Download

1 / 89
890 likes | 1.05k Views
Workbook 10 Network Applications. Pace Center for Business and Technology. Chapter 1. An Introduction to TCP/IP Networking. Key Concepts Most Linux networking services are designed around a client-server relationship.

E N D
Workbook 10Network Applications Pace Center for Business and Technology
Chapter 1. An Introduction to TCP/IP Networking Key Concepts • Most Linux networking services are designed around a client-server relationship. • Network server applications are generally designed to be "always running", starting automatically as a system boots, and only shutting down when the system does. Generally, only the root user may manage server processes. • Network client applications are generally running only when in use, and may be started by any user. • Most Linux network servers and clients communicate using the TCP/IP protocol. • The TCP/IP address of both the client process and the server process consists of an IP address and a port. • Network servers usually use assigned, "well known" ports, as cataloged in the /etc/services file. Network clients generally use randomly assigned ports. Often, well know ports reside in the range of privileged ports, below port number 1024. • The hostname command can be to examine a machine's current IP address, while the netstat -tuna command can be used to examine all open ports.
Clients, Servers, and the TCP/IP Protocol Most networking applications today are designed around a client-server relationship. The networking client is usually an application acting on behalf of a person trying to accomplish a particular task, such as a web browser accessing a URL, or the rdate command asking a time server for the current time. The networking server is generally an application that is providing some service, such as supplying the content of web pages, or supplying the current time. The design of (applications acting as) network clients and (applications acting as) network servers differs dramatically. In order to appreciate the differences, we will compare them to the agents in a more familiar client-server relationship, a customer buying a candybar from a salesperson.
The Server Servers are Highly Available Just as a salesperson must always be running the register, even when customers are not around, processes implementing networking services need to be running, ready to supply services upon request. Usually, processes implementing network services are started at boottime, and continue to run until the machine is shutdown. In Linux (and Unix), such processes are often referred to as daemons. Generally, only the root user may start or shutdown processes acting as network servers. Servers have Well Known Locations In addition to being available when a customer wants service, salespeople stay where they know customers can find them. Just as customers can look up the locations of unfamiliar candybar salesmen in telephone books and find them by street address, networking clients can look up the locations of unfamiliar network servers using a hostname, which is converted into the IP Address used to access the service.
The Server The Client In contrast, the candybar customer needs to be neither highly available nor well known. A customer doesn't hang around a store from dawn until dusk just in case he decides he wants a candybar. Likewise, clients generally do not need to to stay at well known locations. Our customer doesn't stay at home all day, just in case somebody wants to come by to sell him a candybar. Processes that implement network clients are started by normal users, and generally are only running as long a necessary to complete a task. When someone breaks for lunch, he closes his web browser. Also, client applications do not need to have fixed addresses, but can move from place to place. More on this next.
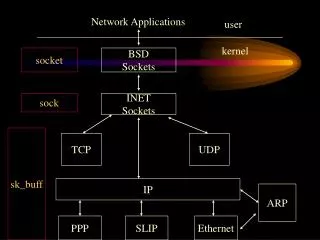
The Server TCP/IP Addresses Every process which is participating in a TCP/IP conversation must have an IP Address, just as every participant in a phone conversation must have a phone number. Additionally, every process in a TCP/IP conversation must have port number, whose closest analogy might be a telephone extension associated with a phone number. Computers on a network are identified by IP address. The IP address comes in the form of four integers, each ranging from 0 to 255 (not coincidentally, the amount of information that can be encoded in one byte of memory), and traditionally written separated by periods, such as 192.168.0.3. This representation is often informally referred to as a dotted quad. Processes on computers are identified by a port number, which is an integer ranging from 1 to 65535 (not coincidentally, the amount of information that can be encoded in two bytes of memory). Whenever a process wants to participate in a TCP/IP conversation with another process, it must first be assigned a port number by the kernel. The TCP/IP protocol allows two processes, each identified by a combination of an IP address and port number, to locate one another. The IP address is used to locate the machine that the process is running on (this is the "IP" part of the protocol), and the port number is used to locate the correct process on the machine (this is the "TCP" part).
