Download

1 / 40
400 likes | 445 Views
Explore decision-making, utility evaluation and learning mechanisms of intelligent agents for effective problem solving. Learn about search algorithms, logical inference, Bayesian reasoning & utility models. Understand multi-state search challenges and solution strategies.

E N D
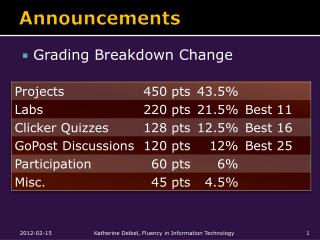
Administrivia/Announcements • Project 0 will be taken until Friday 4:30pm • If you don’t submit in the class, you submit to the dept office and ask them to put it in my mailbox • Homework 1 socket has been opened… • Y’all are supposed to be getting mails sent to the mailing list • Need for Lisp recitation session?
Even basic survival needs state information.. This one already assumes that the “sensorsfeatures” mapping has been done!
EXPLICIT MODELS OF THE ENVIRONMENT --Blackbox models (child function) --Logical models --Probabilistic models Representation & Reasoning
It is not always obvious what action to do now given a set of goals You woke up in the morning. You want to attend a class. What should your action be? Search (Find a path from the current state to goal state; execute the first op) Planning (does the same for logical—non-blackbox state models)
..certain inalienable rights—life, liberty and pursuit of ?Money ?Daytime TV ?Happiness (utility) --Decision Theoretic Planning --Sequential Decision Problems
Discounting • The decision-theoretic agent often needs to assess the utility of sequences of states (also called behaviors). • One technical problem is “How do keep the utility of an infinite sequence finite? • A closely related real problem is how do we combine the utility of a future state with that of a current state (how does 15$ tomorrow compare with 5000$ when you retire?) • The way both are handled is to have a discount factor r (0<r<1) and multiply the utility of nth state by rn • r0 U(so)+ r1 U(s1)+…….+ rn U(sn)+ • Guaranteed to converge since power series converge for 0<r<n • r is set by the individual agents based on how they think future rewards stack up to the current ones • An agent that expects to live longer may consider a larger r than one that expects to live shorter…
Representation Mechanisms: Logic (propositional; first order) Probabilistic logic Learning the models Search Blind, Informed Planning Inference Logical resolution Bayesian inference How the course topics stack up…
Learning Dimensions: What can be learned? --Any of the boxes representing the agent’s knowledge --action description, effect probabilities, causal relations in the world (and the probabilities of causation), utility models (sort of through credit assignment), sensor data interpretation models What feedback is available? --Supervised, unsupervised, “reinforcement” learning --Credit assignment problem What prior knowledge is available? -- “Tabularasa” (agent’s head is a blank slate) or pre-existing knowledge
The important difference from the graph-search scenario you learned in CSE 310 is that you want to keep the graph implicit rather than explicit (i.e., generate only that part of the graph that is absolutely needed to get the optimal path) VERY important since for most problems, the graphs are humongous..
Utility of eyes (sensors) is reflected in the size of the effective search space! In general, a subgraph rather than a tree (loops may be needed consider closing a faulty door when you are enroute to Paris) Given a state space of size n the single-state problem searches for a path in the graph of size n the multiple-state problem searches for a path in a graph of size 2n the contingency problem searches for a sub-graph in a graph of size 2n 2n is the EVILthat every CS student’s nightmares are made of
Utility of eyes (sensors) is reflected in the size of the effective search space! In general, a subgraph rather than a tree (loops may be needed consider closing a faulty door when you are enroute to Paris) Review Given a state space of size n the single-state problem searches for a path in the graph of size n the multiple-state problem searches for a path in a graph of size 2n the contingency problem searches for a sub-graph in a graph of size 2n 2n is the EVILthat every CS student’s nightmares are made of
What happens when the domain Is inaccessible?
Search in Multi-state (inaccessible) version Set of states is Called a “Belief State” So we are searching in the space of belief states
?? General Search
All search algorithms must do goal-test only when the node is picked up for expansion
Search algorithms differ based on the specific queuing function they use
Breadth first search on a uniform tree of b=10 Assume 1000nodes expanded/sec 100bytes/node
Qn: Is there a way of getting linear memory search that is complete and optimal?
The search is “complete” now (since there is finite space to be explored). But still inoptimal.