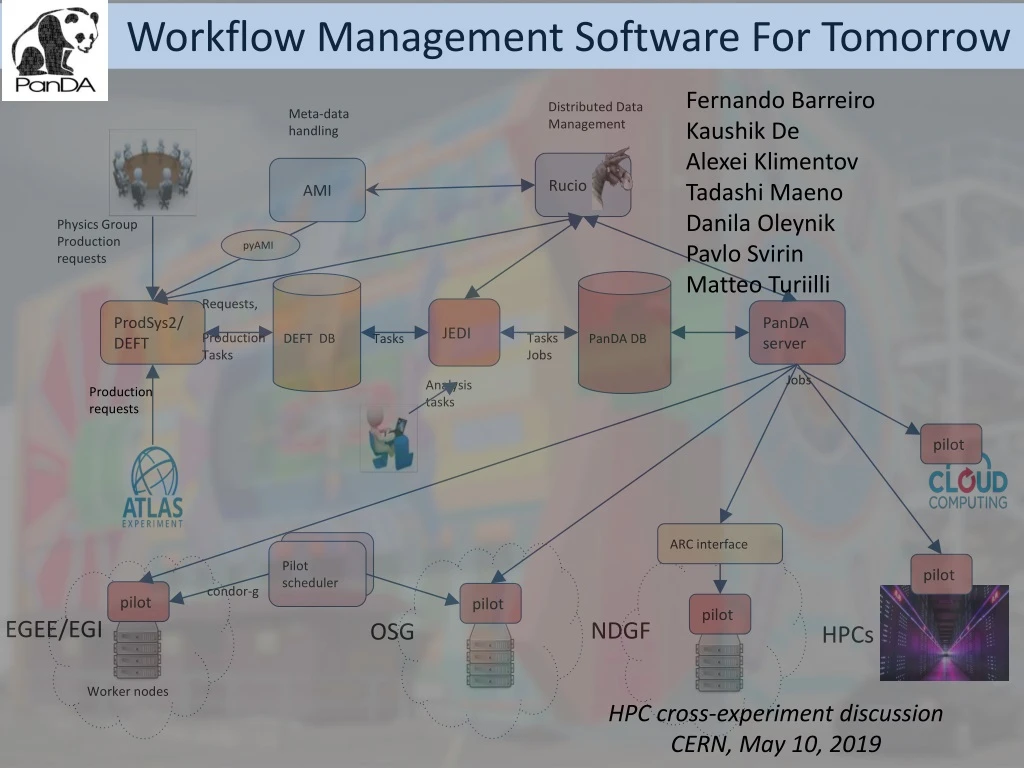
Workflow Management Software For Tomorrow Fernando Barreiro Kaushik De Alexei Klimentov Tadashi Maeno Danila Oleynik PavloSvirin Matteo Turiilli Distributed Data Management Meta-data handling Rucio AMI Physics Group Production requests pyAMI PanDA DB DEFT DB Requests, Production Tasks JEDI ProdSys2/ DEFT PanDA server Tasks Jobs Tasks Jobs Analysis tasks Production requests pilot ARC interface Pilot scheduler pilot condor-g pilot pilot pilot EGEE/EGI NDGF OSG HPCs Worker nodes HPC cross-experiment discussion CERN, May 10, 2019
Outline • WFM SW evolution (HEP) • WFM SW on HPC from non-LHC
Workflow Management. PanDA. Production and Distributed Analysis System • PanDA Brief Story • 2005: Initiated for US ATLAS (BNL and UTA) • 2006: Support for analysis • 2008: Adopted ATLAS-wide • 2009: First use beyond ATLAS • 2011: Dynamic data caching based on usage and demand • 2012: ASCR/HEP BigPanDAproject • 2014: Network-aware brokerage • 2014 : Job Execution and Definition I/F (JEDI) adds complex task management and fine grained dynamic job management • 2014: JEDI- based Event Service • 2015: New ATLAS Production System, based on PanDA/JEDI • 2015 :Manage Heterogeneous Computing Resources : HPCs and clouds • 2016: DOE ASCR BigPanDA@Titan project • 2016:PanDA for bioinformatics • 2017:COMPASS adopted PanDA, NICA (JINR) • PanDA beyond HEP : BlueBrain, IceCube, LQCD https://twiki.cern.ch/twiki/bin/view/PanDA/PanDA Global ATLAS operations Up to ~800k concurrent job slots 25-30M jobs/month at >250 sites ~1400 ATLAS users First exascale workload manager in HENP 1.3+ Exabytes processed every year in 2014 - 2018 Exascale scientific data processing today BigPanDA Monitor http://bigpanda.cern.ch/ Concurrent cores run by PanDA Big HPCs Grid Clouds
Future Challenges for WorkFlow(Load) Management Software • New physics workflows and technologies • machine learning training, parallelization, vectorization… • also new ways how Monte-Carlo campaigns are organized • Address computing model evolution and new strategies • “provisioning for peak” • Incorporating new architectures (like TPU, GPU, RISC, FPGA, ARM…) • Leveraging new technologies (containerization, no-SQL analysis models, high data reduction frameworks, tracking…) • Integration with networks (via DDM, via IS and directly) • Data popularity -> event popularity • Address future complexities in workflow handling • Machine learning and Task Time To Complete prediction • Monitoring, analytics, accounting and visualization • Granularity and data streaming
Future development. Harvester Highlights Primary objectives : To have a common machinery for diverse computing resources To provide a common layer in bringing coherence to different HPC implementations To optimize workflow executions for diverse site capabilities T.Maeno • To address wide spectrum of computing resources/facilities available to ATLAS and experiments in general • New model : PanDA server- harvester-pilot • The project was launched in Dec 2016 (PI T.Maeno)