Sockets In order to illustrate a typical TCP/IP transaction, we will examine the conversation between a fictitious student's mozilla web browser, running on the machine station3.example.com, which translates into an IP address of 123.45.67.89, and the httpd web server running at academy.redhat.com, which translates into an IP address of 66.187.232.51. The process usually resembles the following. As the machine academy.redhat.com is booted, the httpd process is started. It first allocates a socket, binds it to the port 80, and begins listening for connections. At some point later, perhaps measured in minutes, perhaps days, the mozilla process is started on the machine station3.example.com. It also allocates a socket, and requests to connect to port 80 of the machine 66.187.232.51. Because it did not request a particular port number, the kernel provides a random one, say 12345. As it requests the connection, it provides its own IP address and (randomly assigned) port number to the server. The server chooses to accept the connection. The established socket is now identified by the combined IP address and port number of both the client and server.
Sockets Once the socket is established, the mozilla process and the httpd process can read information from and write information to one another as easily as reading and writing from a file. (Remember... "everything is a file", even network connections! For most practical purposes, a socket is just another file descriptor.) The highlighted verbs in this section, bind, listen, connect, accept, and even read and write, are well defined terms in Linux (and Unix). They also are the names of the programming system calls that implement each step.
Sockets In the TCP/IP protocol, a socket is defined by the combined IP address and port number of both the server and the client. For example, what if our student was running multiple versions of Mozilla, each making requests of academy.redhat.com, or what if multiple users were using the machine station3.example.com simultaneously, all accessing academy.redhat.com? How would the web server keep straight which conversation it was having with which client? Each client process would be assigned a distinct port number, and therefore converse with the httpd daemon using a distinct socket.
More about Ports Well Known Services and the /etc/services File In our example, we mentioned that the httpd process requested to bind to port 80, and in turn the mozilla process requested to connect to port 80 of the server. How did each agree that port 80 was the appropriate port for the web server? Traditional Internet services, such as a web server, or ftp server, or SMTP (email) server, are referred to as well known services. On Linux (and Unix) machines, a catalog of well known services, and the ports assigned to them, is maintained in the file /etc/services. Notice that both the client and server need to agree on the appropriate port number, so the /etc/services file is just as important on the client's machine as on the server's. Just because a service is listed in the /etc/services file does not mean that you are implementing (or even capable of implementing) that well known service.
Privileged Ports Unlike clients, processes implementing network servers generally request which port they would like to bind to. Only one process may bind to a port at any given time (Why must this be?). Otherwise, how would a client distinguish which process it would like to connect to? Ports less than 1024 are referred to as privileged ports, and treated specially by the kernel. Only processes running as the root user may bind to privileged ports. (This helps ensure that, if elvis had an account on the machine academy.redhat.com, he couldn't start up a rogue version of a web server which might hand out false information.) Originally, the well known ports and the privileged ports were meant to coincide, but in practice there are more well known ports than privileged ones.
Determining Current TCP/IP Networking Services Using hostname to Display the Current IP Address The hostname command, without arguments, displays a machine's current hostname. With the -i command line switch, machine's IP address is displayed instead. What if there are multiple IP addresses? The design of the hostname command is a little misguided, because machines can easily have more than one IP address (one for each of multiple network interface cards, for instance.) In such situations, there is no reason why any one IP address should be privileged over the others. For historical reasons, however, the kernel keeps track of a parameter it refers to as its hostname, and the hostname -i command displays the IP address associated with it.
Using the netstat Command to Display Open Ports When a port is used by a socket, it is referred to as an open port. The netstat command can be used to display a variety of networking information, including open ports. Unfortunately, when called with no command line switches, the netstat command's output is overwhelmed by the least interesting information, local "Unix" sockets that are used to communicate between processes on the same machine. When called with the following command line switches, however, more interesting information is displayed.
