Download

1 / 51
520 likes | 628 Views
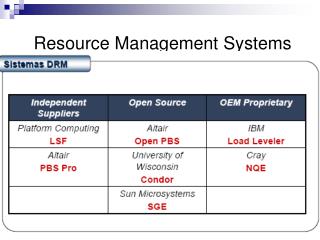
Queueing Systems Configuration vs. Resource Management. Mirosław Kupczyk miron@man.poznan.pl. Agenda. LSF NQE. LSF - overview. Manage Networked Resources Run Jobs Manage Applications Control Access to System Resources Resource and Job Accounting Fault Tolerance

E N D
Queueing Systems Configuration vs. Resource Management Mirosław Kupczyk miron@man.poznan.pl
Agenda • LSF • NQE
LSF - overview • Manage Networked Resources • Run Jobs • Manage Applications • Control Access to System Resources • Resource and Job Accounting • Fault Tolerance • Support for Heterogeneous Systems • Checkpointing and Migration • Parallel Processing
LSF - overview • Scheduling Policies • Resource Reservation • Job Accounting • Job Arrays • Interactive Batch Jobs • Scalability • Shared Resources • Parallel Job Processor Reservation • Job Starters, Pre- and Post-Execution Scripts • Configurable Job Control Actions • LSF SNMP Agent • Command Interpreter
LSF Suite Products • LSF Batch • LSF JobScheduler • LSF Analyzer • LSF Parallel • LSF MultiCluster • LSF Make
Concepts Jobs: • job ID • job name • task or interactive task • interactive batch job • job report • job output • job errors • place a job • dispatch a job • job states: • PEND--Waiting for schedule • RUN--Running • DONE--Finished with zero exit value • EXITED--Finished with non-zero exit value • PSUSP--Pending Suspended • SSUSP--Suspended by LSF • USUSP--Suspended by user • POST_DONE--Post-processing completed without errors • POST_ERR--Post-processing completed with errors
Pending Jobs A job remains pending until all conditions for its execution are met. Some of the conditions are: • Start time specified by the user when the job is submitted • Load conditions on qualified hosts • Dispatch windows during which the queue can dispatch and qualified hosts can accept • jobs • Run windows during which jobs from the queue can run • Limits on the number of job slots configured for a queue, a host, or a user • Relative priority to other users and jobs • Availability of the specified resources • Job dependency and pre-execution conditions
Abnormal Termination of Jobs • An abnormally terminated job goes into EXIT state. The situations where a job • terminates abnormally include: • The job is cancelled by its owner or the LSF administrator while pending, or after being • dispatched to a host. • The job is not able to be dispatched before it reaches its termination deadline, and thus • is aborted by LSF. • The job fails to start successfully. For example, the wrong executable is specified by the • user when the job is submitted. • The job exits with a non-zero exit status.
Concepts (contd.) • Hosts • host types • local and remote hosts • master host or LSF master • submission and execution hosts • server host or LSF server • client host or LSF client
Concept: Queues • Queues represent a set of pending jobs, lined up in a defined order and waiting for their opportunity to use LSF resources. • Queues implement different job scheduling and control policies. • All jobs submitted to the same queue share the same scheduling and control policy. • Queues do not correspond to individual hosts; each queue can use all server hosts in the cluster, or a configured subset of the server hosts.