Harvester Status • What is Harvester • A bridge service between workload, data management systems and resources to allow (quasi-) real time communication between them • Flexible deployment model to work with various operational restrictions, constraints, and policies in those resources • E.g. local deployment on edge node for HPCs behind multi-factor authentication, central deployment + SSH + RPC for HPCs without outbound network connections, stage-in/out plugins for various data transfer services/tools, messaging via share file system, … • Experiments can use harvester by implementing their own plug-ins, harvester is not tightly coupled with PanDA • Current Status • Architecture design, coding and implementation completed • Commissioning ~done • Deployed on wide range of resources • Theta/ALCF, Cori/NERSC, Titan/OLCF in production • Summit/OLCF, MareNostrum4/BSC under testing • Also at Google Cloud, Grid (~all ATLAS sites), HLT@CERN
OLCF CERN BNL PanDA/Harvester deployment for ATLAS @OLCF
Harvester for tomorrow (HPC only) • Full-chain technical validation with Yoda • Yoda : ATLAS Event Service with MPI functionality running on HPC • Yoda+Jumbo jobs in production • Jumbo jobs : relax input file boundaries, pick up any event from dataset • Two hops data stage-out with Globus Online + Rucio • Containers integration • Implementation of a capability to use simultaneously CPU/GPU within one node for MC and ML payloads • Implementation of a capability to dynamically shape payloads based on real-time resource information • Centralization of Harvester instances using CE, SSH, MOM, …
Simulation Science “Summit”: ~1017 FLOPS HEP SIMULATION NEUROSCIENCE “ENIAC”: ~103 FLOPS • Computing has seen an unparalleled exponential development • In the last decades supercomputer performance grew 1000x every ~10 years • Almost all scientific disciplines have long embraced this capability Original slide from F.Schurmann (EPFL)
Pegasus WFMS/PanDA • Collaboration started in October 2018 • December 2018: first working prototype, standard Pegasus example (Split document/word count) • tested on Titan • Future plans/possible applications/open questions: • test the same workflow in a heterogeneous environment: Grid + HPC (Summit/NERSC/…) with data transfer via RUCIO or other tools • Possible application: data transfer for LQCD jobs from/to OLCF storages • Currently Pegasus/PanDA integration works on job level. How can we integrate Pegasus with other PanDA components like JEDI is still TBD
Next Generation Executor Project (Rutgers U) • Schedules and runs multiple tasks concurrently and consecutively in one or more batch jobs: • Tasks are individual programs • Tasks are executed within the walltime of each batch job • Late binding: • Tasks are scheduled and then placed within a batch job at runtime • Tasks and resource heterogeneity: • Scheduling, placing and running CPU/GPU/OpenMM/MPI tasks in the same batch job • Use single/multiple CPU/GPU for the same task and across multiple tasks • Supports multiple HPC machines. • Requires limited development to support a new HPC machine. • Use cases: Molecular dynamics and HEP payloads on Summit
Status and near-term plans : • Test runs with bulk task submission with harvester and NGE • Address bulk and performant submission (currently ~320 units in 4000 sec) • Run at scale on Summit once issues with jsrun are addressed by IBM • Conduct submission with relevant workloads from MD and HEP


















