Download

1 / 25
250 likes | 646 Views
More on LR Parsing. Aggelos Kiayias Computer Science & Engineering Department The University of Connecticut 191 Auditorium Road, Box U-155 Storrs, CT 06269-3155. akiayias@cse.uconn.edu http://www.cse.uconn.edu/~akiayias. Picture So Far.

E N D
More on LR Parsing Aggelos Kiayias Computer Science & Engineering Department The University of Connecticut 191 Auditorium Road, Box U-155 Storrs, CT 06269-3155 akiayias@cse.uconn.edu http://www.cse.uconn.edu/~akiayias
Picture So Far • SLR construction:based on canonical collection of LR(0) items – gives rise to canonical LR(0) parsing table. • No multiply defined labels => Grammar is called “SLR(1)” • More general class: LR(1) grammars.Using the notion of LR(1) item and the canonical LR(1) parsing table.
LR(1) Items • DEF. A LR(1) item is a production with a marker together with a terminal:E.g. [S aA.Be, c]intuition: it indicates how much of a certain production we have seen already (aA) + what we could expect next (Be) + a lookahead that agrees with what should follow in the input if we ever do Reduce by the production S aABeBy incorporating such lookahead information into the item concept we will make more wise reduce decisions. • Direct use of lookahead in an LR(1) item is only performed in considering reduce actions. (I.e. when marker is in the rightmost). • Core of an LR(1) item [S aA.Be, c] is the LR(0) item S aA.Be • Different LR(1) items may share the same core.
Usefulness of LR(1) items • E.g. if we have two LR(1) items of the form • [ A . , a ][B . , b ] we will take advantage of the lookahead to decide which reduction to use (the same setting would perhaps produce a reduce/reduce conflict in the SLR approach). • How the Notion of Validity changes: • An item [ A 1.2 , a ] is valid for a viable prefix 1 if we have a rightmost derivation that yields Aaw which in one step yields 12aw
Constructing the Canonical Collection of LR(1) items • Initial item: [ S’ .S , $] • Closure. (more refined) if[A.B , a]belongs to the set of items, and B is a production of the grammar, then:we add the item [B . , b]for all bFIRST(a) • Goto. (the same)A state containing [A.X , a] will move to a state containing [AX. , a] with label X • Every state is closed according to Closure. • Every state has transitions according to Goto.
Constructing the LR(1) Parsing Table • Shift actions: (same)If [A.b , a] is in state Ik and Ik moves to state Imwith label b then we add the actionaction[k, b] = “shift m” • Reduce actions: (more refined)If [A. , a] is in state Ik then we add the action:“Reduce A”into action[A, a]Observe that we don’t use information from FOLLOW(A) anymore. • Goto part of the table is as before.
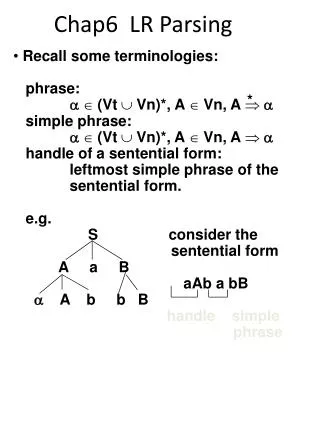
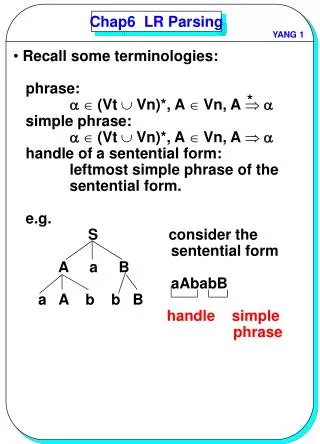
Example I construction S’ SS CC C c C | d FIRST S c d C c d
Example II S’ SS L = R | R L * R | id R L FIRST S *id L *id R *id
LR(1) more general to SLR(1): action[2, = ] ? s6 (because of S L . = R ) THERE IS NO CONFLICT ANYMORE I0 = { [S’ .S , $ ] [S .L = R , $ ] [S .R , $ ] [L .* R , = / $ ] [L . id , = / $ ] [R .L , $ ] } I1 = {[S’ S . , $ ]} S’ SS L = R | R L * R | id R L I2 = { [S L . = R , $ ] [R L . , $ ] } I3 = { [S R. , $ ]} I4 = { [L *.R , = / $ ] [R .L , = / $ ] [L .* R , = / $ ] [L . id , = / $ ] } I5 = {[L id. , = / $ ]}I6 = { [S L = . R , $ ] [R .L , $ ] [L .* R , $ ] [L . id , $ ] } I7 = {[L *R. , = / $ ]} I8 = {[R L. , = / $ ]} I9 = {[L *.R , $ ][R .L , $ ][L .* R , $ ] [L . id , $ ] } I10 = {[L *R. , $ ]} I11 = {[L id. , $ ]} I12 = {[R L. , $ ]}
LALR Parsing • Canonical sets of LR(1) items • Number of states much larger than in the SLR construction • LR(1) = Order of thousands for a standard prog. Lang. • SLR(1) = order of hundreds for a standard prog. Lang. • LALR(1) (lookahead-LR) • A tradeoff: • Collapse states of the LR(1) table that have the same core (the “LR(0)” part of each state) • LALR never introduces a Shift/Reduce Conflict if LR(1) doesn’t. • It might introduce a Reduce/Reduce Conflict (that did not exist in the LR(1))… • Still much better than SLR(1) (larger set of languages) • … but smaller than LR(1), actually ~ SLR(1) • What Yacc and most compilers employ.
