Download

1 / 5
90 likes | 421 Views
Principal Components Analysis (PCA) 273A Intro Machine Learning. Principal Components Analysis. We search for those directions in space that have the highest variance. We then project the data onto the subspace of highest variance.

E N D
Principal Components Analysis (PCA) 273A Intro Machine Learning
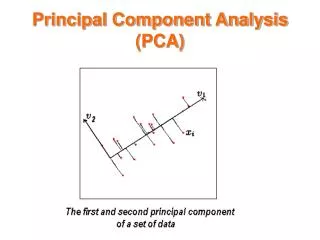
Principal Components Analysis • We search for those directions in space that have the highest variance. • We then project the data onto the subspace of highest variance. • This structure is encoded in the sample co-variance of the data: • Note that PCA is a unsupervised learning method (why?)
0 0 PCA • We want to find the eigenvectors and eigenvalues of this covariance: ( in matlab [U,L]=eig(C) ) eigenvalue = variance in direction eigenvector Orthogonal, unit-length eigenvectors.
0 0 PCA properties (U eigevectors) (u orthonormal U rotation) (rank-k approximation) (projection)
PCA properties is the optimal rank-k approximation of C in Frobenius norm. I.e. it minimizes the cost-function: Note that there are infinite solutions that minimize this norm. If A is a solution, then is also a solution. The solution provided by PCA is unique because U is orthogonal and ordered by largest eigenvalue. Solution is also nested: if I solve for a rank-k+1 approximation, I will find that the first k eigenvectors are those found by an rank-k approximation (etc.)