Download
1 / 48
480 likes | 495 Views
Explore how ontology alignment simplifies complex data queries in geospatial databases, with a focus on the Wisconsin Land Information System (WLIS) and land use codes. Learn about ontology concepts and their alignment process using heuristics and scoring mechanisms.

E N D
“One Simple World” example • Given: Car dealer A, car dealer B, car dealer C… car dealer N, find cars of make Honda or Nissan, under a 100,000 miles, less than $7000, 4 door sedan, and green in color. • Fact: People are different, they model the real world differently !!!! Some people call a car an automobile or they captures the Kilometers instead of miles.
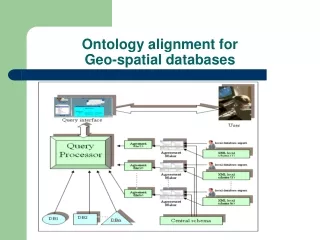
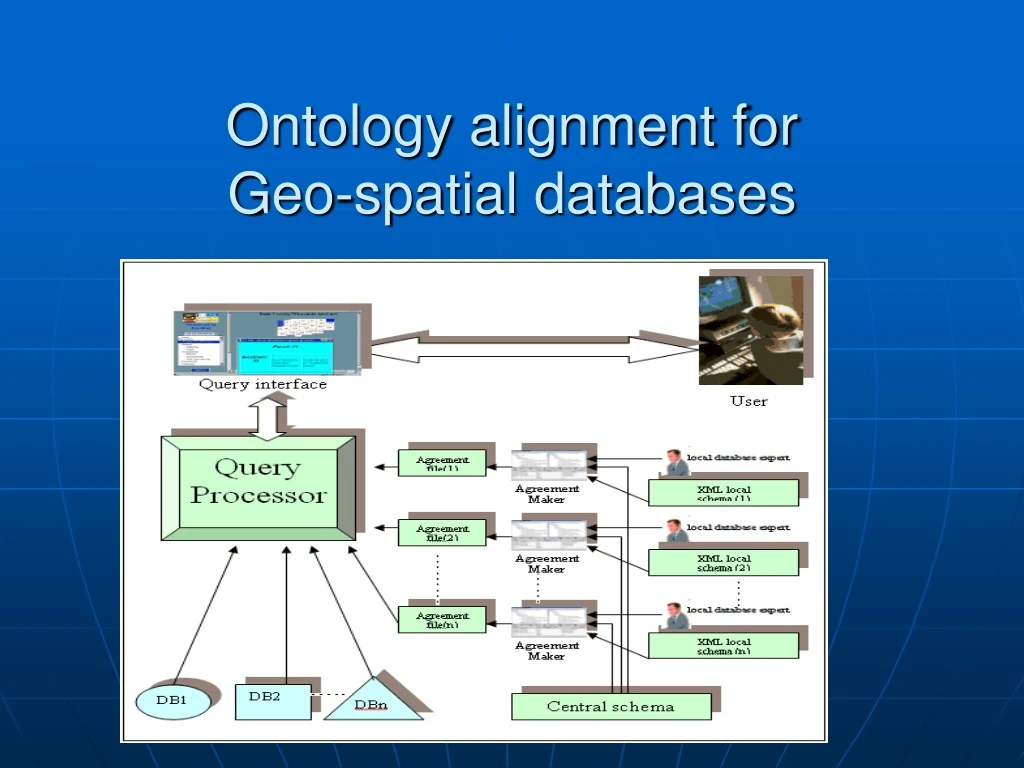
Application • WLIS (Wisconsin Land Information System): web-based system linkingdata from distributed, heterogeneous data sources • Case study: land use codes • Sample query: “Find all the agricultural lands in Dane and Racine counties.” • Different authorities use different land use coding systems leading to syntactic and semantic heterogeneities
Land Use Code Heterogeneity in WLIS Land Use Code Land Use Code Land Use Code Land Use Code There are 72 counties and hundreds of cities and towns in the state; each may have their own system of classifying Land Use codes
Heterogeneity “Find all the agricultural lands in Dane and Racine counties.” Parcel-based example Each highlighted parcel has its own land use classification code
L114 L119 L117 Dane County Parcels • Query “Find all parcels classified as Agriculture – Woodlands – Forests Local Land Use Code Description ParcelID(s) 94 Agriculture -Commercial Forest L114 Agriculture – Woodlands (non-commercial forest) L117, L119 99
What is an ontology ? • an explicit formal specification of how to represent the objects, concepts and other entities that are assumed to exist in some area of interest and the relationships that hold among them(www.doi.org/handbook_2000/glossary.html) • Branch of philosophy concerned with the study of the nature of being. An ontology can be thought of as a description of the nature of some aspect of being or being in general. (www.read-the-bible.org/glossary.html)
Example of Ontology in the Biological Domain CA1 Hippocampus Cell Compartment CA3 Region Glutamate Receptor Dendrite Soma BasketNeuron PyramidicalNeuron Imagebefore LTP contains im_id#1 im_id#3 im_id#5 im_id#7 ImageafterLTP Is_A Receptor im_id#7 im_id#7 im_id#7 im_id#7 AcytelCholin Receptor GabaReceptor [Ludäscher 2001]
Ontology Alignment • Alignment is the process of mapping concepts from one ontology to concepts of another ontology. • Concepts are mapped based on how similar they are to each other. • Similarity takes different shapes: • Similarity in definition • Similarity in the context of the domain • Similarity in text.
When aligning two ontologies, three situations will arise: • Two terms are exactly equivalent • One term is more general than the other • The terms are incompatible Alignment Suggestion Heuristics • Text matches • Hierarchy matches • Data item or form matching
Semi Automated alignment process • Provide set of heuristics that make initial alignment suggestions • Function for integrating these suggestions • Set of alignment validation criteria • Repeated integration cycle • Evaluation metrics