Using the netstat Command to Display Open Ports Many more switches are available, as a quick look at the netstat(8) man page will reveal. The above switches were chosen from the many, not only because when combined, they produce interesting output, but also because they are easy to remember: just think "tuna". When invoked with the above switches, netstat's output is akin to the following.
Using the netstat Command to Display Open Ports Of the many lines, we may weed away those associated with the udp protocol, and focus instead on columns 4, 5, and 6 of the rows associated with tcp.
Understanding IPv6 Addresses The IP protocol which we discussed above, with friendly IP addresses such as "66.187.232.51", is known as Internet Protocol version 4, or "IPv4", and is by far the dominant IP protocol in use today. With the IPv4 protocol, you can have around 4 billion distinct IP addresses. When the IPv4 protocol was developed in the early 1970's, this was plenty of addresses, and the IPv4 protocol has served us well. By learning a few tricks such as masquerading, where many machines can "hide behind" a single public IP address, we still manage to live with it well. As appliances become more intelligent, however, and networking (particularly wireless networking) becomes cheaper, we are approaching a day where every toaster is going to want its own IP address, and 4 billion address wont' be enough. Changes are on the horizon. These changes are coming in the form of Internet Protocol Version 6, or "IPv6". Among many other changes, the IPv6 protocol takes the obvious step, and makes IP addresses bigger. Four times bigger. An IPv6 address, in full form, looks like fe80:0000:0000:0000:0211:22ff:fe33:4411. Instead of writing addresses as familiar decimal numbers (like "127"), they are written in hexadecimal numbers (like "fe33").
Understanding IPv6 Addresses Some merciful conventions in representing IPv6 addresses help. Once within an address, a series of zero segments, such as 0000:0000:0000, can be replaced with a double colon (::). For any segment which begins with leading zeros, such as 0211, the leading zeros can be dropped. With these two shortcuts in mind, the above address could be written a little more friendly as fe80::211:22ff:fe33:4411.
Understanding IPv6 Addresses Red Hat Enterprise Linux is getting ready for a future transition to IPv6, and many applications can already handle either IPv4 or IPv6 connections. For our purposes, because it is not yet widely adopted, we're going to ignore IPv6 as much as possible. Fortunately, there's just a few forms of IPv6 addresses we need to be able to recognize, summarized in the table below. Whenever these forms of IPv6 address are encountered ( ::ffff:192.168.0.1, ::1, and ::), you can simply think of them as their IPv4 equivalents ( 192.168.0.1, 127.0.0.1, and 0.0.0.0, respectively).
Understanding IPv6 Addresses Listening Sockets Listening are sockets are sockets owned by a server, before any clients have come along. For example, at the end of step one of our sample TCP/IP connection above, the httpd process would have a socket open in the listening state. Notice in the above output that for listening sockets, only the local half of the address is defined. Established Sockets As the name implies, established sockets have both a client process and a server process with established communication. Pulling it All Together
Understanding IPv6 Addresses These two sockets are listening for connections, but only on the loopback address. They must belong to services expecting to receive connections from other processes on the local machine, but not from other machines. To determine what services these ports belong to, we do some greping from the /etc/services file. Apparently, whatever process has claimed port 25 is listening for email clients. This is probably the sendmail daemon. The process listening on port 631 is listening for print clients. This is probably the cupsd printing daemon. Both of these services are discussed in more detail in this Workbook.
Understanding IPv6 Addresses These lines reflect both halves of an established connection between two processes, both on the local machine (notice the loopback IP address for both of them). The first is bound to port 59330 (probably a randomly assigned client port), and the second to the port 631. Some process on the local machine must be communicating with the cupsd daemon. Our final extracted lines represent established connections between clients on remote machines, and services on our local machine's external interface (192.168.122.156). The first is a connection to an IPv6 aware service on port 22. Again, we try a little grepping to look up the well known service associated with port 22. Apparently, this line represents an active connection between a ssh client on a remote machine with IP address 192.168.122.1, and a sshd daemon on our local machine. The latter is a connection to an IPv4 only service bound to port 653, probably an NFS related service.
