Download

1 / 10
100 likes | 221 Views
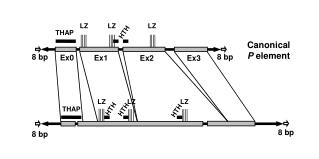
BP - Review. CS/CMPE 333 – Neural Networks. Notation. Consider a MLP with P input, Q hidden, and M output neurons There are two layers of inputs and outputs. Two single-layer networks are connected in series where the output of the first become the input to the second

E N D
BP - Review CS/CMPE 333 – Neural Networks
Notation • Consider a MLP with P input, Q hidden, and M output neurons • There are two layers of inputs and outputs. Two single-layer networks are connected in series where the output of the first become the input to the second • For convenience each layer can be considered separately • If track of both layers have to be kept then an superscript index may be used to indicate layer number, e.g. w212 CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
Identifying Parameters • Letter indices i, j, k, m, n, etc are used to identify parameters • If two or more indices are used, then the alphabetical order of the indices indicate the relative position of the parameters. E.g. xiyj indicates that the variable x corresponds to a layer that precedes the variable y (i -> j) • wji = synaptic weight connecting neuron i to neuron j CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
l W1 W2 -1 x0 = -1 1 x1 y1 Q yM xp Layer 1 Layer 2 CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
BP Equations (1) • Delta rule wji(n+1) = wji(n) + Δwji(n) where Δwji(n) = ηδj(n)yi(n) • δj(n) is given by • If neuron j lies in the output layer δj(n) = φj’(n)ej(n) • If neuron j lies in a hidden layer δj(n) = φj’(vj(n)) Σk δk(n)wkj(n) CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
BP Equations (2) When logistic sigmoidal activation functions are used • δj(n) is given by • If neuron j lies in the output layer δj(n) = yj(n)[1 – yj(n)] ej(n) = yj(n)[1 – yj(n)][dj(n) – yj(n)] • If neuron j lies in a hidden layer δj(n) = yj(n)[1 – yj(n)] Σk δk(n)wkj(n) CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
Matrix/Vector Notation (1) • wji = the synaptic weight from the ith neuron to the jth neuron (where neuron i precedes neuron j) • wji = element in the jth row and ith column of weight matrix W • Consider a feedforward network with P inputs, Q hidden neurons, and M outputs • What should be the dimension for W from hidden to output layers? • W will have M rows and Q+1 columns. First column is for the bias inputs CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
Vector/Matrix Notation (2) • yj = output of the jth neuron (in a layer) • y = vector in which the jth element is yj • What should be dimension of y for the hidden layer? • y is a vector of length Q+1, where the first element is the bias input of -1 • What should be the dimension of y for the output layer? • y is a vector of length M. No bias input is needed since this is the last layer of the network. CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
BP Equation in Vector/Matrix Form • Delta rule Wj(n+1) = Wj(n) + ΔWj(n) where ΔWj(n) = η[δj(n)yi(n)T] outer product When logistic sigmoidal activation functions are used • δj(n) is given by (in the following, omit the bias elements from the vectors and matrices) • If j is the output layer δj(n) = yj(n)[1 – yj(n)].[dj(n) – yj(n)] • If neuron j lies in a hidden layer δj(n) = yj(n)[1 – yj(n)].Wk(n)Tδk(n) CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS
l W1 W2 -1 x0 = -1 1 x1 y1 Q yM xp Layer 1 Layer 2 CS/CMPE 333 - Neural Networks (Sp 2002/2003) - Asim Karim @ LUMS