Download

1 / 36
360 likes | 511 Views
Chapter 10 Transactions in Distributed and Grid Databases. 10.1 Grid Database Challenges 10.2 Distributed and Multidatabase Systems 10.3 Basic Definitions on Transaction Management 10.4 ACID Properties of Transactions 10.5 Transaction Management in Various DB Systems

E N D
Chapter 10Transactions in Distributed and Grid Databases 10.1 Grid Database Challenges 10.2 Distributed and Multidatabase Systems 10.3 Basic Definitions on Transaction Management 10.4 ACID Properties of Transactions 10.5 Transaction Management in Various DB Systems 10.6 Requirements in Grid Database Systems 10.7 Concurrency Control Protocols 10.8 Atomic Commit Protocols 10.9 Replica Synchronisation Protocols 10.10 Summary 10.11 Bibliographical Notes 10.12 Exercises
10.1. Grid Database Challenges • Amount of data being produced and stored has increased during last three decades • Advanced scientific applications are data-intensive, collaborative and distributed in nature • Example: • Different group of scientists gathering data for any application (e.g. weather forecast or earth movement) at geographically separated locations. • Data is colleted locally but the experiment must use all these data • Say, all organisations are connected by Grid infrastructure • Data is replicated at multiple sites • One collaborator runs an experiment and forecasts a natural disaster • If the outcome is not strictly serialized between all the replicated sites then other sites may overwrite or never know the outcome of the experiment • From the above example, it is clear that certain applications need strict synchronisation and a high level of data consistency within the replicated copies of the data as well as in the individual data sites D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.1. Grid Database Challenges (cont’d) • Following design challenges are identified from the perspective of data consistency • Transactional requirements may vary depending upon the application requirement. i.e. read queries may be scheduled in any order but write transactions need to be scheduled carefully • Affect of heterogeneity in scheduling policy of sites and maintaining correctness of data is a major design challenge • How does traditional distributed transaction scheduling protocols work in heterogeneous and autonomous Grid environment • How does data replication affect data consistency D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed and Multidatabase Systems • Management of distributed data has evolved with continuously changing computing infrastructure • Distributed architecture that lead to different transaction models can be classified as follows: • Homogeneous distributed architecture: Distributed Database systems • Heterogeneous distributed architecture: Multidatabase systems • Many different protocols have been proposed for each individual architecture but the underlying architectural assumption is the same for all protocols in one category D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases • Distributed database systems store data at geographically distributed sites, but the distributed sites are typically in the same administrative domain, i.e. technology and policy decisions lie in one administrative domain • The design strategy used in bottom-up • Communication among sites are done over a network instead of shared memory • The concept of a distributed DBMS is best suited to individual institutions operating at geographically distributed locations, e.g. banks, universities etc. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) Distributed Database Architectural Model • A Distributed database system in general has three major dimensions: • Autonomy • Distribution and • Heterogeneity • Autonomy: When a database is developed independently of other DBMS, it is not aware of design decisions and control structures adopted at those sites. • Distribution: Distribution dimension deals with physical distribution of data over multiple sites and still maintain the conceptual integrity of the data. Two major types of distribution have been identified: Client/Server distribution and peer-to-peer distribution D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) • Heterogeneity: Heterogeneity may occur at hardware as well as data/transaction model level. Heterogeneity is one of the important factors that need careful consideration in a distributed environment because any transaction that spans more than one database may need to map one data/transaction model to other • Though theoretically the heterogeneity dimension has been identified, a lot of research work and applications have only focussed on homogeneous environment. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
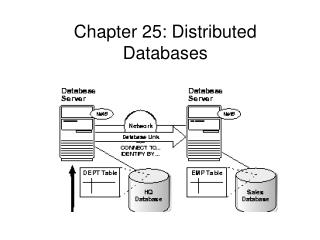
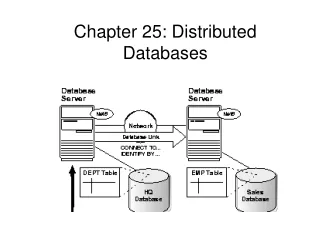
10.2. Distributed Databases (cont’d) Distributed Database Working Model • The figure shows a general Distributed Database architecture • Transactions (T1, T2, … Tn) from different sites are submitted to the Global Transaction Monitor (GTM) • Global Data Dictionary is used to build and execute the distributed queries • Each sub-query is transported to Local Transaction Monitors checked for local correctness and then passed down to Local Database Management System • The results are sent back to the GTM. Any potential problem, e.g. global dead lock, is resolved by GTM after gathering information from all the participating sites. