Download
1 / 20
200 likes | 329 Views
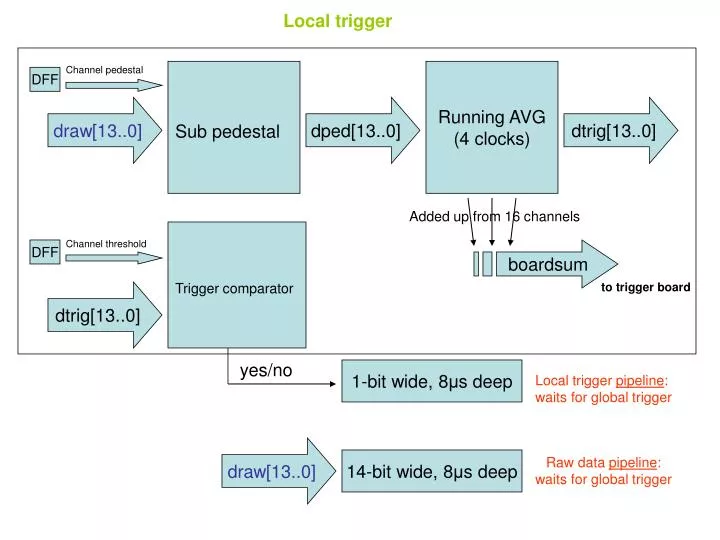
Local trigger. Channel pedestal. Running AVG (4 clocks). DFF. draw[13..0]. dped[13..0]. dtrig[13..0]. Sub pedestal. Added up from 16 channels. Channel threshold. DFF. boardsum. Trigger comparator. to trigger board. dtrig[13..0]. yes/no. 1-bit wide, 8 μ s deep.

E N D
Local trigger Channel pedestal Running AVG (4 clocks) DFF draw[13..0] dped[13..0] dtrig[13..0] Sub pedestal Added up from 16 channels Channel threshold DFF boardsum Trigger comparator to trigger board dtrig[13..0] yes/no 1-bit wide, 8μs deep Local trigger pipeline: waits for global trigger draw[13..0] 14-bit wide, 8μs deep Raw data pipeline: waits for global trigger
Trigger decision and data packer trig offset DFF have trigger! AND Local trigger pipeline total trigger (after ~4μs) - from trigger board read out 32 clocks around trigger point trig offset + pulse offset (~19) DFF Data packer: timing and IDs … 10 10 11 00 00 00 Raw data pipeline 16 bit 14bit timing timing ch/b id Data (29 words) 32 words Timing: an integer 0 - 1.25M that identifies an event within a 1/100 sec spill
32x16 bit packed data prio1 For *each* channel 32x16 bit packed data prio2 Raw data pipeline To VME-addressable pipe 32x16 bit packed data prio3 Channel hypervisor Uses priorities to choose next available buffer 32x16 bit packed data prio4 SUM reports channel priority to board hypervisor One per *board* VME-addressable pipe 8K x 32 bit Board hypervisor x 2 (one reads, one writes) switches every 1/100 sec (“spill”) Chooses highest-priority buffer to read out
Suppose a trigger comes (i.e. coincidence between local and global). Choose 1st buffer with zero priority. Start writing and increment prio to 1. address 31 address 0 1 0 Raw data pipeline 0 0 1
While we are writing, suppose a board hypervisor selects this channel to read. We can start reading this buffer, even though not all 32 words are written yet! read out to VME RAM NOTE: even though prio1=0, the channel hypervisor knows not to write to this buffer! 0 0 Raw data pipeline 0 0 0
Buffer 1 if completely read out. The channel is now empty. 0 0 Raw data pipeline 0 0 0
A new trigger comes. It is routed to buffer 1, which is now empty. It’s priority is immediately increased. address 31 address 0 1 0 Raw data pipeline 0 0 1
Another trigger comes when 1st one is more than 16 clocks done. Start writing (initially with the same data) into next 0-prio buffer. Increment all non-zero priorities by 1 - i.e. those that are older 2 Note: we require that 1st buffer is >16 cycles. See next slide! 1 Raw data pipeline 0 0 3
LATER EARLIER Overlap … … 31 30 29 16 2 1 0 Data time … … 21 16 2 1 0 Already saved! Trigger sampling time Readout! | | | 16 0 0
Another trigger comes when the two are still writing. Since we are already saving everything, ignore it. 2 1 Raw data pipeline 0 0 3
Another trigger comes after 1st buffer is fully uploaded. Start its write (again, duplicating some of the data from buffer 2). Increase prio of old buffers, because we want to read them ASAP. Note: maximum priority value is 4! 3 2 Raw data pipeline 1 0 6
Now, the channel has a high enough prio that the board hypervisor selects it. Then the channel hypervisor selects the highest-prio buffer *within* the channel. In our case, we read out buffer 1. It’s prio is immediately nulled to VME RAM 0 2 Raw data pipeline 1 0 3
Suppose at this moment another trigger comes. The data is routed to buffer 1 – it’s already available! Its prio is increased. Note that we again increase the priorities of old buffers! new event old event to VME RAM 1 3 Raw data pipeline 2 0 6
After this read is finished, another read comes. Buffer 2 – having the highest priority – is selected. 1 to VME RAM 0 Raw data pipeline 2 0 6
After the two reads are finished, another read comes. Buffer 3 is selected. 1 0 Raw data pipeline to VME RAM 0 0 6
Suppose at this moment a VME spill comes (every 1/100 s). We’d like to read out the large VME-addressable buffer, but we cannot: The 32-deep buffers contain data from a previous spill! Solution: promote up to two priorities to “critical”: prio+5. Don’t let VME read the data until all critical buffers are emptied! 6 0 Raw data pipeline to VME RAM 0 0 6 Reported to board hypervisor CRIT
After 3rd buffer is read out, 1st one is selected. VME will be able to read out when: none critical, none reading. If another trigger comes at this moment (belonging to a new spill), it will be saved as it normally would. No downtime! Last critical buffer! to VME RAM 0 1 Raw data pipeline 0 0 1
When the last critical buffer is read-out, the VME addressable buffers switch. VME is informed that it can start the readout from the current buffer. Data from the new spill can now be saved to a fresh VME buffer! 0 VME can RO! 1 Raw data pipeline 0 0 1
VME readout VME-addressable pipe 8K x 32 bit Must be finished within 1/100 sec! VME block Data from buffers VME can RO! MUX VME-addressable pipe 8K x 32 bit Board hypervisor reports “vme ready” reports max address
Virtually no downtime Trigger bursts – limited only by the size of the VME pipeline Will work with much higher trig rate Data almost always ordered in time – i.e. earlier events come first Easily saves latent data on spill request (critical priorities) Increased complexity – by a lot Hard to debug Still can’t fit (in progress!) Some data redundancy – if two triggers come within 32 clocks May lose data on spill request – only 2 bufs can be critical Pluses and Minuses