Online Exercises Chapter 1. An Introduction to TCP/IP Networking Online Exercises Lab Exercise Objective: Gain familiarity with TCP/IP configuration and activity. Estimated Time: 10 mins. Specification • Create the file ~/lab11.1/ipaddr, which contains your machine's IP address, as reported by the hostname command, as its single word. • Create the file ~/lab11.1/listening_ports, which contains a list of all ports less then 1024 on your current machine which are open in the listening state, one port per line. Deliverables • The file ~/lab11.1/ipaddr, which contains your machine's current IP address (as reported by the hostname command) as its single word. • The file ~/lab11.1/listening_ports, which contains a list of all ports less then 1024 on your current machine which are open in the listening state, one port per line.
Using Email The Simple Solution The simplest solution is appropriate for people using computers which have permanent, well known Internet connections. At the time that many of the protocols defining how email delivery should be handled were developed, this was more of the standard instead of the exception. The solution involves two separate applications whose roles are identified by TLA's (Three Letter Acronyms). The first application is referred to as the MTA, or Mail Transport Agent; the second is known as the MUA, or Mail User Agent.
The MTA (Mail Transport Agent) The MTA generally operates in the background, performing the work of the local post office. The MTA receives email to be delivered from programs on the local machine, determines from the recipient's address the appropriate machine to contact, and attempts to connect to a complementary MTA running on the recipients machine, who should be listening to port 25. If the sender's MTA cannot contact the receiver's MTA, the mail is spooled on the sender's machine, and the sender's MTA tries again at a later time. The MTA also binds to the local port 25, where it receives connections from other MTA's. When it receives mail from a remote MTA which is destined for a user on the local machine, it receives the mail, and stores it in a mail spool which is referred to the user's inbox. In Linux (and Unix), the default inbox for a user is /var/spool/mail/username, so that mail awaiting the user elvis would be stored in the file /var/spool/mail/elvis. The default MTA in Red Hat Enterprise Linux is a daemon called sendmail.
The MUA (Mail User Agent) The MUA is the application most user's think about when they think about email. The MUA retrieves delivered mail from a user's mail spool (inbox), and presents it to the user as "New Mail". The MUA allows users to compose responses or new mail messages, and passes these messages to the local MTA for delivery. Red Hat Enterprise Linux ships with a wide selection of MUAs, several of which will be introduced in this and the next lesson.
Mailbox Servers While simple, the previous solution requires that, first of all, users are receiving email on a machine that maintains a persistent Internet connection, and secondly, the machine has a well known host name and is accessible to others. Many users, such as people using a "dial up" or "High Speed" connection from an ISP (Internet Service Provider), or people using machines behind an institution's firewall, are not in this situation. Another solution has evolved to serve people in these situations: Mailbox servers.
Mailbox Servers In the diagram above, we assume that elvis is using a "high speed" Internet connection which he has subscribed to from the company "ISP.Net". When he connects to the Internet, his ISP issues his machine an IP address, but elvis cannot predict ahead of time which IP address he will receive. The hostname which the ISP has assigned to the IP address is probably unattractive, such as dhcp-191-93.isx.isp.net, so even if elvis were guaranteed to receive the same IP address each time, he would not want to advertise his machine's hostname as his email address. Instead, elvis takes advantage of an "email account" which his ISP offers him. Very likely, this account exists on a Linux or Unix machine owned by the ISP, which has a permanent connection to the Internet, and is assigned a hostname such as pop.isp.net. The ISP has arranged all mail destined to addresses of the form user@isp.net to be delivered to the MTA running on this machine. When the MTA running on pop.isp.net receives mail for elvis, it stores the delivered mail into a mail spool dedicated to elvis (very likely in the file /var/spool/mail/elvis), and the email is considered delivered. Because the ISP's machine pop.isp.net has a permanent, well known connection to the Internet, it is a much better candidate for receiving email than elvis's machine at home. Sitting at home, however, elvis still needs access to the email sitting in his "inbox" on pop.isp.net. Usually, this access is provided in the from of a POP (Post Office Protocol) or IMAP (Internet Mail Access Protocol) server.