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) • GTM has the following components: • Global transaction request module • Global request semantic analyser module • Global query decomposer module • Global query object localiser module • Global query optimiser module • Global transaction scheduler module • Global recovery manager module • Global lock manager module, and • The transaction dispatcher module D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) Suitability of Distributed DBMS in Grids • Following challenges are faced while applying distributed DB concepts in Grid environment • Distributed DBs have global Data Dictionary and transaction monitor: In Grid environment, it becomes increasingly difficult to manage such a huge global information such as global locks, global data dictionary etc. • Assumption of uniform protocols among distributed sites: e.g. concurrency control protocol assumes that all distributed sites support same protocol (such as locking, timestamp or optimistic). But this assumption is not valid in Grid environment because all sites are autonomous and individual administrative domains choose protocols independently. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) Multidatabase Systems (MDMS) • Multidatabase system can be defined as interconnected collection of autonomous databases. • Fundamental concept in multidatabase system is autonomy. Autonomy refers to the distribution of control and indicates the degree to which individual DBMS can operate independently. Levels of autonomy are as follows: • Design Autonomy: Individual DBMS can use the data models and transaction management techniques without intervention of any other DBMS. • Communication Autonomy: Each DBMS can decide the information it wants to provide to other databases. • Execution Autonomy: Individual databases are free to execute the transactions as per their scheduling strategy. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) Multidatabase Architecture • Each database in multidatabase environment has its own transaction processing components such as a local transaction manager, local data manager, local scheduler etc • Transactions submitted to individual databases are executed independently and local DBMS is completely responsible for its correctness. • MDMS is not aware of any local execution at the local database. • A global transaction that needs to access data from multiple sites is submitted to MDMS, which in turn forwards the request to, and collects result from, the local DBMS on behalf of the global transaction D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.2. Distributed Databases (cont’d) Suitability of Multidatabase in Grids • Architecturally, multidatabase systems are close to Grid databases as individual database systems are autonomous • But, Local database systems in multidatabase systems are not designed for sharing the data • Hence, issues related to efficient sharing of data between sites, e.g. replication, are not addressed in multidatabase systems • The design strategy of multidatabase is a combination of top-down and bottom-up strategy. Individual database sites are designed independently, but the development of MDMS requires the underlying working knowledge of sites. Thus virtualization of resources is not possible in multidatabase architecture. Furthermore, maintaining consistency for global transactions is the responsibility of MDMS. This is undesirable in Grid setup. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.3. Basic Definitions on Transaction Management • Condition (1) states that transactions have read and write operations followed by a termination condition (commit or abort) operation. • Condition (2) says that a transaction can only have one termination operation, i.e. either commit or abort, but not both. • Condition (3) defines that the termination operation is the last operation in the transaction. • Finally, condition (4) defines that if the transaction reads and writes the same data item, it must be strictly ordered. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.3. Basic Definitions on Transaction Management (cont’d) • Where T is a set of transactions. • A pair (opi, opj) is called conflicting pair iff (if and only if): • Operations opi and opj belong to different transactions; Two operations access the same database entity and At least one of them is a write operation • Condition (1) of the definition 10.2 states that a history H represents the execution of all operations of the set of submitted transactions. • Condition (2) emphasises that the execution order of the operations of an individual transaction is respected in the schedule. • Condition (3) is clear by itself. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.3. Basic Definitions on Transaction Management (cont’d) • The history must follow certain rules that will ensure the consistency of data being accessed (read or written) by different transactions. • The theory is popularly known as serializability theory. The basic idea of serializability theory is that concurrent transactions are isolated from one another in terms of their effect on the database. • In theory, all transactions, if executed in a serial manner, i.e. one after another, will not corrupt the data. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.3 Basic Definitions on Transaction Management (Cont’d) • Definition 10.3 states that if any operation, p, of a transaction Ti precedes any operation, q, of some other transaction Tj in a serial history Hs, then all operations of Ti must precede all operations of Tj in Hs. • Serial execution of transactions is not feasible for performance reasons, hence the transactions are interleaved. • Serializability theory ensures the correctness of data if the transactions are interleaved. • A history is serializable if it is equivalent to a serial execution of the same set of transactions. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.3 Basic Definitions on Transaction Management (Cont’d) • Serialization Graph (SG) is the most popular way to examine the serializability of a history. A history will be serializable if and only if (iff) the SG is acyclic. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.3 Basic Definitions on Transaction Management (Cont’d) • Consider following transactions: • T1: r1[x] w1[x] r1[y] w1[y] c1 • T2: r2[x] w2[x] c2 • Consider the following history: • H = r1[x] r2[x] w1[x] r1[y] w2[x] w1[y] • The SG for the history, H, is shown in the following Figure:
