Download

1 / 26

E N D
1. September 15, 2012 1 A Look at NVIDIA�s Fermi GPU Architecture Richard Walsh
Parallel Applications and Systems Manager
CUNY HPC Center
2. GPU vs CPU, Fermi vs Nehalem Functional Unit Foot Print of Instruction-Oriented
Nehalem x84-64 ISA and micro-architecture, 4 cores 9/15/2012 2
3. Functional Unit Foot-Print of Data-Oriented PTX ISA
FERMI PTX ISA and micro-architecture, 512 (448) cores GPU vs CPU, Fermi vs Nehalem 9/15/2012 3
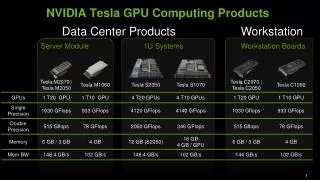
4. Fermi vs Tesla, Quick Comparisons Basic Advances over 3 Generations of NVIDIA GP GPUs 9/15/2012 4
5. Fermi vs Tesla, Quick Comparisons Additional basic comparisons �
Fermi�s clock is somewhat slower, but �
Fermi: 1.15 GHz
Tesla: 1.44 GHz
Fermi has more cores, and �
Fermi: 28 SMs x 32 cores = 448 / GPU
Tesla: 30 SMs x 8 cores = 240 / GPU
Fermi�s 64-bit peak performance is much higher
Fermi: 64-bit floating-point 515 Gflops
Fermi: 32-bit floating-point 1.03 Tflops
Tesla: 32-bit floating-point 1.03 Tflops
Tesla: 64-bit floating-point 86 Gflops
9/15/2012 5
6. Measured Improvement in DP 9/15/2012 6
7. Fermi vs Tesla, Architecture Top Down 9/15/2012 7
8. Fermi Streaming Multiprocessor (SM) 9/15/2012 8 Fermi Streaming Multi-processor
Local compute:
32 simple cores
1 FPU, 1 ALU (pipelined)
16 load store units
4 special functional units
Local data storage:
128KB general purpose registers
64KB shared memory/L1 cache
Instruction issue:
dual issue (2 warps = 2 x 32 ins)
4 pipelines
9. Fermi Improves Accuracy over Tesla Fully compliant with IEEE 754-2008 standard
Applies to both 32-bit and 64-bit floating-point
Includes rounding modes, de-normalized numbers
Higher precision, fused multiply-add (FMA)
64-bit not 1/10 32-bit speed, but now 1/2 (like CPU)
What does this mean for the programmer?
Equivalent (or better) numerical accuracy on GPU
Eliminates need to error check GPU results
Code kernels for GPU and CPU (more) similarly
Somewhat more complex (slower ??) 32-bit pipeline
9/15/2012 9
10. MAD vs FMA GPU and CPU peak performance is measured in terms of combined multiply-add operations 9/15/2012 10
11. Fermi Includes Cache unlike Tesla Fermi memory hierarchy now includes cache(s)
768 KB L2 (unified) cache shared by all SMs
64 KB SM shared memory / L1 cache now configurable
Divide into 16/48 or 48/16 segments, set by function call
Shared by all threads in a block (same SM)
What does it mean for the programmer?
To program shared memory, must know reference pattern
Many algorithms with locality only define it at runtime
In this case, ask for large (48K) L1
L2 helps algorithms with data shared across SMs
Registers now spill to cache not memory !!