Mail Servers POP servers POP servers perform a very simple service. They allow users to access the user's single mail spool, and transfer its contents to their local MUA. POP servers generally bind to port 110, and require that any POP client authenticate itself using a username/password pair. Most modern MUA's act as POP clients, and can be configured to retrieve mail from a specified POP server. If a mailbox server is implementing the POP service, it usually implies that the mailbox server is not intending to provide permanent storage for a user's email, but instead just cache it temporarily until the user can "pop" it down to a local machine. IMAP servers IMAP servers generally provide clients with more sophisticated mailbox management. IMAP users may maintain several folders on the mailbox server, not just their individual inbox. In general, an IMAP server implies that a user's email is intended to be permanently stored on the mailbox server, and users will occasionally connect with a MUA from a remote machine to "browse" their mail. Generally, IMAP servers are found in institutional and corporate environments. IMAP daemons bind to port 143.
Mail Servers Sending Mail Because elvis's machine maintains an almost continuous connection to the Internet, he is willing to still use his local MUA to deliver mail. If his local MUA is temporarily unable to connect to the recipient's machine, the MUA will spool the mail locally and try again later. Red Hat Enterprise Linux Default Configuration By default, Red Hat Enterprise Linux is configured appropriately for this scenario. The local MTA is started, but it will not accept connections over port 25 (except for from the loopback address, 127.0.0.1). It serves merely to deliver outgoing email. Users are assumed to be accessing their email from a POP or IMAP server. The default configuration can be changed, but the necessary configuration is beyond the scope of this course.
Outgoing Mail Servers For machines that have only transient connections to the Internet, attempting to deliver email using the local MTA may not be appropriate. Instead, users of "dial up" connections and the like often use what is referred to as an SMTP (Simple Mail Transfer Protocol) Server, or outgoing mail server. Many ISPs and institutions provide outgoing SMTP servers, often with names like smtp.isp.net. The MTA on the SMTP server is willing to accept mail from "local" machines, even though it is not the final recipient for the email. Instead, the SMTP server relays the mail, forwarding it on to its destination. If any temporary problems occur, the spooling and redelivery attempts of the pending mail is now the responsibility of the SMTP server. Many MUA's allow users the option of specifying a remote host to act as the user's SMTP server (as opposed to forwarding mail to the local MTA for delivery). [1]
Local Delivery All of the above scenarios assume that a user is sending email from his machine to a recipient on a remote machine. Linux (and Unix) also allows users on a local machine to deliver email to one another, where email is addressed simply to a username, such as blondie. For local delivery, no POP servers or SMTP servers are required, as the email is instantly delivered by the local MTA.
Local Delivery Sending Email with mail The mail command can be used to deliver mail to recipients who are specified as arguments on the command line. The body of the message is read from standard in (which may be read from a pipe, a redirected file, or from the keyboard directly, where CTRL+D ("EOF") is used to indicate the end of the message). The command line switches in the following table can be used to specify a subject line, recipients to "Cc:", etc. As an example, in the following, elvis mails to blondie the contents of the file lyrics.txt.
Using mail to Read Mail The mail command can also be used to read mail from a user's local mail spool. The interface is primitive, however, and usually other MUA's are used instead. Details can be found in the mail man page. These days, the most common use of the mail command is as a quick and easy way to send mail. In the following example, blondie is using the mail command, without arguments, to view the mail in her inbox, and then delete the message and quit.
Chapter 6. Network Diagnostic Applications Key Concepts • /sbin/ifconfig displays local IP configuration. • ping confirms low level network connectivity between hosts. • host makes direct DNS queries. • The netstat -tuna command lists currently active network services and connections. • /sbin/traceroute can diagnose routing problems.
