Download

1 / 53
530 likes | 634 Views
LQG Investment Technology Day. Incorporating Stochastic Dominance and Progressive CVaR Levels in Portfolio Models. Gautam Mitra Co-authors: Diana Roman Csaba Fabian Victor Zviarovich. Outline. The problem of portfolio construction Models of Choice Second order stochastic dominance

E N D
LQG Investment Technology Day Incorporating Stochastic Dominance and Progressive CVaR Levels in Portfolio Models Gautam Mitra Co-authors: Diana Roman Csaba Fabian Victor Zviarovich
Outline • The problem of portfolio construction • Models of Choice • Second order stochastic dominance • Index tracking and outperforming • Using SSD for enhanced indexation • Numerical results • Summary and conclusions
Three leading problems Research Problems in Finance • Valuation or pricing of assets • cash flows and returns are random; pricing theory • has been developed mainly for derivative assets. • Ex-ante decision of asset allocation… • optimum risk decisions • portfolio planning or portfolio rebalancing decisions..? • Timing of the decisions • when to execute portfolio rebalancing decisions..?
The message The main focus of the talk • The investment community follows classical{=modern} portfolio • theory based on (symmetric) risk measure.. variance • Computational and applicable models have been enhanced • through capital asset pricing model (CAPM) and • arbitrage pricing theory (APT) • In contrast to investment community… regulators are • concerned with downside (tail) risk of portfolios • The real decision problem is to limit downside risk • and improve upside potential
A historical perspective • Markowitz ..mean-variance 1952,1959 • Hanoch and Levy 1969, valid efficiency criteria individual’s utility function • Kallberg and Ziemba’s study.. alternative utility functions • Sharpe ..single index market model 1963 • Arrow- Pratt.. absolute risk aversion
A historical perspective..cont • Sharpe 64, Lintner 65, Mossin 66…CAPM model • Rosenberg 1974 multifactor model • Ross.. Arbitrage Pricing Theory(APT) multifactor equilibrium model • Text Books: Elton & Gruber, Grinold & Kahn, Sortino & Satchell • LP formulation 1980s.. computational tractability • Konno MAD model.. also weighted goal program • Perold 1984 survey…
Evolution of Portfolio Models Current practice and R&D focus: • Mean variance • Factor model • Rebalancing with turnover limits • Index Tracking (+enhanced indexation)[Style input and goal oriented model] • Cardinality of stock held: threshold constraints • Cardinality of trades: threshold constraints
Target return and risk measuresSymmetric risk measures a critique. Distribution properties of a portfolio …shaping the distribution
The portfolio selection problem • An amount of capital to invest now • n assets • Decision: how much to invest in each asset • Purpose: the highest return after a specified time T • Each asset’s return at time T is a random variable -> decision making under risk • Notations: • n = the number of assets • Rj = the return of asset j at time T • x=(x1,…,xn) portfolio: decision variables; xj = the fraction of wealth invested in asset j • X: the set of feasible portfolios
The portfolio selection problem 3 major problems: • the distribution of (R1,…,Rn) ( -> scenario generation) • the model of choice used • the timing / rebalancing • Portfolio x=(x1,…,xn). Its return: RX=x1R1+…+xnRn • Portfolio y=(y1,…,yn). Its return: RY=y1R1+…+ynRn • RX and RY- random variables • How do we choose between them? Models for choosing between random variables!
The portfolio selection problem • S scenarios: rij=the return of asset j under scenario i; j in 1…n, i in 1..S. (pi=probability of scenario i occurring) • The (continuous) distribution of (R1,…,Rn) is replaced with a discrete one, with a finite number of outcomes
Models for choice under risk • Mean-risk models • Stochastic dominance / Expected utility maximisation “Max” Rx Subject to: x X (1) • Index-tracking models The index’s return distribution is available: RI “Min” |Rx – RI | Subject to: x X (2) • Enhanced indexation models The index’s return distribution is available as a reference; this distribution should be improved .
Models for choice under risk: Mean-risk models • 2 scalars attached to a r.v.: the mean and the value of a riskmeasure. • Let be a risk measure: a function mapping random variables into real numbers. • In the mean-risk approach with risk measure given by ,RX is preferred to r.v. RY if and only if: E(RX)E(RY) and (RX)(RY) with at least one strict inequality.
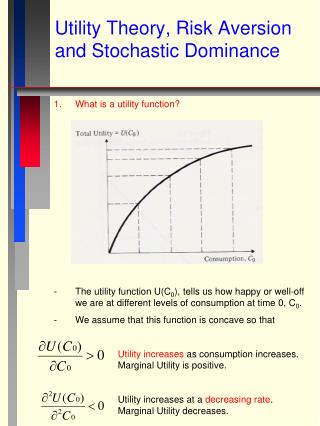
Expected Utility Maximisation • A utility function: a real valued function defined on real numbers (representing possible wealth levels). • Each random return is associated a number: its “expected utility”. • Expected utilities are compared (larger values preferred) • Q: How should utility functions be chosen?