Basic Definitions on Transaction Management (Cont’d) • The SG in the previous slide contains a cycle; • Hence the history H is not serializable. • From the above example, it is clear that the outcome of the history only depends on the conflicting transactions. • Ordering of non-conflicting operations in either way has the same computational effect. • View serializability has also been proposed in addition to conflict serializability for maintaining correctness of the data. But from a practical point of view, almost all concurrency control protocols are conflict-based. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.4 ACID Properties of Transactions Lost Update Problem • The problem occurs when two transactions access the same data item in the database and the operations of the two transactions are interleaved in such a way that leaves the database with incorrect value. • Example: Let us assume that D1 is a bank account, with balance of 100 dollars. Transaction T1 withdraws 50 dollars and T2 deposits 50 dollars. After correct execution of transaction the account will have 100 dollars. • Consider the interleaving of operations (against time) as shown in the figure. • It is evident that transaction T2 has read the value of D1 before T1 has updated it and hence the value written by T1 is lost and the account balance is 150 dollars (incorrect) D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.4 ACID Properties of Transactions (Cont’d) • Obtain consistency and reliability aspects a transaction must have following four properties. The properties are known as ACID properties: • Atomicity: The Atomicity property is also known as all-or-nothing property. This ensures that the transaction is executed as one unit of operations, i.e. either all of the transaction’s operations are completed or none at all • Consistency: A transaction will preserve the consistency, if complete execution of the transaction takes the database from one consistent state to another • Isolation: The Isolation property requires that all transactions see a consistent state of the database • Durability: The Durability property of the database is responsible to ensure that once the transaction commits, its effects are made permanent into the database D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.5 Transaction Management in Various DBMS Transaction Management in Centralised and Homogeneous Distributed Database Systems • Both systems operate under single administrative domain • Lock tables, timestamps, commit/abort decisions etc. can be shared • Central management system is used to maintain the ACID properties, e.g. Global Transaction Manager (GTM) • Atomicity: • 2-Phace commit protocol or similar variations are used • all of these commit protocols require the existence of GTM and are consensus-based, and not applicable in Grid database environment. • Consistency: • Consistency of global transactions is responsibility of GTM. GTM is designed in a bottom-up manner to avoid any anomalies • Isolation: • Serializability is the most widely used correctness criterion for ensuring transaction isolation • Global serializability is used as concurrency control criterion • Durability: • Global recovery manager is used to maintain the durability of the system D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.5 Transaction Management in Various DBMS (Cont’d) Transaction Management in Heterogenous (multidatabase) Distributed Database Systems • Clearly distinguishes between local and global transactions • Local Transaction Manager (LTM) is responsible for local transactions and sub-transactions of global transactions executing at its site • GTM manages global transactions to ensure global serializability • ‘Heterogeneous DBMS’ and ‘multidatabase systems’ are used interchangeably • Atomicity • Decision to commit local transactions and sub-transactions of global transactions depend on LTM • Prepare-to-commit operation cannot be implemented in multidatabase systems as they may hold local resources • Consistency • No global integrity constraints. and local integrity constraints are taken care by LTM • Isolation • GTM keeps record of all active Global transactions, that are executing at multiple databases • Durability • Recovery process is hierarchical with local and Multi-DBMS executing their recovery processes separately D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.6 Requirements in Grid Database Systems • Considering the requirement of Grid architecture and the correctness protocols available for distributed DBMSs, a comparison of traditional distributed DBMSs and Grid databases for various architectural properties are shown below D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.6 Requirements in Grid Database Systems (Cont’d) • The above table emphasizes that due to different architectural requirements traditional DBMS techniques will not suffice for Grid Environment • Design philosophy of Grid DB is top down, which is different than traditional DBMSs • No global DBMS • Needs virtualization • Address Replica synchronization issues at protocol level • High precision applications need strict serializability in Grid environment D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.7 Concurrency Control Protocols • Concurrency control protocols are classified based on synchronization criterion • Broadly, Concurrency control protocols are classified as: • Pessimistic: Provides mutually exclusive access to shared data and hence does the synchronization at the beginning of the transaction • Optimistic: Assumes there are few conflicts and does the synchronization towards the end of the transaction execution • Classification of concurrency control protocols is shown in the figure D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.8 Atomic Commit Protocols (ACP) • All cohorts of distributed transaction should either commit or abort to maintain Atomicity • Distributed DBMSs are classified into two categories to