Required Configuration for the Internet Protocol IP Address Linux (and Unix) represents every networking device attached to a machine (such as an Ethernet card, a Token Ring card, a modem used for dialup connections, etc...) as a network interface. Before an interface can be used to send or receive traffic, it must be configured with an IP address which serves as the interface's identity. Default Gateway The mechanics of the IP protocol organizes machines into sub networks, or subnets. All machines on a given subnet may exchange information directly. IP subnets are in turn linked to other subnets by machines acting as routers. A router has multiple network interfaces, usually each participating in a distinct subnet. In order to communicate with a host on another subnet, the data must be passed to a router, which (with the help of other routers) routes the information to the appropriate subnet, and from there to the appropriate host. In order to communicate with machines outside of your local subnet, your machine must know the identity of a nearby router. The router used to route packets outside of your local subnet is commonly referred to as a default gateway.
Required Configuration for the Internet Protocol Nameserver Other machines on the Internet are in turn identified by their IP address. People tend to prefer to think in terms of names instead of numbers, however, so a protocol has been developed to assign names to IP addresses. The protocol is called Domain Name Service, or more commonly DNS. The DNS protocol requires that every machine have available one or more DNS servers (commonly called nameservers), which can serve as both a database for assigning name to local IP addresses, and also a starting point for determining IP addresses for domain names for which the server does not have direct knowledge.
Determining Your IP Address(es): /sbin/ifconfig A previous Lesson introduced the hostname -i command, which displays the IP address of your local machine. In reality, a "machine" does not have an IP address, a machine's network interfaces do. This Lesson discusses the topic of IP addresses and network interfaces in more detail. In Linux (and Unix), every network device is represented as a network interface. (For once, we encounter something that is not a file!) Linux names interfaces according to the type of device it represents. The following table lists some of the more commonly encountered interface names used in Linux. In each case, n is replaced with a distinct integer for each instance of a given device attached to a machine.
Confirming Network Interface Configuration The ifconfig command displays the configuration of all active network interfaces. Because the command is generally used by root to configure interfaces, it lives within the /sbin directory, which is outside of the default PATH for standard users. Standard users can use the command to view interface configuration information, however, by using an absolute reference, as in the following example.
Confirming Network Interface Configuration The ifconfig command displays a stanza of IP configuration information and usage statistics for each active network interface. In most situations, users should expect to see two stanzas reported. One stanza contains the configuration for an attached Ethernet card, while the other shows the configuration for the virtual loopback device. The important line is the second line, which displays the IP address assigned to the interface. If the line containing the IP address is missing, or if the IP address does not look reasonable for your local network configuration, you can expect to have trouble accessing the network.
Determining Your Default Gateway: /sbin/route As mentioned in this Lesson's introduction, communicating with hosts on your local subnet uses different procedures than communicating with hosts on a separate subnet. The Linux kernel, like all Unix kernels, maintains an internal table which defines which machines should be considered local, and what gateway should be used to help communicate with those machines which are not. This table is called the routing table. If you are a standard user, the route command can be used to display the system's routing table. If you are the root user, the command can be used to manipulate the table as well. Like the ifconfig command, the route command lives in the /sbin directory, so standard users should invoke it using an absolute reference.
Determining Your Default Gateway: /sbin/route A standard routing table displays two types entries. The first type defines which subnets should be considered local subnets. In general, there should be one line specifying a subnet for each active interface. In the output above, the first line defines the subnet associated with the Ethernet interface (with an IP address of 192.168.0.51), and the second line defines the subnet associated with the loopback interface (with an IP address of 127.0.0.1). The second type of entry, which is used to define gateways, is more relevant to our discussion. Gateway entries can be distinguished because a host is defined in the second column ("Gateway"), and the fourth column ("Flags") contains a "G". Every routing table should contain an entry for a "default" gateway, an the second column should contain the gateway's hostname.
Determining Your Default Gateway: /sbin/route The same information can be displayed using IP addresses instead of hostnames using /sbin/route -n.
