Download

1 / 9
100 likes | 360 Views
AN ITERATIVE TECHNIQUE FOR IMPROVED TWO-LEVEL LOGIC MINIMIZATION. Kunal R. Shenoy Nikhil S. Saluja (University of Colorado, Boulder) Sunil P. Khatri (Texas A&M University, College Station, TX). QUINE McCLUSKY Exact Method for Logic Minimization

E N D
AN ITERATIVE TECHNIQUE FOR IMPROVED TWO-LEVEL LOGIC MINIMIZATION Kunal R. Shenoy Nikhil S. Saluja (University of Colorado, Boulder) Sunil P. Khatri (Texas A&M University, College Station, TX)
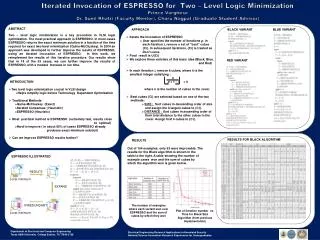
QUINE McCLUSKY Exact Method for Logic Minimization Compute Time is prohibitive for Minimizations (Doubly Exponential) Times-out for medium complexity benchmarks ESPRESSO Heuristic Method for Logic Minimization Based on Unate Recursive Paradigm Inferior to Quine McClusky in minimization Some sacrifice in optimization for a large reduction in run time Relatively unchanged for 20 years. MOTIVATION Performance Comparison Between Quine McClusky and Espresso Hyper-Exact bridges the gap between these 2 methods
HyperExact • Heuristic based on extracting user-defined number of cubes (hyper-cubes) from the onset and placing them in a ‘Hyper-Set’ and running Espresso iteratively. • Improved minimization obtained by considering all the hyper-cubes as don’t cares. • Falls in between Quine McClusky and Espresso in terms of Optimization and runtime. • HyperExact trades-off an acceptable increase in runtime to increase optimization of Espresso. • Three variants have been simulated on benchmarks • One variant showed an improvement in 27 of 58 cases in which there was a potential improvement over Espresso by Quine McClusky, with a peak improvement of 18%.
Hyper-Exact Black • Initially, the HYPER_COVER is initialized to nil. • Next, a set of cubes D*= {Ci} is removed from the cover F and are added to both the don't care set D as well as the HYPER_COVER. • We then call ESPRESSO on the cover iteratively until F becomes empty.
HyperExact philosophy • GASP style techniques try to find newer primes for ESPRESSO to use • Our method allows the exploration of more and newer reductions, improving overall result quality. • This is achieved by increasing the don’t care set in each iteration • Technique is orthogonal to the GASP algorithm used.
Two methods to choose D* • The first method chooses the k largest cubes in each iteration. The intuition behind this is that the largest cubes, when inserted in D, are likely to maximize the chances of other cubes being reduced in different ways. • We refer to this as the SIZE heuristic. • The second heuristic computes the distance of each cube of F from the remaining cubes using the cdist() routine in ESPRESSO. The cubes of F are sorted in ascending order of the sum of their distances to the remaining cubes, and we select the k best cubes from this sorted list. The intuition behind this heuristic is that a cube which has the lowest total distance to other cubes in the cover is likely to be one which allows the most other cubes to be reduced in different manners than before. • We refer to this heuristic as the DISTANCE heuristic.
Hyper-Red The motivating idea behind this variant of our technique is to reduce the run-time overhead by including the HYPER computations within the main ESPRESSO routine. The HYPER-RED algorithm implements the computation of D within the ESPRESSO routine The algorithm does reduce run-time compared to HYPER-BLACK, but the results are inferior to HYPER-BLACK, as described later Hyper-Blue The major difference between this algorithm and the HYPER-RED algorithm is that unlike HYPER-RED, this algorithm extracts essential primes from F during each iteration. This improves run-time over HYPER-BLACK and HYPER-RED though it is still inferior in quality to HYPER-BLACK. The decrease in run-time is because each iteration requires the manipulation of fewer cubes after essential primes are removed. HyperExact Variants
Observations • Shown for Black variant • This graph shows that runtime exponentially decreases with the iteration number, which is the primary reason for the heuristic’s success. • Don’t cares increase with iteration number, resulting in faster reduce/expand/irred computations
Results • The BLACK method typically performs the best, with the most number of wins compared to the RED or BLUE. • The BLACK method with the SIZE heuristic was the best choice in 17 cases for 10 iterations. • The RED method is faster than the BLACK method since the HYPER computations are in the main ESPRESSO routine. However RED performs worse than BLACK, since there is a possibility of inserting non-essential cubes in the HYPER COVER in the RED method reducing the quality of results. • BLUE is typically faster than RED, since it extracts essential primes in every iteration, reducing the size of the problem solved in each iteration. However, its results are comparable with RED, and inferior to BLACK