Download

1 / 29
290 likes | 455 Views
Variations on Balanced Trees Lazy Red - Black Trees. Stefan Kahrs. Overview. some general introduction on BSTs some specific observations on red-black trees how we can make them lazy - and why we may want to conclusions. Binary Search Trees.

E N D
Variations on Balanced TreesLazy Red-Black Trees Stefan Kahrs
Overview • some general introduction on BSTs • some specific observations on red-black trees • how we can make them lazy - and why we may want to • conclusions
Binary Search Trees • commonly used data structure to implement sets or finite maps (only keys shown): 56 33 227
A problem with ordinary BSTs • on random data searching or inserting or deleting an entry performs in O(log(n)) time where n is the number of entries, but... • if the data is biased then this can deteriorate to O(n) • ...and thus a tree-formation can deteriorate to O(n2)
Therefore... • people have come up with various schemes that make trees self-balance • the idea is always that insertion/deletion pay a O(log(n)) tax to maintain an invariant • the invariant guarantees that search or insert or delete all perform in logarithmic time
Well-known invariants for trees • Braun trees: size of left/right subtree vary by at most 1 – too strong for search trees O(n0.58) • AVL trees: depth of left/right subtree vary by at most 1 • 2-3-4 trees: a node has 1 to 3 keys, and 2 to 4 subtrees (special case of B-tree) • Red-Black trees: an indirect realisation of 2-3-4 trees
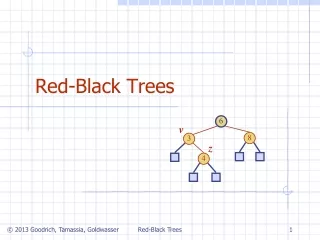
Red-Black Tree • BST with an additional colour field which can be RED or BLACK • invariant 1: red nodes have only black children, root/nil are black • thus, a non-empty black node has between 2 and 4 black children • invariant 2: all paths to leaves go through the same number of black nodes
Example 68 12 83 75 96 7 43 98 94 70 76
Perceived Wisdom • Red-Black trees are cheaper to maintain than AVL trees, though they may not be quite as balanced • pretty balanced though: average path-length for a Red-Black tree is in the worst case only 5% longer that that of a Braun-tree
Aside: a problem with balanced trees • an ordinary BST has on random data an average path length of 2*ln(n) • this is only 38% longer than the average path length of a Braun tree • thus: most balanced tree schemes lose against ordinary BST on random data, because they fail to pay their tax from those 38% • red-black trees succeed though
Algorithms on RB trees • search: unchanged, ignores colour • insert: • insert as in BST (a fresh red node) • rotate subtrees until color violation goes away • colour root black • delete (more complex than insert): • delete as in BST • if underflow rotate from siblings until underflow goes away
Example 68 12 83 75 96 7 43 98 94 70 76 69
Example 68 12 83 75 96 7 43 98 94 70 76 69
Example 75 68 83 12 96 7 43 98 94 70 76 69
Standard Imperative Algorithm • find the place of insertion in a loop • check your parent whether you’re a naughty child, and correct behaviour if necessary, by going up the tree
Problem with this Question: how do you go up the tree? Answer: children should know their parent. Which means: trees in imperative implementations are often not proper trees, every link consists of two pointers
Functional Implementations • in a pure FP language such as Haskell you don’t have pointer comparison and so parent pointers won’t work • instead we do something like this: insert x tree = repair (simplInsert x tree) • simplInsert inserts data in subtree and produces a tree with a potential invariant violation at the top, repair fixes that • the ancestors sit on the recursion stack
Recursion • actually, nothing stops us from doing likewise in an imperative language, using recursive insertion (or deletion) • cost: recursive calls rather than loops • benefit: no parent pointers – saves memory and makes all rotations cheaper • is still more expensive though...
Can we do better? • problem is that the recursive insertion algorithm is not tail-recursive and thus not directly loopifiable: we repair after we insert • what if we turn this around? newinsert x tree = simplinsert x (repair tree) • this is the fundamental idea behind lazy red-black trees
What does that mean? • we allow colour violations to happen in the first place • these violations remain in the tree • we repair them when we are about to revisit a node • this is all nicely loopifiable and requires no parent pointers
In the imperative code • where we used to have... n = n.left; ...to continue in the left branch • we now have: n = n.left = n.left.repair();
Invariants? • the standard red-black tree invariant is broken with this (affects search) • in principle, we can have B-R-R-B-R-R-B-R-R paths, though these are rare • but this is as bad as it gets, so we do have an invariant that guarantees O(log(n)) • average path lengths are similar to RB trees
Performance? • I implemented this in Java, and the performance data were initially inconclusive (JIT compiler, garbage collection) • after forcing gcbetween tests, standard RB remains faster (40% faster on random inputs), though this may still be tweakable • so what is the extra cost, and can we do anything about it?
Checks! • most nodes we visit and check are fine • especially high up in the tree, as these are constantly repaired • ...and the ones low down do not matter that much anyway • so we could move from regular maintenance to student-flat maintenance, i.e. repair trees only once in a blue moon
What? • yes, the colour invariant goes to pot with that • we do maintain black height though... • ...and trust the healing powers of occasional repair: suppose we have a biased insertion sequence and don’t repair for a while...
Example 96 83 70 43 suppose the tree has this shape, and now we insert a 5 in repair-mode 12 7
Result 83 43 96 12 70 7 5
Findings • on random data, performance of lazy red-black trees is virtually unaffected, even if we perform safe-insert only 1/100 • on biased data works a bit better under student-flat, but still loses to RB (15% slower for this bias) • average tree depth: 1.5 longer than RB • on random inputs • also on biased inputs (where BST falls off the cliff)
Conclusions • Ultimately: failure! • Lazy RB trees are not faster than normal ones. • On random inputs, Lazy RB perform very similarly to plain BST • Some small room for improvement – I doubt though the gap to plain RB can be closed • Perhaps other algorithms wouldbenefit more from lazy invariant maintenance?