study ACPs: • Homogeneous distributed database systems • Heterogeneous distributed database systems • Homogeneous distributed database systems • An ACP helps the processes/subtransactions to reach decision such that: • All subtransactions that reach a decision reach the same one. • A process cannot reverse its decision after it has reached one. • A commit decision can only be reached if all subtransactions are ready to commit. • If there are no failures and all subtransactions are ready to commit, then the decision will be to commit. • Consider occurrence of only those failures that are taken care by the ACP, then all subtransactions will eventually reach a decision. • 2-Phase commit is the simplest and most common ACP D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.8 Atomic Commit Protocols (Cont’d) 2-Phase Commit (2PC): • State diagram of the 2PC is as shown in the diagram • Coordinator sends a vote_request to all the participating sites and enter wait state • Participating sites respond by yes (prepared to commit) or no (abort) • If coordinator receives all yes votes then it decides to commit and informs all participants to commit. Even if a single vote is to abort then the coordinator sends abort message to all participants • Participants then act accordingly, commit or abort • There are 2 phases in the process: Voting phase and decision phase • Other ACPs are: 3-Phase commit, Implicit Yes Vote, Uniform reliable broadcast, uniform timed reliable broadcast, Paxos Commit algorithm etc. D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.8 Atomic Commit Protocols (Cont’d) Heterogeneous Distributed Database Systems • Multidatabase systems assume autonomous environment for transaction execution • Three main strategies for atomic commitment of distributed transaction in heterogeneous environment: • Redo: Even if the global decision is to commit LDBMS may decide to abort the global sub-transaction (as sites are autonomous). Then these sub-transactions of global transaction must redo the write operation to maintain the consistency. • Retry: The whole global sub-transaction is retried instead of just redoing the write operation • Compensate: If the global decision was to abort but the local sub-transaction has committed then a compensating transaction must be executed to semantically undo the effects • These strategies are not suitable for Grid environment; as to compensate a transaction it must be compensatable; or to redo an operation may have cascading affec; or a transaction may keep retrying forever D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.9 Replica Synchronisation Protocols • Grid databases stores large volume of geographically distributed data • Data replication is necessary to achieve: • Increased availability • Improved performance • Replica synchronization protocols need to be designed carefully else purpose of replication may be defeated due to increased overhead of maintaining replicated copies of data • The user has one-copy view of the database and hence the correctness criterion is known as 1-Copy Serializability (1SR) • Replica synchronization protocols such as Write-All, Write-All-Available, primary copy etc. have been proposed • Replica control becomes a non-trivial task when the data can be modified • Recent research in Grid environment has mainly focused on replicated data in read-only queries D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.9 Replica Synchronisation Protocols (Cont’d) Network Partitioning • Network partitioning is a phenomenon that prevents communication between two sets of sites in distributed architecture • Broadly, the network partitioning can be of two types, depending on the communicating set of sites: • simple partitioning: if the network is divided in 2 compartments • multiple partitioning: if the network is divided in more than 2 compartments • Network partitioning doesn’t have much impact for read-only queries • Network partitioning may lead to inconsistent data values if write transactions are present • Replica synchronization protocols must be equipped to deal with network partitioning D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.9 Replica Synchronisation Protocols (Cont’d) • Replica synchronization protocols can be classified in 2 categories: • Pessimistic: eager to replicate all copies to all sites, e.g., ROWA (Read one write all) • Optimistic: allows to execute any transaction in any partition. Increases availability but may jeopardize consistency • Read-One-Write-All (ROWA): • read operation can be done from any replicated copy but write operation must be executed at all replicas • Limits availability of the system • ROWA-Available (ROWA-A): • Provides more flexibility in presence of failures • Reads any replicated copy, but writes all available replicas (if any site is not available ROWA cannot proceed but ROWA-A will still proceed with write) • Primary Copy: • Assigns one copy as the primary copy and all read / write is redirected to the primary copy • Cannot work in network partitioning and single point of failure D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.9 Replica Synchronisation Protocols (Cont’d) • Quorum-based: • Every replica is assigned a vote • Read / write thresholds are defined for each data item • The sum of read and write threshold as well as twice of write threshold must be greater than the total vote assigned to the data. These 2 conditions will ensure that there is always a non-null intersection between any two quorum sets D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008
10.10 Summary • Following three protocols in traditional distributed databases • Concurrency Control protocols • Atomic Commitment protocols • Replica synchronization protocols • Protocols from traditional distributed databases cannot be implemented in Grid databases as is D. Taniar, C.H.C. Leung, W. Rahayu, S. Goel: High-Performance Parallel Database Processing and Grid Databases, John Wiley & Sons, 2008