Collapsing states with the same core. • E.g., If I3I6 collapse then whenever the LALR(1) parser puts I36 into the stack, the LR(1) parser would have either I3or I6 • A shift/reduce action would not be introduced by the LALR “collapse” • Indeed if the LALR(1) has a Shift/Reduce conflict this conflict should also exist in the LR(1) version: this is because two states with the same core would have the same outgoing arrows. • On the other hand a reduce/reduce conflict may be introduced. • Still LALR(1) preferred: table proportional to SLR(1) • Direct construction is also possible.
Error Recovery in LR Parsing • For a given stack $...Ii and input symbols s…s’…$ it holds that action[i,s] = empty • Panic-mode error recovery.
Panic Recovery Strategy I • Scan down the stack till a state Ij is found • Ij moves with the non-terminal A to some state Ik • Ik moves with s’ to some state Ik’ • Proceed as follows: • Pop all states till Ij • Push A and state Ik • Discard all symbols from the input till s’ • There may be many choices as above. • [essentially the parser in this way determines that a string that is produced by A has an error; it assumes it is correct and advances] • Error message: construct of type “A” has error at location X
Panic Recovery Strategy II • Scan down the stack till a state Ij is found • Ij moves with the terminal t to some state Ik • Ik with s’ has a valid action. • Proceed as follows: • Pop all states till Ij • Push t and state Ik • Discard all symbols from the input till s’ • There may be many choices as above. • Error message: “missing t”
Example E’ EE E + E | | E * E | ( E) | id goto action
Collection of LR(0) items E’ EE E + E | | E * E | ( E) | id I0 I2 I5 I8 E’ .E E (. E ) E E * . E E E * E . E .E + E E .E + E E .E + E E E . + E E .E * E E .E * E E .E * E E E . * E E .( E ) E .( E ) E .( E ) E .id E .id E .id I1 I3 I6 I9 E’ E. E id. E ( E . ) E ( E ) . E E . + E E E . + E E E . * E I4 E E . * E E E + . E E .E + E I7 E .E * E E E + E . E .( E ) E E . + E E .id E E . * E Follow(E’)=$ Follow(E)=+*)$
The parsing table id + * ( ) $ E 0 s3 s2 1 1 s4 s5 acc 2 s3 s2 6 3 r4 r4 r4 r4 4 s3 s2 7 5 s3 s2 8 6 s4 s5 s9 7 s4/r1s5/r1 r1 r1 8 s4/r2 s5/r2 r2 r2 9 r3 r3 r3 r3
Error-handling id + * ( ) $ E 0 s3 e1 s2 1 1 s4 s5 acc 2 s3 s2 6 3 r4 r4 r4 r4 4 s3 s2 7 5 s3 s2 8 6 s4 s5 s9 7 s4/r1s5/r1 r1 r1 8 s4/r2 s5/r2 r2 r2 9 r3 r3 r3 r3
Error-handling I0 I2 I5 I8 E’ .E E (. E ) E E * . E E E * E . E .E + E E .E + E E .E + E E E . + E E .E * E E .E * E E .E * E E E . * E E .( E ) E .( E ) E .( E ) E .id E .id E .id e1 Push E into the stack and move to state 1 “missing operand” : e1 Push id into the stack and change to state 3 “missing operand”
Error-handling id + * ( ) $ E 0 s3 e1e1 s2 e1 1 1 s4 s5 acc 2 s3 s2 6 3 r4 r4 r4 r4 4 s3 s2 7 5 s3 s2 8 6 s4 s5 s9 7 s4/r1s5/r1 r1 r1 8 s4/r2 s5/r2 r2 r2 9 r3 r3 r3 r3
Error-handling id + * ( ) $ E 0 s3 e1e1 s2 e2e1 1 1 s4 s5 e2 acc 2 s3 s2 6 3 r4 r4 r4 r4 4 s3 e1 s2 7 5 s3 s2 8 6 s4 s5 s9 7 s4/r1s5/r1 r1 r1 8 s4/r2 s5/r2 r2 r2 9 r3 r3 r3 r3
Error-handling e2 remove “)” from input. “unbalanced right parenthesis” Try the input id+)
Error-handling state 1 id + * ( ) $ E 0 s3 e1e1 s2 e2e1 1 1 e3 s4 s5 acc 2 s3 s2 6 3 r4 r4 r4 r4 4 s3 s2 7 5 s3 s2 8 6 s4 s5 s9 7 s4/r1s5/r1 r1 r1 8 s4/r2 s5/r2 r2 r2 9 r3 r3 r3 r3
Error-Handling I1 I3 I6 I9 E’ E. E id. E ( E . ) E ( E ) . E E . + E E E . + E E E . * E I4 E E . * E E E + . E E .E + E I7 E .E * E E E + E . E .( E ) E E . + E E .id E E . * E e3 Push + into the stack and change to state 4 “missing operator”
Intro to Translation • Side-effects and Translation Schemes. • Do the construction as before but: • Side-effect in front of a symbol will be executed in a state when we make the move following that symbol to another state. • Side-effects on the rightmost end are executed during reduce actions. side-effects attached to the symbols to the right of them. E’ EE E + E {print(+)} | E * E {print(*)} | {parenthesis++}( E) {parenthesis--} | id { print(id); print(parenthesis); } Do for example id*(id+id)$