Expected Utility Maximisation: Risk aversion behaviour U U(w) wealth Risk-aversion: the observed economic behaviour A surplus of wealth is more valuable at lower wealth levels concave utility function
Models for choice under risk: Stochastic dominance (SD) SD ranks choices (random variables) under assumptions about general characteristics of utility functions. It eliminates the need to explicitly specify a utility function. • First order stochastic dominance (FSD); • Second order stochastic dominance (SSD); • Higher orders.
First order Stochastic dominance (FSD) probability 1 G(x) G F F(x) outcome x The “stochastically larger” r.v. has a smaller distribution function: F FSDG Strong requirement!
Second order Stochastic dominance (SSD) probability 1 G F outcome A weaker requirement: concerns the “cumulatives” of the distribution functions. Typical example: F starts lower (meaning smaller probability of low outcomes); F SSDG.
Second Order Stochastic dominance (SSD) Particularly important in investment! • Several equivalent definitions: • The economist’s definition: RXSSDRY E[U(RX)] E[U(RY)], U non-decreasing and concave utility function. • (Meaning: RX is preferred to RY by all rational and risk-averse investors). • The intuitive definition: RXSSDRYE[t- RX]+ E[t- RY]+, tR • [t- RX]+= t- RX if t- RX 0 • [t- RX]+= 0 if t- RX < 0
Second Order Stochastic dominance (SSD) Thus SSD describes the preference of rational and risk-averse investors: observed economic behaviour. Unfortunately, very demanding from a computational point of view.
Index Tracking and Enhanced Indexation • Over the last two to three decades, index funds have gained tremendous popularity among both retail and institutional equity investors. This is due to • (i) disillusionment with the performance of active funds, • also (ii) predominantly it reflects attempts by fund managers to minimize their costs. • Managers adopt strategies that allocate capital to both passive index and active management funds. • The funds are therefore run at a reduced cost of passive funds, and managers concentrate on a few active components. • As Dan DiBartolomeo says “Enhanced index funds generally involve a quantitatively defined strategy that ‘tilts’ the portfolio composition away from strict adherence to some popular market index to a slightly different composition that is expected to produce more return for similar levels of risk”.
Index tracking models Traditionally, minimisation of “tracking error”: the standard deviation of the difference between the portfolio and index returns. • Other approaches: • Based on minimisation of other risk measures for the difference between the portfolio and index returns: MAD, semivariance, etc. • Regression of the tracking portfolio’s returns against the returns of the index
Models for choice under risk • Mean-risk models • Stochastic dominance / Expected utility maximisation “Max” Rx Subject to: x X (1) • Index-tracking models The index’s return distribution is available: RI “Min” |Rx – RI | Subject to: x X (2) • Enhanced indexation models The index’s return distribution is available as a reference; this distribution should be improved .
Index tracking models Issues raised: large number of stocks in the portfolio’s composition, low weights for some stocks. Thus: Threshold constraints... cardinality constraints, to reduce transaction costs are imposed -> requires use of binary variables-> leads to computational difficulty. A few models have been proposed: concerned with overcoming the computational difficulty (less focus on the actual fund performance).
Enhanced indexation models • Aim to outperform the index: generate “excess” return. • Relatively new area; no generally accepted approach. • Regression of the tracking portfolio’s returns against the returns of the index; the resulting gap between the intercepts is the excess ‘alpha’ which is to be maximsed • The computational difficulty is a major issue.
SD under equi-probable scenarios Let RX, RYr.v. with equally probably outcomes Ordered outcomes of RX: 1… S Ordered outcomes of RY: 1… S RX FSDRY i i , i = 1…S RX SSDRY 1+…+ i 1+…+ i , i = 1…S Taili(RX) Taili(RY)
Proposed approach • Purpose: to determine a portfolio whose return distribution • is non-dominated w.r. to SSD. • tracks (enhances) a “target” known return distribution (e.g. an index) Assumption: equi-probable scenarios (not restrictive!) the SD relations greatly simplified!
SSD under equi-probable scenarios: an example Consider the case of 4 equi-probable scenarios and two random variables X, Y whose outcomes are: Rearrange their outcomes in ascending order: None of them dominates the other with respect to FSD. Cumulate their outcomes: Y dominates X w.r.t. SSD. Intuitively: it has better outcomes under worst-case scenarios.
SSD under equi-probable scenarios Equivalent formulation using Conditional Value-at-Risk Confidence level (0,1). =A%. CVaR(RX) = - the mean of its worst A% outcomes Thus:
Conditional Value-at-Risk: an example Consider a random return with 100 equally probable outcomes. We order its outcomes; suppose that its worst 10 outcomes are: Confidence level =0.01=1/100: The average loss under the worst 1% of scenarios is 20%. Confidence level =0.05=5/100: CVaR5/100(Rx)=-1/5[(-0.2)+(-0.18)+…+(-0.1)]=0.152 The average loss under the worst 5% of scenarios is 15.2%. Confidence level =0.1=10/100: CVaR10/100(Rx)=-1/10[(-0.2)+(-0.18)+…+(-0.03)]=0.107 The average loss under the worst 10% of scenarios is 10.7%.
