Download
1 / 16
160 likes | 169 Views
Explore cost-based transformation techniques and heuristics for selecting physical plans, including order selection for joins and implications of join asymmetry. Learn about join tree optimization and choosing the most efficient query plan.

E N D
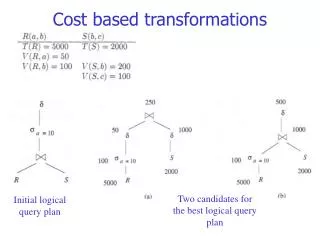
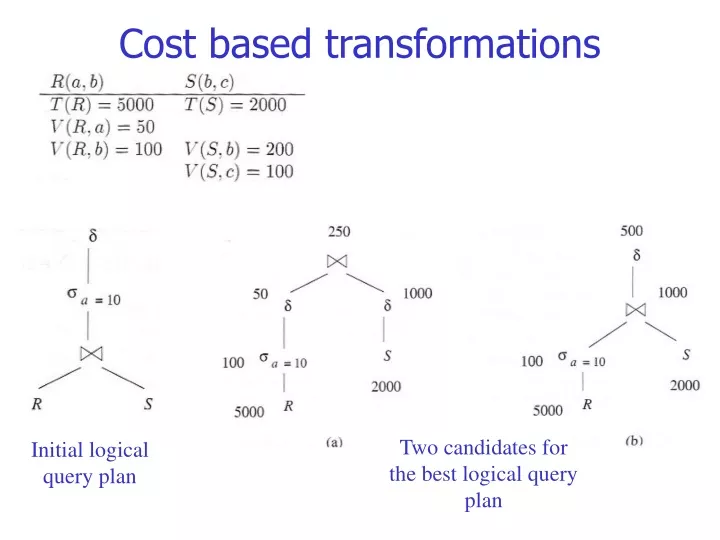
Two candidates for the best logical query plan Initial logical query plan Cost based transformations
Cost based transformations The (estimated) size of a=10(R) is 5000/50 = 100 The (estimated) size of (a=10(R)) is min{1*100, 100/2} = 50 The (estimated) size of (S) is min{200*100, 2000/2} = 1000 The (estimated) size of (a=10(R))(S) is 50*1000/200 = 250
Cost based transformations The (estimated) size of a=10(R) is 5000/50 = 100 The (estimated) size of a=10(R)S is 100*2000/200 = 1000 The (estimated) size of (a=10(R)S) is: From the preservation of value sets V(a=10(R)S,b)=min{V(R,b),V(S,b)}=100 V(a=10(R)S,c)=V(S,c)=100, while V(a=10(R)S,a)=1 So, min{100*100, 1000/2} = 500
Cost based transformations • Adding up the costs of plan (a) and (b), (regarding the intermediary relations) we get: • 1150 • 1100 So, the conclusion is that plan (b) is better, i.e. deferring the duplicate elimination to the end is a better plan for this query.
Cost based transformations • Notice that the estimates at the roots of the two trees are different: 250 in one case and 500 in the other. • Estimation is an inexact science, so these sorts of anomalies will occur. • Intuitively, the estimate for plan (b) is higher because if there are duplicates in both R and S, these duplicates will be multiplied in the join. • e.g., for tuples that appear 3 times in Rand twice in S, their join will appear 6 times. • Our simple formula for estimating the result of does not take into account the possibility that the of duplicates has been amplified by previous operations.
Heuristics for selecting the physical pl. • If the logical plan calls for a selection A=c(R),and stored relation Rhas an index on attribute A, then perform an index-scan to obtain only the tuples of Rwith A value equal to c. • More generally, if the selection involves one condition like A=c above, and other conditions as well, implement the selection by an index-scan followed by a further selection on the tuples. • If an argument of a join has an index on the join attribute(s), then use an index-join with that relation in the inner loop. • If one argument of a join is sorted on the join attribute(s), then prefer a sort-join to a hash-join, although not necessarily to an index-join if one is possible. • When computing the union or intersection of three or more relations, group the smallest relations first.
