Download

1 / 16
160 likes | 330 Views
Interfacing Processors and Peripherals. Adopted from the lecture notes of Andreas Klappenecker and Rabi Mahapatra & Hank Walker. Collection of I/O Devices. Communication between I/O devices, processor and memory use protocols on the bus and interrupts. Impact of I/O on Performance.

E N D
Interfacing Processors and Peripherals Adopted from the lecture notes of Andreas Klappenecker and Rabi Mahapatra & Hank Walker
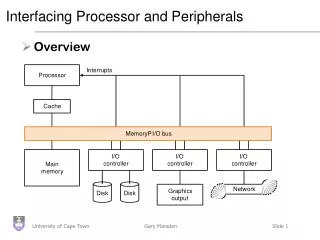
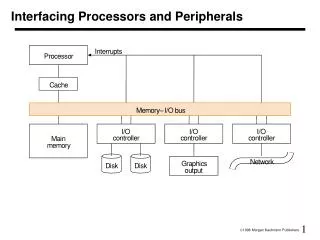
Collection of I/O Devices Communication between I/O devices, processor and memory use protocols on the bus and interrupts
Impact of I/O on Performance A benchmark executes in 100 seconds • 90 seconds CPU time • 10 seconds I/O time If CPU improves 50% per year for next 5 years, how much faster does the benchmark run in 5 years? 90/(1.5)5 = 90/7.59 = 11.851
I/O Devices • Very diverse devices — behavior (i.e., input vs. output) — partner (who is at the other end?) — data rate
Communicating with Processor • Polling • simple • I/O device puts information in a status register • processor retrieves information • check the status periodically • Interrupt driven I/O • device notifies processor that it has completed some operation by causing an interrupt • similar to exception, except that it is asynchronous • processor must be notified of the device csng interrupt • interrupts must be prioritized
I/O Example: Disk Drives • To access data: — seek: position head over the proper track (8 to 20 ms. avg.) — rotational latency: wait for desired sector (.5 / RPM) — transfer: grab the data (one or more sectors) 2 to 15 MB/sec
I/O Example: Buses • Shared communication link (one or more wires) • Difficult design: — may be bottleneck — tradeoffs (buffers for higher bandwidth increases latency) — support for many different devices — cost • Types of buses: — processor-memory (short high speed, custom design) — backplane (high speed, often standardized, e.g., PCI) — I/O (lengthy, different devices, standardized, e.g., SCSI) • Synchronous vs. Asynchronous — use a clock and a synchronous protocol, fast and small, but every device must operate at same rate and clock skew requires the bus to be short — don’t use a clock - use handshaking instead
Asynchronous Handshake Protocol • ReadyReq: Indicates a read request from memory • DataRdy: Indicates that data word is now ready on data lines • Ack: Used to acknowledge the ReadyReq or DataRdy signal of the other party
Asynchronous Handshake Protocol • Memory sees ReadReq, reads address from data bus, raises Ack • I/O device sees Ack high, releases ReadReq and data lines • Memory sees ReadReq low, drops Ack to acknowledge ReadReq • When memory has data ready, it places data from the read request on the data lines and raises DataRdy • I/O devices sees DataRdy, reads data from the bus, signals that it has the data by raising Ack • Memory sees the Ack signal, drops DataRdy, releases datalines • If DataRdy goes low, the I/O device drops Ack to indicate that transmission is over
Synchronous vs. Asynchronous Buses • Compare max. bandwidth for a synchronous bus and an asynchronous bus • Synchronous bus • has clock cycle time of 50 ns • each transmission takes 1 clock cycle • Asynchronous bus • requires 40 ns per handshake • Find bandwidth for each bus when performing one-word reads from a 200ns memory
Synchronous Bus • Send address to memory: 50 ns • Read memory: 200 ns • Send data to device: 50ns • Total: 300 ns • Max. bandwidth: • 4 bytes/300ns = 13.3 MB/second
Asynchronous Bus • Apparently much slower because each step of the protocol takes 40 ns and memory access 200 ns • Notice that several steps are overlapped with memory access time • Memory receives address at step 1 • does not need to put address until step 5 • steps 2,3,4 can overlap with memory access • Step 1: 40 ns • Step 2,3,4: max(3 x 40ns =120ns, 200 ns) • Steps 5,6,7: 3x40ns = 120ns • Total time 360ns • max. bandwidth 4bytes/360ns=11.1MB/second
Other important issues • Bus Arbitration: — daisy chain arbitration (not very fair) — centralized arbitration (requires an arbiter), e.g., PCI — self selection, e.g., NuBus used in Macintosh — collision detection, e.g., Ethernet • Operating system: — polling, interrupts, DMA • Performance Analysis techniques: — queuing theory — simulation — analysis, i.e., find the weakest link (see “I/O System Design”)