Determining Your Nameserver(s) Domain Name Service allows users to refer to networked computers using hostnames instead of IP addresses. Unlike the other two aspects of network configuration, a nameserver is to some extent optional. In order to communicate with other machines at all, your host must have an IP address. In order to communicate with machines outside of your subnet, you must have a default gateway. If users are willing to refer to every machine by IP address instead of hostname, however, your machine can communicate using the IP protocol without ever consulting a nameserver. In practice, however, nameservers seem more of a necessity. (Do you have an easier time remembering academy.redhat.com, or 66.187.232.51?) Converting a hostname into an IP address is often referred to as resolving an address, and the library which implements nameservice is called the resolv library. When the library attempts to resolves an address, there are generally two resources available.
Static DNS Configuration: /etc/hosts The first resource is a simple text file called the /etc/hosts file. While only root can edit the file, any user can observe it. The format of the file is as simple as it looks. The first token on a line should be an IP address, and subsequent tokens are hostnames which should resolve to the IP address. The standard Unix comment character (“#”) is also supported. If a machine is only communicating with a few machines, or if an administrator wants to create shortcut hostnames (such as “s”), or if she would like to override the local nameserver, entries can be added to the /etc/hosts file using a simple text editor. Obviously, this technique does not scale well. You cannot expect the local /etc/hosts file to provide every answer.
Dynamic DNS Configuration: /etc/resolv.conf When the local /etc/hosts cannot provide the answer, the resolv library consults a nameserver. In order to determine which machine running a nameserver to consult, it examines the resolv library's configuration file, /etc/resolv.conf. The /etc/resolv.conf configuration file uses lines which begin with the keyword nameserver to specify the IP addresses of machines that are running nameservers. If multiple nameservers are specified, the first one will be used by default. If it is unavailable, the second will be used, and so on. Accordingly, the first listed nameserver is sometimes called the primary nameserver, the second listed server the secondary nameserver, and so on. Notice that a nameserver does not need to be a nearby machine. Any machine which is implementing nameservice and allows you to query it can be used as a nameserver. In practice, using a local nameserver leads to better performance.
Network Diagnostic Utilities Diagnostic utilities that can be used to ensure that the configurations are working appropriately with your local network environment. Confirming IP Connectivity: ping The ping command can be used to confirm IP connectivity between two hosts. The first argument to ping can be either the hostname or the IP address of the machine you would like to contact. The ping command will continue to run until canceled with the CTRL+C control sequence. If no response is returned from the ping command, you cannot expect any higher level networking communication to occur. One common culprit is an Ethernet cable which has become physically disconnected from the machine or from the wall. Inconsistencies in the rate at which lines are displayed or discontinuities in the sequence numbers are generally indicative of a congested network, or a noisy connection, and you can generally expect poor network performance of higher level protocols.
Examining Routing: /usr/sbin/traceroute When connecting to a machine outside of your subnet, your packet is passed from router to router as it traverses various subnets, until finally the packet is delivered to the subnet which contains the destination machine. The path of the packet, as it is passed from router to router, can be traced with the /usr/sbin/traceroute command. The traceroute command is generally called with a single argument, the hostname or IP address of the destination machine.
Examining Routing: /usr/sbin/traceroute Often, you will find that packets take surprising paths to get from one place to another. The number of routers that your packet passes through is generally referred to as the number of hops the packet has made. The packet above took 17 hops to reach its destination. If your packet cannot complete the first hop, your machine's default gateway has probably not been correctly defined. If your traceroute terminates within the first couple of hops (without reaching the final destination), the problem is a misconfigured local router, and your local network administrator can probably help solve the problem. If the traceroute peters out more than four or five hops away, the problem is probably outside of your local network administrator's control.
Performing DNS Queries Manually: host The host command can be used to perform DNS queries directly. With a single argument, the host command will simply report the requested DNS resolution. If the -a command line switch is included, the host command displays detailed information about the query performed, and the response received, in "resource record" format. Additionally, the final line identifies the nameserver who resolved the request, and the amount of time the resolution required.