Eases programming burden (but encourages laziness ;-) )
Just maximize the size of L1
9/15/2012 11
12. Fermi Cache Hierarchy 9/15/2012 12
13. Fermi Improves Memory Hierarchy Fermi�s memory subsystem reworked
Cache, memory, and buses have ECC
Standard for large HPC systems with long jobs
But slows performance 10-15%
64-bit virtual address space (40-bit physical)
1 TByte is current limit (not 4 GBytes)
Catches up with CPU memory architecture
Hierarchy now a single address space
Referenced by a single pointer type
Improves performance, eases compiler optimization
Enables full C++ support
9/15/2012 13
14. Fermi Improves Memory Hierarchy Fermi�s memory subsystem reworked (cont.)
6 GDDR5 controllers running at 1.5 GHz
Fermi Peak: 6 x 8 bytes x 1.5 GHz x 2 transfers = 144 GB/sec
Fermi Best Measured: ~120 GB/sec
Tesla Peak: 8 x 8 bytes x 0.8 GHz x 2 transfers = 102 GB/sec
Tesla Best Measured: ~ 80 GB/sec
Up to 6 Gbytes of device memory, but �
Our Fermi�s have only 3 Gbytes of memory
Less than our Tesla�s
PCI-E 16x Gen 2 bus offers 2-way memory transfers
Other things being equal why might one say that peak memory bandwidth on a GPU does not need to be as high as it does on a CPU � ?? 9/15/2012 14
15. Fermi, Tesla Pointer Differences Tesla�s PTX ISA 1.0 manages three distinct pointer types, while Fermi PTX 2.0 integrates these into a single 64-bit integer address 9/15/2012 15
16. Fermi Improves Instruction Pipeline Fermi has wider, improved instruction issue pipeline
GigaThread Engine maps threads to SM Scheduler
Scheduler can now issue 2 warps at once
Warp is 32 instructions wide, have no dependencies
Warps issued in thread-order
Each SM can have 32 x 48 = 1536 threads in flight
Scheduler targets 4 pipelined functional unit groups
2 16 unit, 2 cycle, floating-point, integer groups
1 16 unit, 2 cycle, load-store group
1 4 unit, 8 cycle, special function group
9/15/2012 16
17. Fermi Improves Instruction Pipeline Performance Benefits
More threads in flight
Fewer bubbles in pipeline
More forward progress
More latency hiding opportunities
9/15/2012 17
18. Fermi Instruction Pipeline Fermi warp schedulers, view #1 9/15/2012 18
19. Fermi Instruction Pipeline Fermi warp scheduler, view #2 9/15/2012 19
20. Fermi Has a New ISA, PTX 2.0 Fermi�s PTX 2.0 is a virtual instruction set
Tesla�s PTX 1.0 was also
Mapped to machine instructions at runtime
Separates hardware design from compiler design
Fermi�s PTX 2.0 adds:
Predication for all instructions
Marks code for both sides of condition
Execute if true, skip if false
Smaller hardware footprint, better performance
64-bit virtual addresses (uses only 40-bits)
Single unified address space
Just one type of load instruction
Fine-grained exception handling 9/15/2012 20
21. Fermi Improves Fine Grained Control Fermi delivers lower average task granularity
Atomic memory ops implemented in L2 cache
Special dedicated integer unit local to L2 cache
5 to 20x faster synchronizations, reductions
Important for pattern recognition, ray tracing, sorting
10x faster kernel-to-kernel context switching
GigaThread Engine does this
Concurrent kernel execution (from same code)
16 kernels at once (1 per SM)
More efficient, packed use of GPU resources
Easier to combine computation and rendering
Exploit more data-level parallelism 9/15/2012 21
22. Fermi Kernel Packing Lowers Granularity Advantages of concurrent kernel execution 9/15/2012 22
23. On-line References, White Papers Here is a good list of references on Fermi:
http://www.nvidia.com/content/PDF/fermi_white_papers/D.Patterson_Top10InnovationsInNVIDIAFermi.pdf
http://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIAFermi-TheFirstCompleteGPUComputingArchitecture.pdf
http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIAFermiComputeArchitectureWhitepaper.pdf
http://www.nvidia.com/content/PDF/fermi_white_papers/T.Halfhill_Looking_Beyond_Graphics.pdf
http://www.realworldtech.com/page.cfm?ArticleID=RWT093009110932
9/15/2012 23
24. CUNY HPC Center
Thank you �
Questions? 9/15/2012 24
25. 9/15/2012 25
26. 9/15/2012 26