Download

1 / 41
420 likes | 588 Views
Matrices. COMM2M Harry R. Erwin, PhD University of Sunderland. Basic Concepts. Vector space Linear transformation. Resources. Korevaar, J., 1968, Mathematical Methods, Academic Press. Vector Space.

E N D
Matrices COMM2M Harry R. Erwin, PhD University of Sunderland
Basic Concepts • Vector space • Linear transformation
Resources • Korevaar, J., 1968, Mathematical Methods, Academic Press.
Vector Space • A vector space or linear space V is a collection of elements with the following properties: • If x and y are any two elements of V then V contains an element that may be called the sum x + y of x and y. • If x is any element of V and an arbitrary scalar (element of the underlying commutative field) then V also contains an element that can be called the scalar multiple x. • In applied mathematics, the underlying commutative field is almost always the real or complex numbers.
Vector Space Axioms • Existence of vector addition. • Addition is commutative. • Addition is associative. • Existence of a unique zero vector. • Existence of a unique additive inverse. • Existence of scalar multiplication. • Scalar multiplication is associative. • Multiplication by 1 is the identity. • Multiplication by 0 produces the zero vector. • Multiplication and addition interact as expected.
Examples of Vector Spaces • Ordinary n-dimensional space, Rn. • Complex n-dimensional space, Cn. • Infinite sequences of real or complex numbers. • The continuous functions, C(a,b), defined on a finite interval (a,b). • Cn(a,b), the continuous functions on the same interval with n continuous derivatives. • The integrable functions on the same interval with a linear norm, 1[a,b] or squared norm, 2[a,b]. • The linear maps between Rn and Rm (or Cn and Cm).
Linear Transformation • A transformation from one vector space into another (or into itself) that commutes with addition and scalar multiplication. If such a transformation is denoted L: • L(x+y) = Lx + Ly • Lx = Lx • Ordinary differentiation is an example. Every linear ordinary or partial differential operator is a linear transformation. • Laplace, Fourier, and other integral transformations are linear.
Matrices and Linear Transformations • Matrix products AxT (where A is a matrix, and xT a column vector) can define linear transformations with respect to given finite dimensional bases over a commutative field. • Many linear problems in engineering and mathematics can be written in the form: • Lx = z.
Vector Spaces and Coordinate Bases • A basis of a vector space is a collection of vectors so that any vector in the space can be uniquely described as a linear combination of those basis vectors. • Every vector space has such a basis. • The number of such basis vectors is the dimension of the vector space. This can be shown unique.
Scalar Norms • For a real number, r, the absolute value of the number, |r|, is defined to be r if r > 0, and otherwise -r. • For a complex number, a + bi, the absolute value of the number is defined to be the positive square root of (a2+b2).
Normed Vector Spaces • A norm for a vector space is a map, m, from the vector space into the non-negative real numbers that has the following properties: • m(v) = ||m(v) • m(a+b) m(a) + m(b) • m(x) = 0 iff x is the zero vector • m can be referred to as a distance function and written ||x||.
Properties of Normed Vector Spaces • In a normed vector space, every basis vector has a length > 0. If the underlying scalar field is the complex or real numbers, each basis vector can be replaced by a basis vector of length one. • Three useful norms are: • ||x||1 = |x1| + . . . + |xn| • ||x||2 = (|x1|2 + . . . + |xn|2) • ||x|| = max(|x1|, . . . , |xn|)
Inner Product • The inner product of two vectors, x and y, in a normed vector space relative to a specific basis of unit vectors is defined as: • x.y = xiyi. Where xi and yi are the coefficients of each vector. • If x.y = 0, the vectors are normal to each other. • If bi.bj = 0 for any two different vectors in the basis, the vector space has an orthonormal basis. This can be very convenient. • A finite dimensional vector space over R or C has an infinite number of such bases.
