Download

1 / 22
380 likes | 671 Views
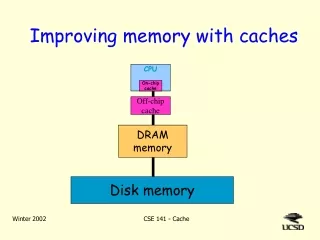
Prof. Sirer CS 316 Cornell University. Multilevel Memory Caches. Storage Hierarchy. SRAM on chip. Technology Capacity Cost/GB Latency Tape 1 TB $.17 100s Disk 300 GB $.34 4ms DRAM 4GB $520 20ns SRAM off 512KB $123000 5ns SRAM on 16 KB ??? 2ns

E N D
Prof. Sirer CS 316 Cornell University Multilevel MemoryCaches
Storage Hierarchy SRAM on chip Technology Capacity Cost/GB Latency Tape 1 TB $.17 100s Disk 300 GB $.34 4ms DRAM 4GB $520 20ns SRAM off 512KB $123000 5ns SRAM on 16 KB ??? 2ns Capacity and latency are closely coupled, cost is inversely proportional How do we create the illusion of large and fast memory? SRAM off chip DRAM Disk Tape
Memory Hierarchy • Principle: Hide latency using small, fast memories called caches • Caches exploit locality • Temporal locality: If a memory location is referenced, it is likely to be referenced again in the near future • Spatial locality: If a memory location is referenced, other locations near it will be referenced in the near future
Cache Lookups (Read) • Look at address issued by processor, search cache tags to see if that block is in the cache • Hit: Block is in the cache, return requested data • Miss: Block is not in the cache, read line from memory, evict an existing line from the cache, place new line in cache, return requested data
Cache Organization • Cache has to be fast and small • Gain speed by performing lookups in parallel, requires die real estate • Reduce hardware required by limiting where in the cache a block might be placed • Three common designs • Fully associative: Block can be anywhere in the cache • Direct mapped: Block can only be in one line in the cache • Set-associative: Block can be in a few (2 to 8) places in the cache
Tags and Offsets • Cache block size determines cache organization 31 Virtual Address 0 31 Tag 5 4 Offset 0 Block
Fully Associative Cache V Tag Block = word/byte select line select Offset Tag = hit encode
Direct Mapped Cache V Tag Block Offset Index Tag =
2-Way Set-Associative Cache V Tag Block V Tag Block Offset Index Tag = =
Valid Bits • Valid bits indicate whether cache line contains an up-to-date copy of the values in memory • Must be 1 for a hit • Reset to 0 on power up • An item can be removed from the cache by setting its valid bit to 0
Eviction • Which cache line should be evicted from the cache to make room for a new line? • Direct-mapped • no choice, must evict line selected by index • Associative caches • random: select one of the lines at random • round-robin: similar to random • FIFO: replace oldest line • LRU: replace line that has not been used in the longest time
Cache Writes Memory DRAM • No-Write • writes invalidate the cache and go to memory • Write-Through • writes go to main memory and cache • Write-Back • write cache, write main memory only when block is evicted CPU addr Cache SRAM data
Dirty Bits and Write-Back Buffers • Dirty bits indicate which lines have been written • Dirty bits enable the cache to handle multiple writes to the same cache line without having to go to memory • Write-back buffer • A queue where dirty lines are placed • Items added to the end as dirty lines are evicted from the cache • Items removed from the front as memory writes are completed D V Tag Data Byte 0, Byte 1 … Byte N Line 1 0 1 1 1 0
Misses • Three types of misses • Cold • The line is being referenced for the first time • Capacity • The line was evicted because the cache was not large enough • Conflict • The line was evicted because of another access whose index conflicted
Cache Design • Need to determine parameters • Block size • Number of ways • Eviction policy • Write policy • Separate I-cache from D-cache
Virtual vs. Physical Caches Memory DRAM CPU • L1 (on-chip) caches are typically virtual • L2 (off-chip) caches are typically physical addr Cache SRAM MMU data Cache works on physical addresses Memory DRAM CPU addr Cache SRAM MMU data Cache works on virtual addresses
Cache Conscious Programming int a[NCOL][NROW]; int sum = 0; for(i = 0; i < NROW; ++i) for(j = 0; j < NCOL; ++j) sum += a[j][i]; • Speed up this program
Cache Conscious Programming int a[NCOL][NROW]; int sum = 0; for(j = 0; j < NCOL; ++j) for(i = 0; i < NROW; ++i) sum += a[j][i]; • Every access is a cache miss!
Cache Conscious Programming int a[NCOL][NROW]; int sum = 0; for(i = 0; i < NROW; ++i) for(j = 0; j < NCOL; ++j) sum += a[j][i]; • Same program, trivial transformation, 3 out of four accesses hit in the cache