Choosing an Order for Joins • Critical problem in cost-based optimization: Selecting an order for the (natural) join of three or more relations. • Cost is the total size of intermediate relations. Example: R(a,b), T(R)=1000, V(R,b)=20 S(b,c), T(S)=2000, V(S,b)=50, V(S,c)=100 U(c,d), T(U)=5000, V(U,c)=500 (R S) U versus R (S U) • T(R S) = 1000*2000 / 50 = 40,000 • T((R S)U) = 40000 * 5000 / 500 = 400,000 • T(S U) = 20,000 • T(R (S U)) = 1000*20000 / 50 = 400,000 Both plans are estimated to produce the same number of tuples (no coincidence here). However, the first plan is more costly that the second plan because the size of its intermediate relation is bigger than the size of the intermediate relation in the second plan.
Assymetricity of Joins • That is, the roles played by the two argument relations are different, and the cost of the join depends on which relation plays which role. • E.g., the one-pass join reads one relation - preferably the smaller - into main memory. • The left relation (the smaller) is called the build relation. • The right relation, called the probe relation, is read a block at a time and its tuples are matched in main memory with those of the build relation. Other join algorithms that distinguish between their arguments: • Nested-Loop join, where we assume the left argument is the relation of the outer loop. • Index-join, where we assume the right argument has the index.
title starName=name name StarsIn birthdate LIKE ‘%1960’ MovieStar Join Trees • When we have the join of two relations, we need to order the arguments. SELECT movieTitle FROM StarsIn, MovieStar WHERE starName = name AND birthdate LIKE '%1960'; Not the right order: The smallest relation should be left.
title starName=name This is the preferred order name StarsIn birthdate LIKE ‘%1960’ MovieStar
Join Trees • There are only two choices for a join tree when there are two relations • Take either of the two relations to be the left argument. • When the join involves more than two relations, the number of possible join trees grows rapidly. E.g. suppose R, S, T, and U, being joined. What are the join trees? • There are 5 possible shapes for the tree. • Each of these trees can have the four relations in any order. So, the total number of tree is 5*4! =5*24 = 120 different trees!!
Ways to join four relations left-deep tree All right children are leaves. righ-deep tree All left children are leaves. bushy tree
Why Left-Deep Join Trees? • The number of possible left-deep trees with a given number of leaves is large, but not nearly as large as the number of all trees. • Left-deep trees for joins interact well with common join algorithms - nested-loop joins and one-pass joins in particular. Query plans based on left-deep trees plus these algorithms will tend to be more efficient than the same algorithms used with non-left-deep trees.
Number of plans on Left-Deep Join Trees • For n relations, there is only one left-deep tree shape, to which we may assign the relations in n! ways. • There are the same number of right-deep trees for n relations. • However, the total number of tree shapes T(n)for n relations is given by the recurrence: • T(1)= 1 • T(n)=i=1…n-1T(i)T(n - i) T(1)=1, T(2)=1, T(3)=2, T(4)=5, T(5)=14, and T(6)=42. To get the total number of trees once relations are assigned to the leaves, we multiply T(n)by n!. Thus, for instance, the number of leaf-labeled trees of 6 leaves is 42*6! = 30,240, of which 6!, or 720, are left-deep trees. We may pick any number i between 1 and n - 1 to be the number of leaves in the left subtree of the root, and those leaves may be arranged in any of the T(i)ways that trees with i leaves can be arranged. Similarly, the remaining n-i leaves in the right subtree can be arranged in any of T(n-i)ways.
Dynamic Programming to Select a Join Order and Grouping Dynamic programming: • Fill in a table of costs, remembering only the minimum information we need to proceed to a conclusion. • Suppose we want to join RlR2. . . Rn • We construct a table with an entry for each subset of one or more of the n relations. In that table we put: • The estimated size of the join of these relations. (We know the formula for this) • The least cost of computing the join of these relations. • The expression that yields the least cost. This expression joins the set of relations in question, with some grouping. We can optionally restrict ourselves to left-deep expressions, in which case the expression is just an ordering of the relations.
Join groupings and their costs Example Table for singleton sets Table for pairs Table for triples