Matrices and Linear Transformations • Suppose we have a linear transformation, L, between two finite dimensional vector spaces, Fn and Fm, each with an identified basis. L then can be written as a nxm matrix M with coefficients in F. • If T is a transformation between two bases of Fn, (T:B1 -> B2), then the matrix transformation for L written in terms of B2 is T-1.M. If T transforms Fm to Fm, the matrix transformation is M.T, (using matrix multiplication and inversion).
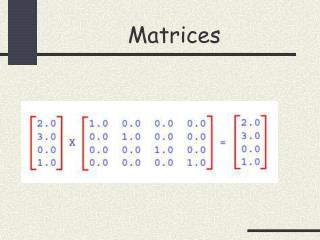
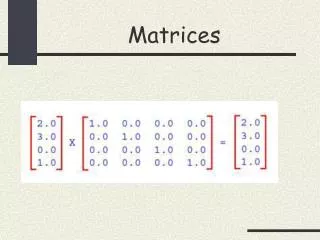
Writing Matrices • A matrix A can this be written as a collection of elements aij, where i is the row number and j is the column number. • The transpose, AT, is a matrix consisting of aji. • Matrices of the same number of rows and columns can be summed. • If matrix A has i rows and j columns, and matrix B has j rows and k columns, the product A.B is defined as a matrix C with i rows and k columns such that cik = aij.bjk.
Other Key Concepts • The rank of a matrix is the rank of the corresponding linear transformation (the dimension of the space that the linear transformation maps into). This may be smaller than the number of columns of the matrix. • Two matrices A, B are equivalent if they represent the same linear transformation for different bases. • Suppose R and S are invertible transformations between bases in the source and destination vector spaces such that R.A = B.S. Then A and B are equivalent.
Square Matrices • A square matrix represents a linear transformation from a vector space to itself. • The square matrix, I (defined as aij = 1.0 if i=j and 0.0 otherwise) represents the identity transformation. • An invertible matrix A has a second unique matrix, A-1 such that A.A-1 = I. Hence A represents a one-to-one linear transformation.
Determinant • The determinant of a linear transformation L from a vector space to itself is a non-zero function to the scalar field that computes the (signed) volume of the image of a n-cube when L is applied to it. The sign describes whether the resulting image has the same orientation. • The determinant is independent of the basis used to represent the transformation. • Algorithms for matrix inversion typically use the determinant. Computing each component of the determinant involves n multiplications, where n is the dimension of the vector space.
Computational Issues in Matrix Arithmetic • Computer arithmetic is almost always inexact: • When you add two variables, much of the significance of the smaller variable can be lost. If it is small enough relative to the other, it is treated as zero. • When you multiply two variables, the lowest order bit of the product is noisy. • When you take the difference of two nearly equal numbers, most of the resulting bits are noise. • Determinants are particularly vulnerable to this.
Problems in Matrix Arithmetic • Watch out for nearly singular systems of linear equations. These are systems where the determinant is close to zero. Round-off errors are likely to make these systems linearly dependent. • Watch for accumulated round-off errors in systems with high dimensionality. Your solutions need to be tested rather than trusted. • Watch out for systems where the row or column norms vary massively. The smaller rows/columns will lose much of their significance. • MATLAB is designed to handle these problems.
MATLAB and Matrices • The basic data type in MATLAB is a double, an array of complex numbers. • At this point, we will consider m by n matrices. A column vector has n = 1 and a row vector has m = 1. • To access the ijth component of the matrix A, use A(i,j).
Creating Matrices • zeros(m,n) (or zeros([m,n])) creates an m-by-n matrix of 0.0. • ones(m,n) creates an m-by-n matrix of 1.0. • eye(m,n) creates an m-by-n matrix of 1.0 for i = j and otherwise 0.0. • eye(m) (etc.) creates an m-by-m matrix. • rand(m,n) contains uniformly distributed random numbers selected from [0,1]. • randn(m,n) contains normally distributed random numbers (from the standard normal distribution).