A multi-objective model The SSD efficient solutions: solutions of a multi-objective model: (1) Such that: Worst outcome Sum of all outcomes Or: (2) Such that:
The reference point method How do we choose a specific solution? Specify a target (goal) in the objective space and try to come close (or better) to it: If the target is not efficient, outperform it “quasi-satisficing”decisions (Wierzbicki 1983) Target = the tails (or scaled tails) of an index.
The reference point method Let z* =(z1*,…,zS*) be the target zi*= the Tailiof the index (sum of i worst outcomes) Alternatively, zi*= the “scaled” Tailiof the index (mean of the worst i outcomes) Consider the “worst achievement”: The problem we solve: • Basically, it optimises the “worst achievement”.
Expressing tails Cutting plane representation of CVaR / tails (Künzi-Bay and Mayer 2006) Taili(RX) = Min Such that: where = realisation of RX under scenario j • Similar representation for the “scaled” tails.
Model formulation Such that: for each • Similar formulation when “scaled” tails are considered; different results obtained. • Both formulations lead to SSD efficient portfolios that track and improve on the return distribution of the index.
Computational behaviour and… • Very good computational time; problems with tens of thousands of scenarios solved in seconds. ( Pentium 4 , 3.00 GHz, 2 Gbytes Ram. ) • Portfolios computed by this model possess good return distributions (in-sample).
Computational study 3 data sets: past weekly returns considered as equally probable scenarios. • FTSE100: 101 stocks, 115 scenarios • Nikkei: 225 stocks, 162 scenarios • S&P 100: 97 stocks, 227 scenarios The corresponding indices, the same time periods.
Computational study • We construct portfolios based on our proposed models (i)scaled tails (ii) unscaled tails and (iii) tracking error minimisation. No cardinality constraints imposed. • The actual returns are computed for the next time period and compared to the historical return of the index. • Rebalancing frame (weekly): back-testing over the period 5 Jan – 15 March 2009 (10 weeks). • Practicality of the resulting solutions: number of stocks in the composition, necessary rebalancing.
Computational study: FTSE 100 Back-testing: Ex-post returns, 5 Jan – 15 Mar 2009
Computational study: FTSE 100 Back-testing: Ex-post compounded returns,5 Jan – 15 Mar 2009
Computational study: Nikkei 225 Back-testing: Ex-post returns, 5 Jan – 15 Mar 2009
Computational study: Nikkei 225 Back-testing: Ex-post compounded returns, Jan – 15 Mar 2009
Computational study: S&P100 Back-testing: Ex-post returns, 5 Jan – 15 Mar 2009
Computational study: S&P100 Backtesting: Ex-post compounded returns, Jan – 15 Mar 2009
Computational study: composition of portfolios No of stocks (on average) No need to impose cardinality constraints in the SSD based models.
Computational study: composition of portfolios • Composition of SSD portfolios: very stable, only little rebalancing necessary. • Particularly, the case of “unscaled” SSD model: rebalancing is only needed when the new scenarios taken into account make the previous optimum change(lead to a higher difference between worst outcome of the portfolio and the worst outcome of the index). • Case of Nikkei 225 and FTSE100, unscaled SSD model: NO rebalancing was necessary for the 10 time periods of backtesting.
Summary and conclusions • SSD represents the preference of risk-averse investors; • The proposed model selects a portfolio that is efficient w.r.t. SSD, and… • Tracks (improves) a desirable, “target”, “reference” distribution, e.g. that of an index; • Use in the context of enhanced indexation; • The resulting model is solved within seconds for very large data sets;
Summary and conclusions • Back-testing: considerably and consistently realised improved performance over the indices and the index tracking strategies (trackers). • Good strategy in a rebalancing frame: • Naturally few stocks are selected (no need of cardinality constraints); • Little (or no) rebalancing necessary: use as a rebalancing signal strategy.
References • Canakgoz, N.A. and Beasley, J.E. (2008): Mixed-Integer Programming Approaches for Index Tracking and Enhanced Indexation, European Journal of Operational Research 196, 384-399 • Fabian, C., Mitra, G. and Roman, D. (2009): Processing Second Order Stochastic Dominance Models Using Cutting Plane Representations, Mathematical Programming, to appear. • Kunzi-Bay, A. and J. Mayer (2006): Computational aspects of minimizing conditional value-at-risk, Computational Management Science 3, 3-27. • Ogryczak, W. (2002): Multiple Criteria Optimization and Decisions under Risk, Control and Cybernetics, 31, no 4 • Roman, D., Darby-Dowman, K. and G. Mitra: Portfolio Construction Based on Stochastic Dominance and Target Return Distributions, Mathematical Programming Series B 108 (2-3), 541-569. • Wierzbicki, A.P. (1983): A Mathematical Basis for Satisficing Decision Making, Mathematical Modeling, 3, 391-405.