Alignment suggestion heuristics • Text matches • Similarity in naming • Definition matches • Hierarchy matches • Semantic distance • Ambiguity filtering (When a concept can be aligned to more than one alternative, consider only those whose super concepts are somewhere aligned to the super concepts of the target) • Data item or form matches like: • Slot filler restrictions (verb case restriction by (Okumura and Hovy, 1994))
Name (cognate) match • Compare names N1 and N2 of two concepts: • Name score (NAMESCORE) = (number of letters match)^2 + 20(if words exactly equal) + 10 (if end of match coincides) • Examples: • (Cuisine, Limousine) : score = 26 (“sine” substring match earns 16 points, the match is on the end of the names so earn 10 points) • (Cuisine, Business Coverage): score = 16 (compare Cuisine with Business and then compare Cuisine with coverage, take maximum score) • (Kept Woman, Amman) : score = 19
Definition match • Definition match (DEFSCORE): compare the definitions D1 and D2 of two concepts. Remove hyphenation, apostrophizes from definition then demorph it. • Food demorphed definition: (“any” “substance” “that” “can” “Be” “metabolized” “organisim” “give” “energy” “build” “tissue” ). Keep duplicates. • Evaluate three values: • Strength = ratio of number of words shared in both definitions to number of words in the shorter defenition • reliability = number of shared words • DEFSCORE = strength * reliability
Trees • The trees used are ordered and labeled. • Algorithms used to calculate edit distance between sequences • Basically, they are interested of the cost to convert one tree to the other
Edit operations: • There are tree types of edit operation • Re-labeling nodes • Deletion of nodes • Insertion of nodes
Activities of integration scenarios • Schema and Data Management (data representation, structure, data and constraints • Correspondence Management • Mapping Management
Correspondence Management • How different (independently) developed schemas are related? Set of correspondences is determined. • Integration tasks can’t be fully automated, An outside knowledge is needed to get information on how schemas correspond • In their approach, Completeness can’t be achieved automatically or manually
Ontology alignment forGeo-spatial databases ADVIS RESEARCH GROUP THE UNIVERSITY OF ILLINOIS AT CHICAGO
Ontology Alignment • We consider ontologies represented as XML trees. We can map vertices (nodes) from one tree to the other. We establish a global ontology that will be used for querying purposes. The ontologies used by different Jurisdictions are called local ontologies. We map the global ontology to each local one to resolve heterogeneity. • Vertices of the global ontology are mapped to vertices in the local one using different kinds of mapping: exact, subset, superset, approximate, and no mapping (null)
Mapping types • Exact: the connected vertices are semantically equivalent • Subset: the vertex in the global ontology is semantically a subset of the vertex in the local ontology • Superset: the vertex in the global ontology is semantically a superset of the vertex in the local ontology • Approximate: the connected vertices are semantically approximate • No Mapping (Null): the vertex in the global ontology does not have a semantically related vertex in the local ontology