Literal Matrices • Matrices can be built explicitly using the square bracket notation: • A = [2 3 5 7 11 13 17 19 23] • This creates a 3x3 matrix with those values. • Row ends can be specified by ; instead of carriage returns. Separators are spaces or , • Don’t separate a + or - sign by a space!
Assembling Matrices • B = [1 2; 3 4] • C = [B zeros(2) ones(2) eye(2)] C = 1 2 0 0 3 4 0 0 1 1 1 0 1 1 0 1
Other Approaches • Block diagonal matrices can be created by the blkdiag function. • Tiled matrices can be created by using repmat. • There is a large list of special matrices.
Subscripting and the Colon Notation • The colon is used to define vectors that can act as subscripts. For integers i and j, i:j is used to denote a row vector from i to j in steps of 1. • A nonunit stride or step is denoted i:s:j. • Matrix subscripts (1 or greater!) are accessed as A(i,j). • A(p:q,r:s) is a submatrix of A. • A(:,j) is the jth column and A(i,:) is the ith row. • end represents the last column or row.
Arbitrary Submatrices • A([i j k],[p q]) is the 3x2 submatrix built from the intersection of the ith, jth, and kth rows with the pth and qth columns. • A(:) is a vector consisting of all the elements of A taken from the columns in order from first to last. • A(:) = values will fill A, preserving its shape. • linspace(a,b,n) will create a vector of n values equally spaced from a to b. n defaults to 100.
The Empty Matrix • [] is an empty 0-by-0 matrix. • Assigning [] to a row or column deletes that row or column from the matrix. • Also is used as a placeholder in argument lists.
Left and Right Division • a/b means a/b in the usual sense. • a\b means b/a! • For matrices, these are carried out using matrix operations • A/B means A*B-1 (solving X*B = A) • A\B means A-1*B (solving A*X = B) • For elementwise operations, precede with .
Matrix Powers • A^n is defined for all powers, including negative and non-integer. • .^ is elementwise. • Conjugate transpose operation is A’ • Transpose without conjugation is A.’ • There are functional alternatives. • x’*y is the dot product of two column vectors. • cross(x,y) is the cross product when defined.
Scalars and Matrices • A + x will add x to every entry in A • A*x will multiply every entry in A by x • A/x will divide in the same way.
max min mean median std var sort sum prod cumsum cumprod diff Data Analysis
Linear Algebra and MATLAB • norm(x,y) will give the y-norm of the vector x. y = inf will produce the max absolute value and y = -inf will produce the min absolute value. • The p-norm of a matrix is defined as ||Ax||p/||x||p, for x non-zero in length.
Linear Equations • The fundamental tool is the backslash operator, \. • Solves • Ax = b • AX = B
Results • If A is n-by-n non-singular, A\b is the solution to Ax = b. Solution methods include: • LU factorization with partial pivoting • Triangular (by substitution) • Hermitian positive definite (Cholesky factorization) • Checks conditioning.
Overdetermined • If A is m-by-n, with m>n, it has more equations than unknowns. • A\b is a least squares solution.
Underdetermined System • Fewer equations than unknowns. • If it is solvable at all, A\b produces a basic solution. Otherwise A\b is a least squares solution.
Inverse, Pseudo-Inverse and Determinant • The matrix inverse is computed by inv(A). Not usually needed, A\b is faster and more accurate. • det(A) is the determinant of a square matrix. Sensitive to rounding errors, but accurate for integer matrices. • pinv(A) computes the pseudo-inverse of A.
Tutorial Assignment • A perception of depth in a 2-D display can be generated by the use of a stereogram. • Suppose you have some three-dimensional data {xi,yi,zi}. • Create a pair of side-by-side plots consisting of the vectors (x-d,y) and (x+d,y), where di= c(zmax-zi)*(xmax-xmin)/(zmax-zmin). • c depends on the separation of the displays and the units of measurement. Explore various options.
Suitable Data Can Be Found At: • <http://lib.stat.cmu.edu/>

![[MATRICES ]](https://cdn4.slideserve.com/144276/matrices-dt.jpg)