Queue: example Begin Queue QUEUE_NAME = normal PRIORITY = 30 NICE = 20 STACKLIMIT= 2048 DESCRIPTION = For normal low priority jobs, running only if hosts are lightly loaded. QJOB_LIMIT = 60 # job limit of the queue PJOB_LIMIT = 2 # job limit per processor ut = 0.2 io = 50/240 CPULIMIT = 180/hostA # 3 hours of hostA USERS = all HOSTS = all End Queue
Queue configuration QJOB_LIMIT QUEUE_NAME RCVJOBS_FROM REQUEUE_EXIT_VALUES RERUNNABLE RES_REQ RESUME_COND RUN_WINDOW RUNLIMIT SLOT_RESERVE SNDJOBS_TO STACKLIMIT STOP_COND SWAPLIMIT TERMINATE_WHEN UJOB_LIMIT USERS INTERACTIVE JOB_ACCEPT_INTERVAL JOB_CONTROLS JOB_STARTER load_index MAX_RSCHED_TIME MC_FAST_SCHEDULE MEMLIMIT MIG NEW_JOB_SCHED_DELAY NICE NQS_QUEUES PJOB_LIMIT POST_EXEC PRE_EXEC PREEMPTION PRIORITY PROCESSLIMIT PROCLIMIT ADMINISTRATORS BACKFILL CHKPNT CHUNK_JOB_SIZE CORELIMIT CPULIMIT DATALIMIT DEFAULT_HOST_SPEC DISPATCH_WINDOW EXCL_RMTJOB EXCLUSIVE FAIRSHARE FILELIMIT HJOB_LIMIT HOSTS IGNORE_DEADLINE IMPT_JOBBKLG
Clusters • Load sharing in LSF is based on clusters. A cluster is a collection of hosts running LSF. Hosts are configured centrally and managed from any machine in the LSF cluster. • A cluster can contain a mixture of host types. By putting all hosts types into a single cluster, you can have easy access to the resources available on all host types. • Clusters are normally set up based on administrative boundaries. LSF clusters work best when each user has an account on all hosts in the cluster, and user files are shared among the hosts so that they can be accessed from any host. This way LSF can send a job to any host. You need not worry about whether the job will be able to access the correct files. • LSF can also run batch jobs when files are not shared among the hosts. LSF includes facilities to copy files to and from the host where the batch job is run, so your data will always be in the right place.
Clusters contd. A cluster is a group of hosts that provide shared computing resources. Hosts can be grouped into clusters in a number of ways. A cluster could contain: All the hosts in a single administrative group All the hosts on one file server or sub-network Hosts that perform similar functions If you have hosts of more than one type, it is often convenient to group them together in the same cluster. LSF allows you to use these hosts transparently, so applications that run on only one host type are available to the entire cluster.
first-come, first-served (FCFS) - The default type of scheduling in LSF. Jobs are considered for dispatch based on their order in the queue (FCFS). - job slot: A job slot is a bucket into which a single unit of work is assigned in the LSF system. Hosts are configured to have a number of job slots available and queues dispatch jobs to fill job slots.
LSF Daemons LIM (Load Information Manager) on each LSF server, monitors its host's load, and forwards load information to the master LIMs. LIM collects 11 built-in load indices. Master LIM is elected to store load data collected by LIMs running on hosts in the LSF cluster. On one host in the cluster, the LIM acts as the master. The master LIM runs on the master host and forwards load information to MBD. The master LIM collects information for all hosts and provides that information to the applications. The master LIM is chosen among all the LIMs running in the cluster. If the master LIM becomes unavailable, a LIM on another host will automatically take over the role of master. External LIMs are site-definable to collect up to 256 different resources. RES (Remote Execution Server) runs on each LSF server and accepts remote execution requests and provides fast, transparent and secure remote execution of interactive jobs. RES executes jobs and tasks in the background as the job owner. RES is similar to rshd (Remote Shell Daemon).
LSF Daemons contd. SBD (Slave Batch Daemon) runs on each LSF server, receives job requests from MBD, and starts the jobs using RES. SBD is responsible for enforcing local LSF policies and maintaining the state of jobs on the machine. MBD (Master Batch Daemon) receives job requests from LSF clients and servers and applies scheduling policies to dispatch the jobs to LSF servers in the cluster. MBD is responsible for the overall state of all jobs in the batch system. MBD keeps a file of all transactions performed on jobs throughout their lifecycle. MBD manages queues and schedules jobs on all hosts in the LSF cluster. Each cluster has one MBD, which runs on the master host. PIM (Process Information Manager) runs on each LSF server, and is responsible for monitoring all jobs and monitoring every process created for all jobs running on the server. PIM periodically walks the process tree, and accumulates memory and CPU use data which is reported to SBD. PIM provides run time resource use for all LSF jobs.
How LSF works 1. Receive the job. Create a job file. Return the job ID to the user. 2. During the next dispatch turn, consider the job for dispatch. 3. Place the job on the best available host. 4. Set the environment on the host. 5. Start the job.
