Download

1 / 13
130 likes | 279 Views
P2P Concept Search. Fausto Giunchiglia Uladzimir Kharkevich S.R.H Noori. April 21st , 200 9, Madrid , Spain. Problems of syntactic approach. Low precision . Caused by: Polysemy ,word or phrase with more senses: Java -> Island, coffee, programming language?

E N D
P2P Concept Search Fausto Giunchiglia Uladzimir Kharkevich S.R.H Noori April21st, 2009,Madrid, Spain
Problems of syntactic approach • Low precision. Caused by: • Polysemy ,word or phrasewith more senses: • Java -> Island, coffee, programming language? • Check-> bank check or Verification? • Complex concepts • Computer table -> A laptop computer is on a coffee table. • Low recall. Caused by: • Synonymy, different words with similar meanings: • Student and Pupil • Related concepts: • Color -> Red , Blue • Car -> Volvo, FIAT, BMW Polysemy Synonymy
Scalability problem • Current web is a huge repository of documents • Number of documents keeps growing significantly • Making difficult to locate relevant documents • Web is a highly dynamic system • Peers are continually joining and leaving the network • All these makes the search problem complex.
Fausto Giunchiglia, Uladzimir Kharkevich, and Ilya Zaihrayeu. Concept search. In Proc. of ESWC'09, Lecture Notes in Computer Science. Springer, 2009. Concept Search • Goal: To extend syntactic search (address problems) • address the ambiguity problem of NL • make uses of related complex concepts • should not be worse than syntactic search!!! • IR_System=<Model, Data_Structure, Term, Match> • Moving from Syntactic IR to C-Search does not require the introduction of new data structures or retrieval models • CSearch reuses retrieval models and data structures of syntactic search • words (W) are substituted with complex concepts (C) • syntactic matching WMatch is substituted with semantic matching • When no semantic information is available, CSearch reduces to syntactic search
Words To Complex Concepts: • Extract phrases • Descriptive phrase : • E.g., A little dog or a huge cat • Convert NL phrases to Complex formulas • Complex concepts are computed by analyzing meaning of the words and phrases. • Expressed in a propositional Description Logic (DL) • E.g., (little-4 ⊓ dog-1) ⊔ (huge-1 ⊓ cat-1) • Lack of background knowledge: • Sometimes it is not possible to find a concept for a word. • => word is used as the identifier for a concept
Syntactic matching to semantic matching • Query answer E.g., A(big-1 ⊓ animal-1, T) = D1 (huge-1 ⊓ white-1 ⊓ elephent-1) • CSearch uses the following three methods to access the background knowledge T , stored on a single peer : • getConcepts(W) - returns a set of all the possible meanings (atomic concepts A) for word W. • getChildren(A) - returns a set of all the more specific atomic concepts of the given atomic concept A in T . • getParents(A) - returns a set of all the more general atomic concepts of the atomic concept A in T .
P2P CSearch • Main idea is to extending CSearch to address the scalability problem • Reasoning extended single BK T to the distributed BK TP2P • Centralized inverted index to distributed index build on top of DHT.
Distributed Background Knowledge(DBK) • Atomic concepts are indexed by words using the DHT 'put' operation • e.g., put(canine, {canine-1, canine-2}). • Every atomic concept is indexed by related atomic concepts+ their relations. • DHT 'put' operation is modified to put(A, B, Rel), • e.g., put(canine-2, dog-1, ' ⊑ '), put(canine-2, carnivore-1, ' ⊒ '). • Getting data from DBK • getConcepts(W) , getChildren(A) and getParents(A) are implemented by usingare implemented by using the DHT 'get' operation • we modified DHT 'get‘ operation get(A, Rel) • e.g., getChildren(A) = get(W, ‘⊑ ') , getParents(A) = get(W, ‘⊒ ').
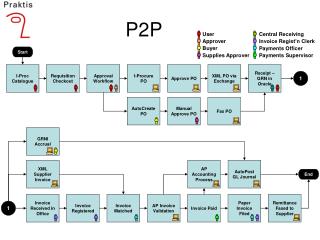
Indexing • Indexing of documents is performed as follows. • Every peer computes a set of atomic concepts A which appear in the representations of peer's documents. • For every atomic concept A, the peer computes a set of documents d which contain A. • For every pair <A, d> the peer computes a set S(d, A) of all the document complex concepts Cd in d, which contain A. • For every A, the peer sends document summaries corresponding to A, i.e., pairs <d, S(d;A)>, to a peer pA responsible for A in DBK. • The peer pA indexes these summaries using the local CSearch.
Retriveval • Step 1: A peer pI initiates the query process for query conceptCq and initialize the query answer QA. • Step 2: For every conjunctive component ⊓ Aq in Cq, pI selects concept A in ⊓ Aq with the smallest number of more specific atomic concepts. For every selected A, Cq is propagated to the peer pA responsible for A. • Step 3: pA receives the Cq and locally computes a set of documents which belong to the query answer. The results are sent directly to pI . On receiving new results, pI merges them with QA. • Step 4: pA computes a set Cms of all more specific atomic concepts B which are directly connected to the given atomic concept A in TP2P . Cms is computed by querying locally stored more specific concepts. • Step 5: pA propagates Cq to all the peers pB responsible for concepts B in Cms, i.e., Step 2 is repeated on all pB.
Conclusion & Future work • P2P CSerarch addresses the scalability problem of CSerarch and the ambiguity problem of natural language in P2P syntactic search. • Future work includes: • Development of techniques which can control the quality of a user input and in general to control the quality of DBK; • Development of document relevance metrics based on both syntactic and semantic similarity of query and document descriptions; • Evaluating the efficiency of the proposed solution.
Thank You! • To read more: • Fausto Giunchiglia, Uladzimir Kharkevich, and Ilya Zaihrayeu. Concept Search. In Proc. of ESWC'09. • Fausto Giunchiglia, Uladzimir Kharkevich, S.R.H Noori P2P Concept Search. Poster at SemSearch 2009 workshop.