Download

1 / 35
350 likes | 357 Views
Learn about external sorting and two-pass algorithms for query execution, including sorting, duplicate elimination, grouping, and join operations. Understand the cost model and analyze the performance of different algorithms.

E N D
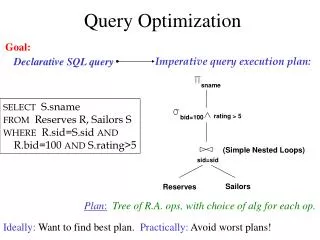
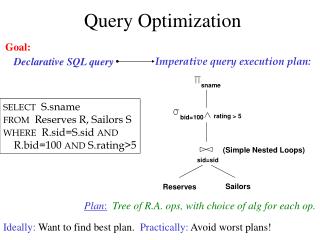
CSE 444: Lecture 24Query Execution Monday, March 7, 2005
Outline • External Sorting • Sort-based algorithms • An example
The I/O Model of Computation • In main memory: CPU time • Big O notation ! • In databases time is dominated by I/O cost • Big O too, but for I/O’s • Often big O becomes a constant • Consequence: need to redesign certain algorithms • See sorting next
Sorting • Problem: sort 1 GB of data with 1MB of RAM. • Where we need this: • Data requested in sorted order (ORDER BY) • Needed for grouping operations • First step in sort-merge join algorithm • Duplicate removal • Bulk loading of B+-tree indexes.
2-Way Merge-sort:Requires 3 Buffers in RAM • Pass 1: Read a page, sort it, write it. • Pass 2, 3, …, etc.: merge two runs, write them Runs of length 2L Runs of length L INPUT 1 OUTPUT INPUT 2 Main memory buffers Disk Disk
Two-Way External Merge Sort • Assume block size is B = 4Kb • Step 1 runs of length L = 4Kb • Step 2 runs of length L = 8Kb • Step 3 runs of length L = 16Kb • . . . . . . • Step 9 runs of length L = 1MB • . . . • Step 19 runs of length L = 1GB (why ?) Need 19 iterations over the disk data to sort 1GB
Can We Do Better ? • Hint:We have 1MB of main memory, but only used 12KB
Cost Model for Our Analysis • B: Block size ( = 4KB) • M: Size of main memory ( = 1MB) • N: Number of records in the file • R: Size of one record
External Merge-Sort • Phase one: load M bytes in memory, sort • Result: runs of length M bytes ( 1MB ) M/R records . . . . . . Disk Disk M bytes of main memory
Phase Two • Merge M/B – 1 runs into a new run (250 runs ) • Result: runs of length M (M/B – 1) bytes (250MB) Input 1 . . . . . . Input 2 Output . . . . Input M/B Disk Disk M bytes of main memory
Phase Three • Merge M/B – 1 runs into a new run • Result: runs of length M (M/B – 1)2 records (625GB) Input 1 . . . . . . Input 2 Output . . . . Input M/B Disk Disk M bytes of main memory
Cost of External Merge Sort • Number of passes: • How much data can we sort with 10MB RAM? • 1 pass 10MB data • 2 passes 25GB data (M/B = 2500) • Can sort everything in 2 or 3 passes !
External Merge Sort • The xsort tool in the XML toolkit sorts using this algorithm • Can sort 1GB of XML data in about 8 minutes
Two-Pass Algorithms Based on Sorting • Assumption: multi-way merge sort needs only two passes • Assumption: B(R)<= M2 • Cost for sorting: 3B(R)
Two-Pass Algorithms Based on Sorting Duplicate elimination d(R) • Trivial idea: sort first, then eliminate duplicates • Step 1: sort chunks of size M, write • cost 2B(R) • Step 2: merge M-1 runs, but include each tuple only once • cost B(R) • Total cost: 3B(R), Assumption: B(R)<= M2
Two-Pass Algorithms Based on Sorting Grouping: ga, sum(b) (R) • Same as before: sort, then compute the sum(b) for each group of a’s • Total cost: 3B(R) • Assumption: B(R)<= M2
Two-Pass Algorithms Based on Sorting x = first(R) y = first(S) While (_______________) do{ case x < y: output(x) x = next(R) case x=y: case x > y;} R ∪ S Completethe programin class:
Two-Pass Algorithms Based on Sorting x = first(R) y = first(S) While (_______________) do{ case x < y: case x=y: case x > y;} R ∩ S Completethe programin class:
Two-Pass Algorithms Based on Sorting x = first(R) y = first(S) While (_______________) do{ case x < y: case x=y: case x > y;} R - S Completethe programin class:
Two-Pass Algorithms Based on Sorting Binary operations: R ∪ S, R ∩ S, R – S • Idea: sort R, sort S, then do the right thing • A closer look: • Step 1: split R into runs of size M, then split S into runs of size M. Cost: 2B(R) + 2B(S) • Step 2: merge M/2 runs from R; merge M/2 runs from S; ouput a tuple on a case by cases basis • Total cost: 3B(R)+3B(S) • Assumption: B(R)+B(S)<= M2
Two-Pass Algorithms Based on Sorting R(A,C) sorted on AS(B,D) sorted on B x = first(R) y = first(S) While (_______________) do{ case x.A < y.B: case x.A=y.B: case x.A > y.B;} R |x|R.A =S.B S Completethe programin class:
Two-Pass Algorithms Based on Sorting Join R |x| S • Start by sorting both R and S on the join attribute: • Cost: 4B(R)+4B(S) (because need to write to disk) • Read both relations in sorted order, match tuples • Cost: B(R)+B(S) • Difficulty: many tuples in R may match many in S • If at least one set of tuples fits in M, we are OK • Otherwise need nested loop, higher cost • Total cost: 5B(R)+5B(S) • Assumption: B(R)<= M2, B(S)<= M2
Two-Pass Algorithms Based on Sorting Join R |x| S • If the number of tuples in R matching those in S is small (or vice versa) we can compute the join during the merge phase • Total cost: 3B(R)+3B(S) • Assumption: B(R)+ B(S)<= M2
Summary of External Join Algorithms • Block Nested Loop Join: B(S) + B(R)*B(S)/M • Partitioned Hash Join: 3B(R)+3B(S) Assuming min(B(R),B(S)) <= M2 • Merge Join 3B(R)+3B(S) Assuming B(R)+B(S) <= M2 • Index Join B(R) + T(R)B(S)/V(S,a) Assuming…
Example Product(pname, maker), Company(cname, city) • How do we execute this query ? SelectProduct.pname FromProduct, Company WhereProduct.maker=Company.cname and Company.city = “Seattle”
Example Product(pname, maker), Company(cname, city) Assume: Clustered index: Product.pname, Company.cname Unclustered index: Product.maker, Company.city
Logical Plan: maker=cname scity=“Seattle” Product(pname,maker) Company(cname,city)
Physical plan 1: Index-basedjoin Index-basedselection cname=maker scity=“Seattle” Company(cname,city) Product(pname,maker)
Physical plans 2a and 2b: Merge-join Which one is better ?? maker=cname scity=“Seattle” Product(pname,maker) Company(cname,city) Index-scan Scan and sort (2a)index scan (2b)
Physical plan 1: T(Product) / V(Product, maker) Index-basedjoin Index-basedselection Total cost: T(Company) / V(Company, city) T(Product) / V(Product, maker) cname=maker scity=“Seattle” Company(cname,city) Product(pname,maker) T(Company) / V(Company, city)
Total cost:(2a): 3B(Product) + B(Company) (2b): T(Product) + B(Company) Physical plans 2a and 2b: Merge-join No extra cost(why ?) maker=cname scity=“Seattle” 3B(Product) Product(pname,maker) Company(cname,city) T(Product) Table-scan Scan and sort (2a)index scan (2b) B(Company)
Plan 1: T(Company)/V(Company,city) T(Product)/V(Product,maker)Plan 2a: B(Company) + 3B(Product)Plan 2b: B(Company) + T(Product) Which one is better ?? It depends on the data !!
Case 1: V(Company, city) T(Company) Case 2: V(Company, city) << T(Company) Example T(Company) = 5,000 B(Company) = 500 M = 100 T(Product) = 100,000 B(Product) = 1,000 We may assume V(Product, maker) T(Company) (why ?) V(Company,city) = 2,000 V(Company,city) = 20
Which Plan is Best ? Plan 1: T(Company)/V(Company,city) T(Product)/V(Product,maker)Plan 2a: B(Company) + 3B(Product)Plan 2b: B(Company) + T(Product) Case 1:Case 2:
Lessons • Need to consider several physical plan • even for one, simple logical plan • No magic “best” plan: depends on the data • In order to make the right choice • need to have statistics over the data • the B’s, the T’s, the V’s



















![Query Execution [15]](https://cdn2.slideserve.com/4816696/query-execution-15-dt.jpg)