Job Submission The job must be submitted to a queue. How Automatic Queue Selection Works: The criteria LSF uses for selecting a suitable queue are as follows: • User access restriction. Queues that do not allow this user to submit jobs are not considered. • Host restriction. If the job explicitly specifies a list of hosts on which the job can be run, then the selected queue must be configured to send jobs to all hosts in the list. • Queue status. Closed queues are not considered. • Exclusive execution restriction. If the job requires exclusive execution, then queues that are not configured to accept exclusive jobs are not considered. • Job's requested resources. These must be within the resource limits of the selected queue. If multiple queues satisfy the above requirements, then the first queue listed in the candidate queues (as defined by DEFAULT_QUEUE or LSB_DEFAULTQUEUE) that satisfies the requirements is selected.
Host Selection A number of conditions determine whether a host is eligible: • Host dispatch windows • Resource requirements of the job • Resource requirements of the queue • Host list of the queue • Host load levels • Job slot limits of the host.
Job Dispatch When a job is submitted to LSF, many factors control when and where the job starts to run: • Active time window of the queue or hosts • Resource requirements of the job • Availability of eligible hosts • Various job slot limits • Job dependency conditions • Fairshare constraints • Load conditions
Fairshare Scheduling • Fairshare scheduling divides the processing power of the LSF cluster among users and groups to provide fair access to resources. • By default, LSF considers jobs for dispatch in the same order as they appear in the queue. • If your cluster has many users competing for limited resources, the FCFS policy might not be enough. For example, one user could submit many long jobs at once and monopolize the cluster's resources for a long time, while other users submit urgent jobs that must wait in queues until all the first user's jobs are all done. To prevent this, use fairshare scheduling to control how resources should be shared by competing users. • Fairshare is not necessarily equal share: you can assign a higher priority to the most important users. If there are two users competing for resources, you can: - Give all the resources to the most important user - Share the resources so the most important user gets the most resources - Share the resources so that all users have equal importance
Global Fairshare Global fairshare balances resource usage across the entire cluster according to one single fairshare policy. Resources used in one queue affect job dispatch order in another queue. To configure global fairshare, you must use host partition fairshare. Use the keyword all to configure a single partition that includes all the hosts in the cluster. Example Begin HostPartition HPART_NAME =GlobalPartition HOSTS = all USER_SHARES = [groupA@, 3] [groupB, 7] [default, 1] End HostPartition
Chargeback Fairshare Chargeback fairshare lets competing users share the same hardware resources according to a fixed ratio. Each user is entitled to a specified portion of the available resources. Example Suppose two departments contributed to the purchase of a large system. The engineering department contributed 70 percent of the cost, and the accounting department 30 percent. Each department wants to get their money's worth from the system. 1.Define 2 user groups in lsb.users, one listing all the engineers, and one listing all the accountants. Begin UserGroup Group_Name Group_Member eng_users (user6 user4) acct_users (user2 user5) End UserGroup 2.Configure a host partition for the host, and assign the shares appropriately. Begin HostPartition HPART_NAME = big_servers HOSTS = hostH USER_SHARES = [eng_users, 7] [acct_users, 3] End HostPartition
Priority User Fairshare Priority user fairshare gives priority to important users, so their jobs override the jobs of other users. Example A queue is shared by key users and other users. As long as there are jobs from key users waiting for resources, other users' jobs will not be dispatched. 1.Define a user group called key_users in lsb.users. 2.Configure fairshare and assign the overwhelming majority of shares to the critical users: Begin Queue QUEUE_NAME = production FAIRSHARE = USER_SHARES[[key_users@, 2000] [others, 1]] ... End Queue
Resources Boolean resources are custom resources that describe features that may not be available or identical on all machines in a cluster. For example: • Machines may have different types and versions of operating systems. • Machines may play different roles in the system, such as file server or compute • server. • Some machines may have special-purpose devices needed by some applications. • Certain software packages or licenses may be available only on some of the • machines. Shared resource is a custom resource that is not tied to a specific host, but is associated with the entire cluster, or a specific subset of hosts within the cluster. Examples of shared resources include: • Floating licenses for software packages • Disk space on a file server which is mounted by several machines • The physical network connecting the hosts