Semi-Automatic mapping • Automate as much as possible the alignment process • User (or system) establishes some mapping types • System propagates the mapping types along the ontologies (bottom-up) as much as possible
Semi-Automatic mapping • To allow for the semi-automatic mapping of the ontology alignment, we propose a framework that defines the values associated with the vertices of the ontology in two possible ways: as functions of the values of the children vertices or of the user input. • For example, in the next figure, vertices b and c in the global ontology are mapped using mapping types exact and superset to vertices e and f in the local ontology. The mapping type between their parents a and d can be deduced to be superset based on the mapping between the children.
Full vs. Partial Mappings Exact Subset a d a d Exact Exact b c f e g b c f e Exact Exact
Full vs. Partial Mappings User-defined Superset a d a d Exact Exact b c f e g b c f e Superset Superset
Agreement Maker • Visual interface for creating agreements • Existing mappings displayed to the user • Displayed list of mappings updated as user identifies more mappings
Demo • Now let us see a demo of the Agreement Maker software that aligns two wetlands classification systems • Agreement maker is being rebuilt at this time. Let’s take a sneak preview of what has been done!!
Current work • Classify mapping types between concepts to • Mapping by definition and language (Automatic procedure that uses wordNet and an advanced scoring system by Sunna and Huang for definition comparison) • Mapping by context (Automatic procedure, what we called before deduction process. Depends on the previous procedure and what the user suggests) • Mapping by user (if user does not approve the previous mapping types. They can enter what they see is appropriate) • Mapping by consolidation (automatic procedure to consolidate all the automatic and manual procedures)
Mapping types 1 • Similarity between concepts can be depicted by: • Definition • Context • User • Consolidation of the previous similarities • Degrees of similarity (applies for the 4 points above): • 100% (Exact match) • 0% (No match) • n% (n<<100% and n>> 0%) (Approximate)
Mapping types 2 • Containment: a concept(s) refer or describes a Subset (or a Superset) of other concept(s) • Intersection: (Proximity… assign degree of intersection) • In Meaning or in Context: • Approximately exact • One concept is approximately a subset of the other • One concept is approximately a superset of the other • Two concepts share something in common • Two concepts share absolutely nothing with each other (0% proximity) • Classing • A concept is a class or a subclass of another (When mapping a schema to an ontology…Thanks Eduard!!!)
DictionaryDatabase User Interface Similarity by defenition by Sunna and Huang DatabaseExtractor User’s Query Non-content words remover Non-content words remover StemmingUnit Inverted Index file Stemming Unit SimilarityCalculator Indexer Results InvertedIndex File
Query system • The query system is expected to be flexible when it comes to collecting results. It will depend on the scores of all mapping procedure to return to the user the most relevant results in descending order. The result of the query will range from 100% relevant (similar to querying a structured database) to a threshold set by the user (similar to querying for semi or non-structured databases).
Questions?? • Thank you for your time