Resource Use Jobs submitted through the LSF system will have the resources they use monitored while they are running. This information is used to enforce resource limits and load thresholds as well as fairshare scheduling. LSF collects information such as: • Total CPU time consumed by all processes in the job • Total resident memory usage in kB of all currently running processes in a job • Total virtual memory usage in kilobytes of all currently running processes in a job • Currently active process group ID in a job • Currently active processes in a job
Load Indices Collected By LIM Load indices measure the availability of dynamic, non-shared resources on hosts in the LSF cluster. Load indices are numeric in value. Load indices built into the LIM are updated at fixed time intervals. Viewing Info About Load Indices % lsload HOST_NAME status r15s r1m r15m ut pg ls it tmp swp mem hostN ok 0.0 0.0 0.1 1% 0.0 1 224 43M 67M 3M hostK -ok 0.0 0.0 0.0 3% 0.0 3 0 38M 40M 7M hostG busy *6.2 6.9 9.5 85% 1.1 30 0 5M 400M 385M hostF busy 0.1 0.1 0.3 7% *17 6 0 9M 23M 28M hostV unavail
Checkpointing Jobs Checkpointing a job involves capturing the state of an executing job, the data necessary to restart the job, and not wasting the work done to get to the current stage. The job state information is saved in a checkpoint file. There are many reasons why you would want to checkpoint a job. Fault Tolerance Migration Load Balancing
Types of Checkpointing Kernel-Level Checkpointing Kernel-level checkpointing is provided by the operating system and can be applied to arbitrary jobs running on the system. This approach is transparent to the application, there are no source code changes and no need to re-link your application with checkpoint libraries. User-Level Checkpointing LSF provides a method to checkpoint jobs on systems that do not support kernel-level checkpointing called user-level checkpointing. To implement user-level checkpointing, you must have access to your applications object files (.o files), and they must be re-linked with a set of libraries provided by LSF. This approach is transparent to your application, its code does not have to be changed and the application does not know that a checkpoint and restart has occurred. Application-Level Checkpointing The application-level approach applies to those applications which are specially written to accommodate the checkpoint and restart. The application checkpoints itself either periodically or in response to signals sent by other processes. When restarted, the application itself must look for the checkpoint files and restore its state.
MultiCluster Resource sharing among separately managed sites • Multiple departments/divisions in a large corporation • Computing center supporting many sites • Multiple cooperating organizations Resource sharing among loosely connected sites • Over long distance or slow links • Across WAN with time differences
MultiCluster : Key Requirements • Autonomy • Reliability • Non-shared user accounts and file systems
agreement inter-cluster policy inter-cluster policy MBD MBD MultiCluster : Inter-Cluster Batch Job Flow jobs status users conf, load info Master LIM Master LIM conf, load info
Shared or replicated across clusters lsf.shared lsf.cluster lsf.cluster contact hosts contact hosts other hosts other hosts Configuration : MultiCluster
Configuration : MultiCluster Features in MultiCluster: • Monitoring of load and host information of remote clusters • Accessing control of inter-cluster interactive tasks • Executing batch jobs transparently in remote clusters • Account mapping between clusters
Enabling MultiCluster feature (step 1): • In license.dat files in local/remote clusters: • Needs a FEATURE line to enable LSF MultiCluster feature in local and remote clusters. FEATURE lsf_multicluster lsf_ld 3.200 1-jan-0000 800 BC53D59BDA04DE12166A "Platform” Configuration : MultiCluster
In lsf.cluster.cluster1 In lsf.cluster.cluster2 Begin RemoteClusters CLUSTERNAME EQUIV CACHE_INTERVAL RECV_FROM cluster2 Y 30 N End RemoteCluster Begin RemoteClusters CLUSTERNAME EQUIV CACHE_INTERVAL RECV_FROM cluster1 N 45 Y End RemoteCluster Configuration : MultiCluster • Enabling MultiCluster feature (step 2): • In lsf.cluster.cluster-name files: • Add LSF_MultiCluster keyword in the PRODUCTS line of the Parameters section. Begin Parameters PRODUCTS= LSF_Base LSF_Batch … LSF_MultiCluster End Parameters • If the local cluster is only interested in certain remote cluster specified in the lsf.shared file, you can use the RemoteClusters section to limit which remote clusters the local cluster is interested in.
Begin Cluster ClusterName # keyword cluster1 cluster2 End Cluster If lsf.shared file is not shared or replicated, then it is necessary to specify a list of valid server hosts in each cluster using the option Servers in the Cluster section. Begin Cluster ClusterName Servers # keyword cluster1 (hostA hostB hostC) cluster2 (hostD hostE hostF hostG hostH) End Cluster Configuration : MultiCluster • Enabling MultiCluster feature (step 3): • In lsf.shared files (should be shared or replicated): • Configure LSF Base to distribute interactive tasks across clusters. • Should list the names of all clusters. The lim will read the lsf.shared file in LSF_CONFDIR for each remote cluster and save the first 10 host names listed in the Host section (One of them must be the master).
Enabling MultiCluster feature (step 4): • In lsb.queues file: • Configure LSF Batch to specify the queues sharing jobs. Begin Queue QUEUE_NAME=normal PRIORITY=30 NICE=20 SNDJOBS_TO=queue2@cluster2 queue3@cluster3 … queueN@clusterN RCVJOBS_FROM=cluster2 cluster3 … clusterN End Queue Configuration : MultiCluster
Enabling MultiCluster feature (step 4): Inter-cluster job flow lsb.queues file in cluster1 lsb.queues file in cluster2 Begin Queue QUEUE_NAME=normal PRIORITY=34 SNDJOBS_TO=normal@cluster2 RCVJOBS_FROM=cluster2 RES_REQ=r1m<0.9 HOSTS=hostA hostB DESCRIPTION=Multicluster queue End Queue Begin Queue QUEUE_NAME=normal PRIORITY=20 SNDJOBS_TO=normal@cluster RCVJOBS_FROM=cluster1 RES_REQ=r1m<0.9 HOSTS=hostC hostD hostE DESCRIPTION=Multicluster queue End Queue Configuration : MultiCluster
Enabling MultiCluster feature (step 5): • User level account mapping (~username/.lsfhosts) : • Individual users of the LSF cluster can set up their own account mapping by setting up a .lsfhosts file in their home directories. ~userA/.lsfhosts on hosts in cluster1 ~userB/.lsfhosts on hosts in cluster2 cluster2 userB cluster1 userA • System level account mapping (lsb.users) : • LSF administrator can set up system level account mapping in UserMap section. For example, userA in cluster1 to map to user_A in cluster2. lsb.users in cluster1 lsb.users in cluster2 Begin UserMap LOCAL REMOTE DIRECTION userA userB@cluster2 export userC (userD@cluster2 userE@cluster2) export … End UserMap Begin UserMap LOCAL REMOTE DIRECTION userB userA@cluster1 import (userD userE) userC@cluster1 import … End UserMap Configuration : MultiCluster
NQS Local Submission:
Queue Complexes A queue complex is a set of local batch queues. Each complex has a set of associated attributes, which provide for control of the total number of concurrently running requests in member queues. This, in turn, provides a level of control between queue limits and global limits. The following queue complex limits can be set: Group limits Memory limits Run limits User limits MPP processing element (PE) limits (CRAY T3D systems), or MPP application processing elements (CRAY T3E systems, or number of processors (IRIX systems) To create a queue complex (a set of batch queues), use the following qmgr command: create complex = (queuename(s)) complexname To add or remove queues in an existing complex, use the following qmgr commands: add queues = (queuename(s)) complexname remove queues = (queuename(s)) complexname
Qmgr IMPLEMENTATION • All Cray Research systems • DEC AXP systems • HP 9000 systems • IBM RISC system/6000 systems • SGI systems • SPARC systems The qmgr command provides entry to the queue manager subsystem, which allows authorized administrators to control requests, queues, and daemons associated with the Network Queuing System (NQS). Qmgr> ad[d] des[tinations] = (new_des [, new_des ...]) pipe_queue [position]position = first | before old_des | after old_des | last Adds valid destinations for pipe_queue at a specific position in the existing set.
NLB The Network Load Balancer (NLB) provides status and control of work scheduling within the group of components in the NQE cluster. Sites can use the NLB to provide policy-based scheduling of work in the cluster. NLB collectors periodically collect data about the current workload on the machine where they run. The data from the collectors is sent to one or more NLB servers, which store the data and make it accessible to the NQE GUI Status and Load functions. The NQE GUI Status and Load functions display the status of all requests which are in the NQE cluster and machine load data.